
Python中的深拷贝和浅拷贝
python中的拷贝分为深拷贝和浅拷贝两种方式:
- 浅拷贝(shallow copy)指的是将一个对象的引用赋值给另一个变量,这样两个变量指向的是同一个对象,当其中一个变量修改这个对象时,另外一个变量也会受到影响。
- 深拷贝(deep copy)则是创建一个新的对象,新对象与原对象完全独立,两个对象互不影响。
字典的key能够使用数组吗
可以,但需要将数组转变为元祖进行存储。因为字典的key必须是唯一且不可变的。
简介TCP和UDP之间的区别
TCP协议全称是传输控制协议是一种面向连接的、可靠的、基于字节流的传输层通信协议,由IETF的RFC793定义。TCP是面向连接的、可靠的流协议。TCP提供超时重发,丢弃重复数据,检验数据,流量控制等功能,保证数据能从一端传到另一端。
UDP协议全称是用户数据报协议,在网络中它与TCP协议一样用于处理数据包,是一种无连接的协议。在OSI模型中,在第四层——传输层,处于IP协议的上一层。UDP有不提供数据包分组、组装和不能对数据包进行排序的缺点。由于UDP在传输数据报前不用在客户和服务器之间建立一个连接,且没有超时重发等机制,故而传输速度很快。
两者的区别:
1、TCP是面向连接的,UDP是面向无连接的;
2、UDP程序结构较简单;
3、TCP是面向字节流的,UDP是基于数据报的;
4、TCP保证数据正确性,UDP可能丢包;
5、TCP保证数据顺序,UDP不保证
python的内存如何进行管理
- 垃圾回收机制:python的垃圾回收机制通过引用技术实现。每个对象都有一个引用计数器,当引用计数为0时对象就会被回收。Python使用的是标记-清除算法,当一个对象被标记为垃圾时,就会被回收。Python还使用了分代回收机制,将对象分成不同的代,每个代使用不同的回收机制,以提高垃圾回收的效率。
- 内存池机制:Python还使用了内存池机制,来提高内存分配和释放的效率。内存池机制是指预先分配一定数量的内存块,当需要分配内存时,直接从内存池中取出内存块,当释放内存时,将内存块放回内存池中。这样做的好处是可以减少内存分配和释放的次数,提高内存使用效率。
- 循环引用:循环引用是指两个或多个对象相互引用,形成一个环。如果存在循环引用,就会导致内存泄漏,因为这些对象的引用计数永远不会变为0。Python使用了弱引用来解决循环引用的问题。弱引用是一种不增加对象引用计数的引用方式,当对象的引用计数为0时,弱引用也会被回收。
- 内存分配器:Python的内存分配器使用了多种算法,包括best fit、first fit和buddy system等。best fit算法是在空闲内存块中查找最小的合适内存块进行分配;first fit算法是在空闲内存块中查找第一个合适内存块进行分配;buddy system算法是将内存块分成大小相等的块,每个块的大小是2的n次方,当需要分配内存时,从大小最接近的块中分配内存。
进程间通信的方式有哪些
进程间通信的方式有:1、管道通常指无名管道,是UNIX系统IPC最古老的形式;2、FIFO,是一种文件类型;3、消息队列,是消息的链接表,存放在内核中;4、信号量,是一个计数器;5、共享内存。
- 管道:通常指无名管道,是 UNIX 系统IPC最古老的形式。
- 它是半双工的(即数据只能在一个方向上流动),具有固定的读端和写端。
- 它只能用于具有亲缘关系的进程之间的通信(也是父子进程或者兄弟进程之间)。
- 它可以看成是一种特殊的文件,对于它的读写也可以使用普通的read、write 等函数。但是它不是普通的文件,并不属于其他任何文件系统,并且只存在于内存中。
- FIFO:也称为命名管道,它是一种文件类型。
- FIFO可以在无关的进程之间交换数据,与无名管道不同。
- FIFO有路径名与之相关联,它以一种特殊设备文件形式存在于文件系统中。
- 消息队列:是消息的链接表,存放在内核中。一个消息队列由一个标识符(即队列ID)来标识。
- 消息队列是面向记录的,其中的消息具有特定的格式以及特定的优先级。
- 消息队列独立于发送与接收进程。进程终止时,消息队列及其内容并不会被删除。
- 消息队列可以实现消息的随机查询,消息不一定要以先进先出的次序读取,也可以按消息的类型读取。
- 信号量:信号量(semaphore)与已经介绍过的 IPC 结构不同,它是一个计数器。信号量用于实现进程间的互斥与同步,而不是用于存储进程间通信数据。
- 信号量用于进程间同步,若要在进程间传递数据需要结合共享内存。
- 信号量基于操作系统的 PV 操作,程序对信号量的操作都是原子操作。
- 每次对信号量的 PV 操作不仅限于对信号量值加 1 或减 1,而且可以加减任意正整数。
- 支持信号量组。
- 共享内存:共享内存(Shared Memory),指两个或多个进程共享一个给定的存储区。
- 共享内存是最快的一种 IPC,因为进程是直接对内存进行存取。
- 因为多个进程可以同时操作,所以需要进行同步。
- 信号量+共享内存通常结合在一起使用,信号量用来同步对共享内存的访问。
三次握手与四次挥手
-
第一次握手: 首先是客户端向服务器发送了报文:这次的握手是具有重大意义的:它说明了客户端它的发送能力是正常的
-
第二次握手:然后服务器端接收到了客户端向它发送的报文,并且也同时向客户端发送报文:这次的握手也很重要:它说明了服务器端自身的接收能力和发送能力都是正常的
-
第三次握手:客户端再一次向服务器发送了报文:这次的握手依旧重要:因为证明客户端的接收能力正常
-
第一次挥手: 客户端发出连接释放报文,并且停止发送数据。释放数据报文首部,FIN=1,其序列号为seq=u(等于前面已经传送过来的数据的最后一个字节的序号加1),此时,客户端进入FIN-WAIT-1(终止等待1)状态
-
第二次挥手:服务器端接收到连接释放报文后,发出确认报文,ACK=1,ack=u+1,并且带上自己的序列号seq=v,此时,服务端就进入了CLOSE-WAIT 关闭等待状态
-
第三次挥手:客户端接收到服务器端的确认请求后,客户端就会进入FIN-WAIT-2(终止等待2)状态,等待服务器发送连接释放报文,服务器将最后的数据发送完毕后,就向客户端发送连接释放报文,服务器就进入了LAST-ACK(最后确认)状态,等待客户端的确认。
-
第四次挥手:客户端收到服务器的连接释放报文后,必须发出确认,ACK=1,ack=w+1,而自己的序列号是seq=u+1,此时,客户端就进入了TIME-WAIT(时间等待)状态,但此时TCP连接还未终止,必须要经过2MSL后(最长报文寿命),当客户端撤销相应的TCB后,客户端才会进入CLOSED关闭状态,服务器端接收到确认报文后,会立即进入CLOSED关闭状态,到这里TCP连接就断开了,四次挥手完成
进程和线程的区别
- 根本区别:进程和线程的根本区别是进程是操作系统(OS)资源分配的基本单位,而线程是处理器(CPU)任务调度和执行的基本单位。
- 资源开销:每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换会有较大的开销;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小。
- 包含关系:如果一个进程内有多个线程,则执行过程不是一条线的,而是多条线同完成的;线程是进程的一部分,所行过程不是一条线的,而是多条线(线耗)其被称为轻权进程或者轻量级进程。
- 内存分配:同一进程的线程共享本进程的地址空间和资源,而进程之间的地址空间和资源是相互独立的。
- 影响关系:一个进程崩溃后,在保护模式下不会对其他进程产生影响,但是一个线程崩溃整个进程都死掉。所以多进程要比多线程健壮。
- 执行过程:每个独立的进程有程序运行的入口、顺序执行序列和程序出口。**但是线程不能独立执行**,必须依存在应用程序中,由应用程序提供多个线程执行控制,两者均可并发执行。
进程、线程、协程的概念
- 进程:是并发执行的程序在执行过程中分配和管理资源的基本单位,是一个动态概念,竞争计算机系统资源的基本单位。
- 线程:是进程的一个执行单元,是进程内科调度实体。比进程更小的独立运行的基本单位。线程也被称为轻量级进程。
- 协程:是一种比线程更加轻量级的存在。一个线程也可以拥有多个协程。其执行过程更类似于子例程,或者说不带返回值的函数调用。
何时使用多进程,何时使用多线程
对资源的管理和保护要求高,不限制开销和效率时,使用多进程。要求效率高,频繁切换时,资源的保护管理要求不是很高时,使用多线程。
在浏览器地址栏输入一个URL后回车,背后会进行哪些技术步骤?
- DNS解析:当用户在浏览器中输入URL时,浏览器会首先查找本地缓存中是否有该URL对应的IP地址。如果没有,则会向本地DNS服务器发送一个DNS查询请求。本地DNS服务器会检查自己的缓存,如果也没有找到,则会向其他的DNS服务器发起查询,直到找到对应的IP地址为止。一旦找到IP地址,本地DNS服务器就会将其返回给浏览器。
- 建立TCP链接:一旦浏览器获取到服务器的IP地址,它就会向该IP地址发送一个TCP连接请求。在建立TCP连接之前,浏览器会首先与服务器进行三次握手,以确保连接的可靠性。
- 发送HTTP请求:一旦TCP连接建立成功,浏览器就会向服务器发送HTTP请求。该请求包含了一些信息,如请求方式(GET、POST等)、请求头、请求体等。其中,请求头中包含了一些信息,如浏览器类型、支持的压缩格式、语言等等。
- 服务器处理请求并返回响应:服务器接收到浏览器发送的HTTP请求后,会进行处理,并生成一个HTTP响应。该响应包含了一些信息,如状态码、响应头、响应体等。其中,状态码表示服务器对请求的处理结果,常见的状态码有200(OK)、404(Not Found)、500(Internal Server Error)等等。 - 接收HTTP响应:一旦浏览器接收到服务器返回的HTTP响应,它就会进行一些处理。首先,它会解析响应头,以确定响应的类型、编码、长度等信息。然后,它会读取响应体,并根据响应的类型进行解析。
- 浏览器渲染页面:一旦浏览器接收到HTTP响应并解析出页面的HTML、CSS和JavaScript代码,它就会开始渲染页面。
- 执行JS代码。
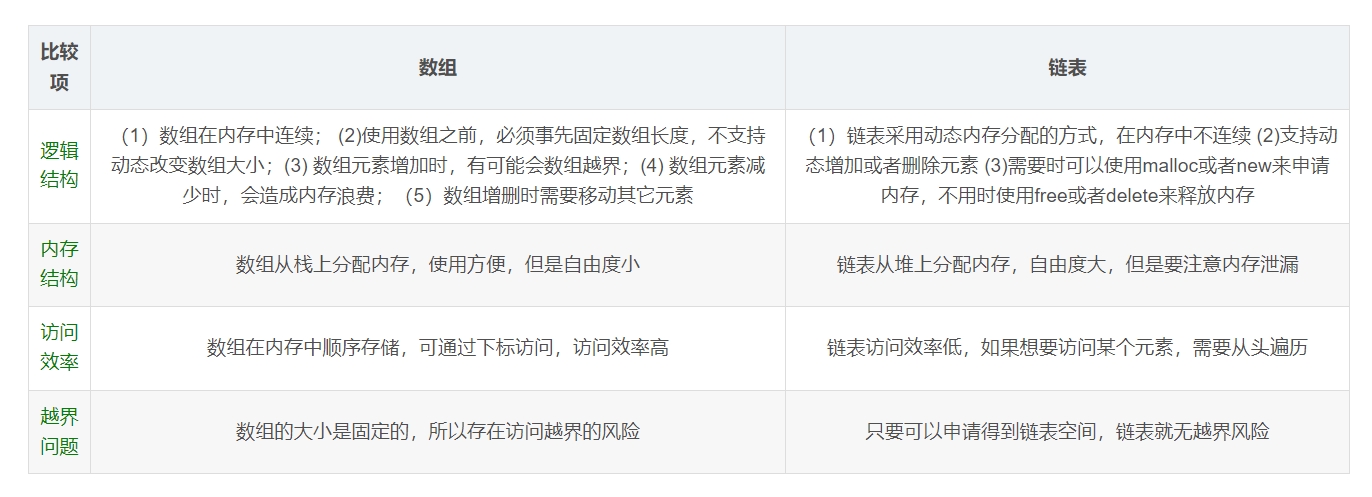
数组和链表的区别
数组是一组具有相同数据类型的变量的集合,这些变量称之为集合的元素。
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
Python的继承、封装和多态
封装
封装的目的
- 封装数据:保护隐私
- 封装方法:隔离复杂度(只保留部分接口对外使用)
封装的方式
- 公有属性和方法:公有属性和方法可以被类的外部访问和使用,不需要添加任何特殊符号。
- 私有属性和方法:
- 封装属性:__attr
- 封装方法:__func
- 以_开头的属性被视为受保护的属性,他们不应该在类外部被直接访问。但是,他们可以在类的子类和内部方法中被访问。
- 以__开头的属性被视为私有属性,即它们不应该在类的外部被访问。但是,它们也可以在类的内部方法中被访问。
- 属性装饰器和方法装饰器:
- @property装饰器用于定义属性的访问器,它会将属性定义为一个只读属性。当外部代码试图修改这个属性时,会触发一个AttributeError异常。
- @属性名.setter装饰器用于定义属性的修改器,它可以让外部代码修改这个属性的值。当外部代码试图读取这个属性时,会触发一个AttributeError异常
继承
python中的继承机制经常用于创建和现有类功能类似的新类,又或是新类只需要在现有类基础上添加一些成员(属性和方法),但又不想直接将现有类代码复制给新类。也就是说,当我们需要进行类的重复使用时,就可以使用这种继承机制来实现。
子类继承父类时,只需要在定义子类时,将父类(可以是多个)放在子类之后的括号内即可:
class 类名(父类1, 父类2, ...):
#类定义部分 如果一个类是空类,但是继承了含有方法和属性的类,那么这个类也同样含有父类的方法和属性:
class People:
def __init__(self,name):
self.name =name
def say(self):
print("People类",self.name)
class Animal:
def __init__(self):
self.name = Animal
def say(self):
print("Animal类",self.name)
#People类是Person父类中最近的父类,因此People中的name属性和say()方法会遮蔽 Animal 类中的
class Person(People, Animal):
pass
zhangsan=Person('张三')
zhangsan.say() # People类 张三可以看到,当 Person 同时继承 People 类和 Animal 类时,People 类在前,因此如果 People 和 Animal 拥有同名的类方法,实际调用的是 People 类中的;由此也可以看出,python支持多继承。
多态
python是一种动态语言,其最明显的特征就是在使用变量时,无需为其指定具体的数据类型。这会导致一种情况,即同一变量可能会被先后赋值不同的类对象。
多态可以简单理解为:具有多种形态 ,它指的是即便不知道一个变量所引用的对象到底是什么类型, 仍然可以通过这个变量调用方法; 在运行过程中根据变量所引用的对象的类型 , 动态的决定调用哪个对象中的方法。
HTTP和HTTPS的区别在哪里
HTTPS可以称之为HTTP的安全版本,于HTTP下加SSL(Secure Sockets Layer)层,HTTPS的安全基础是SSL,因此加密的详细内容就需要SSL。可以建立信息安全通道保护数据传输安全性以及确认网站真实身份。
简单说,HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全。
数字证书的原理是什么
数字证书的工作原理是公钥密码机制,简而言之就是通过“私钥签名、公钥验签”规则运行签名验签运算,保证电子文件内容不被篡改。公钥密码机制让数字证书具备了唯一性和私密性,因此,数字证书可以发挥网络身份识别和通讯信息加密的作用。
Comments NOTHING