
强化学习介绍
强化学习(英语:Reinforcement learning,简称RL)是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益。强化学习是除了监督学习和非监督学习之外的第三种基本的机器学习方法。与监督学习不同的是,强化学习不需要带标签的输入输出对,同时也无需对非最优解的精确地纠正。其关注点在于寻找探索(对未知领域的)和利用(对已有知识的)的平衡,强化学习中的“探索-利用”的交换,在多臂老虎机(英语:multi-armed bandit)问题和有限MDP中研究得最多。
其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。这个方法具有普适性,因此在其他许多领域都有研究,例如博弈论、控制论、运筹学、信息论、仿真优化、多智能体系统、群体智能、统计学以及遗传算法。在运筹学和控制理论研究的语境下,强化学习被称作“近似动态规划”(approximate dynamic programming,ADP)。在最优控制理论中也有研究这个问题,虽然大部分的研究是关于最优解的存在和特性,并非是学习或者近似方面。在经济学和博弈论中,强化学习被用来解释在有限理性的条件下如何出现平衡。
在机器学习问题中,环境通常被抽象为马尔可夫决策过程(Markov decision processes,MDP),下面就将介绍经典的马尔科夫决策过程及相应的动态规划算法。
马尔科夫决策过程与强化学习动态规划算法
马尔科夫决策过程(Markov Decision Process)可以认为是一个<S,A,P,r,\gamma>的五元组,其中:
- S是状态的集合
- A是动作的集合
- \gamma是折扣因子
- r(s,a)是奖励函数
- P(s'|s,a)是状态转移函数,表示在状态s执行动作a后转移到s'的概率。
定义状态价值函数为在当前状态及策略下,依据策略所选择的动作可以获得的期望奖励,并对之后的状态进行\gamma\textless1的折扣,这样做的目的主要有两点:
- 是为了表示当前状态的奖励比未来状态要重要。
- 是为了确保状态价值函数收敛。
此时可以写出状态价值函数(连续形式):
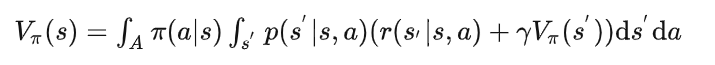
以及动作价值函数:
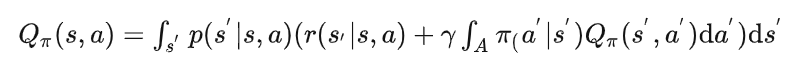
进一步可以写出最优状态价值函数(这里的最优状态价值函数与最优动作价值函数都是相对于策略而言的,即在该最优策略下所对应的状态价值函数(或动作价值函数)其在任意状态(状态动作对)下的值都不小于其他策略,此时就将最优策略下所对应的状态价值函数(动作价值函数)称为最优的):
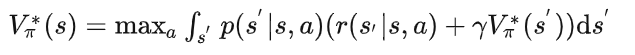
以及最优动作价值函数:
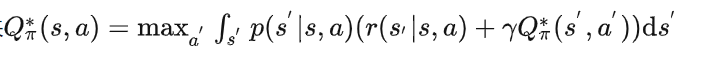
策略提升定理
策略提升定理是指:若有一个确定性策略\pi',在每个状态s选择价值最大的动作:
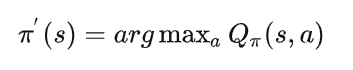
即在任意一个状态s下均有:
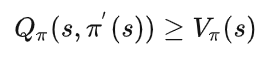
于是在任意状态s下均有:
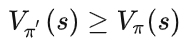
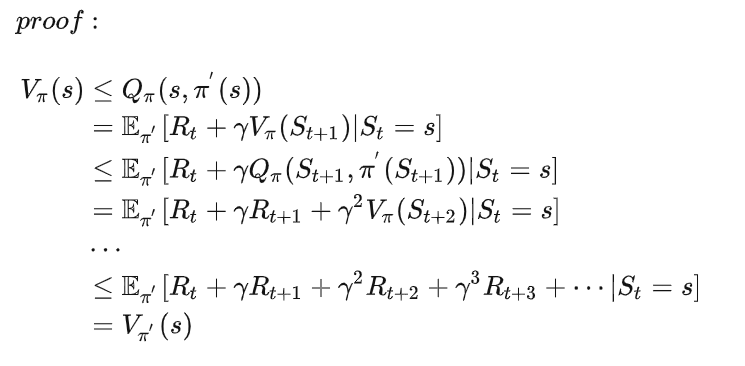
根据上述的策略提升定理可以得到下面的策略迭代算法。
有了上述的基础,接下来将介绍基于动态规划的强化学习,即策略迭代算法和值迭代算法。
策略迭代算法
策略迭代算法是广义策略迭代(generalized policy iteration,GPI)框架下的一种算法,广义策略迭代是指使用策略评估和策略改进相互作用的一种算法框架,几乎所有的强化学习算法都可以看成是GPI(包括策略迭代算法和值迭代算法)。
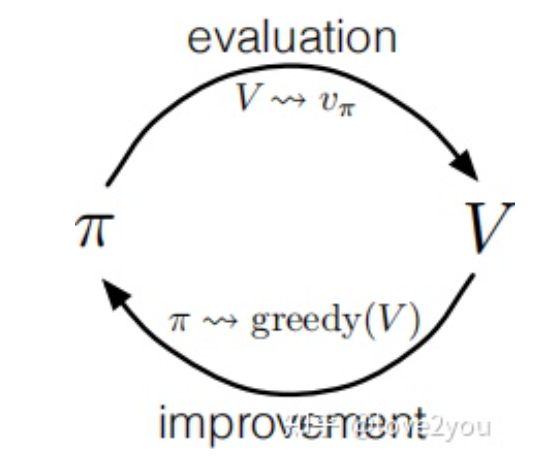
策略迭代算法伪代码:

策略迭代的过程可以用下图说明:
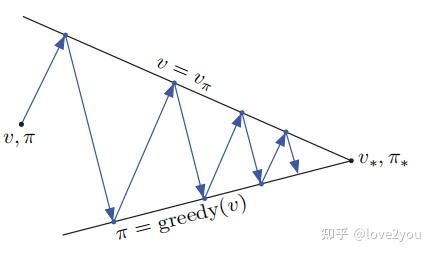
可以看到策略迭代算法就是一个策略评估和策略提升的过程,直到最后收敛到最优策略。
值迭代算法
由策略迭代算法的步骤二可知,我们需要执行很多轮策略迭代才能使策略的评估收敛,那么能不能省去这一步呢。试想一下这种情况,虽然状态价值函数没有收敛,但是策略所选择的动作却是同一个动作,即策略不发生改变。这就引入了接下来要介绍的算法,值迭代算法,值迭代算法直接对值函数进行操作,当然也可以看做是只进行了一次策略评估的策略迭代算法,其利用的是最优bellman方程:
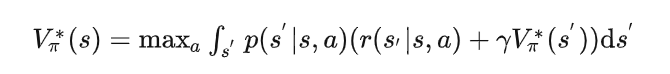
得到最优状态价值函数后,我们只需要利用:
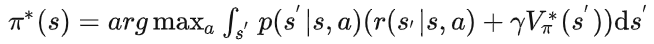
即可恢复最优策略(注意在价值迭代算法中并不存在显式的策略,但我们可以从最优状态价值函数中恢复最优策略,其收敛性如下),价值迭代算法伪代码如下:

Comments NOTHING