
摘要
我们推出DeepSeek-V3.2,该模型实现了高计算效率与卓越推理能力、智能体性能的协同统一。
其核心技术突破包括:
- DeepSeek稀疏注意力机制(DeepSeek Sparse Attention,DSA):一种高效注意力机制,在长上下文场景中大幅降低计算复杂度的同时,保持模型性能稳定;
- 可扩展强化学习框架:通过构建稳健的强化学习协议并扩大训练后计算规模,DeepSeek-V3.2性能比肩GPT-5;
- 大规模智能体任务合成流水线:为将推理能力融入工具使用场景,研发新型合成流水线,系统性生成大规模训练数据,支持可扩展的智能体训练后优化,显著提升复杂交互环境中的泛化能力和指令遵循稳健性。
引言
推理模型的发布(DeepSeek-AI, 2025; OpenAI, 2024a)标志着大语言模型(LLMs)发展的关键节点,推动可验证领域的整体性能实现跨越式提升。
此后,LLMs能力持续快速演进,但近几个月出现明显分化:
开源社区(MiniMax, 2025; MoonShot, 2025; 智谱AI, 2025)虽稳步推进,闭源专有模型(Anthropic, 2025b; DeepMind, 2025a; OpenAI, 2025)的性能增长轨迹却更为陡峭,导致两类模型的性能差距非但没有缩小,反而持续扩大,专有系统在复杂任务中展现出愈发显著的优势。
经分析,我们发现开源模型在复杂任务中存在三大关键短板:
- 架构层面:对标准注意力机制的过度依赖严重限制了长序列处理效率,成为可扩展部署和有效训练后优化的主要障碍;
- 资源分配层面:开源模型在训练后阶段的计算投入不足,制约了其在高难度任务上的表现;
- 智能体场景下:开源模型的泛化能力和指令遵循能力显著落后于专有模型,影响实际部署效果。
为解决这些核心局限,我们首先提出DSA高效注意力机制,大幅降低计算复杂度,在长上下文场景中仍保持模型性能;
其次,研发稳定可扩展的强化学习(RL)协议,支持训练后阶段的大规模计算扩展,该框架分配的训练后计算预算超预训练成本的10%,解锁了高级能力;
最后,提出新型流水线以强化工具使用场景中的泛化推理能力:首先通过DeepSeek-V3方法实现冷启动,将推理与工具使用统一到单一轨迹中;再进行大规模智能体任务合成,生成1800余个不同环境和85000余个复杂提示词,驱动RL过程,显著提升模型在智能体场景下的泛化能力和指令遵循能力。
DeepSeek-V3.2在多个推理基准测试中取得与Kimi-k2-thinking和GPT-5相当的性能,同时大幅提升开源模型的智能体能力。
作为智能体场景下极具成本效益的替代方案,DeepSeek-V3.2在显著降低成本的同时,大幅缩小了开源模型与前沿专有模型的性能差距。
值得一提的是,为突破开源模型在推理领域的边界,我们放宽长度限制,研发出DeepSeek-V3.2-Speciale,其性能与领先闭源系统Gemini-3.0-Pro(DeepMind, 2025b)持平,在2025年IOI、ICPC世界总决赛、IMO和CMO中均获金牌。
DeepSeek-V3.2 架构
DeepSeek稀疏注意力机制(DSA)
DSA是DeepSeekV3.2的架构核心,包含两个关键组件:
(1)闪电索引器(Lighting Indexer)
索引器通过计算查询tokenh_t和前序tokenh_s之间索引的分数来决定使用哪些token:
其中H^I是索引头的数量,ReLU激活函数的选择是为了提升吞吐量。索引器使用FP8精度,计算效率极高
(2)细粒度Token选择机制
基于索引分数,只检索top-k个key-value条目,然后计算注意力输出:
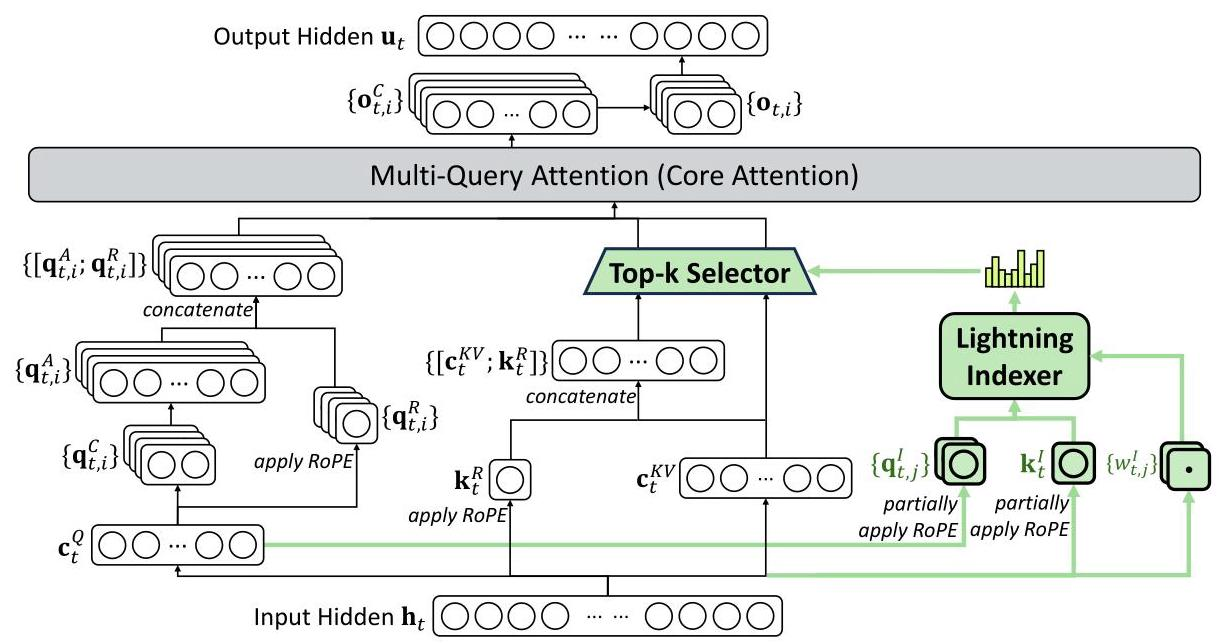
DSA的训练分为两个阶段:
- 密集预热阶段:冻结主模型参数,仅训练索引器1000步(21亿tokens),通过KL散度对齐索引器与主注意力分布
- 稀疏训练阶段:引入token选择机制,训练15000步(9437亿token),每个查询选择2048个key-valuetokens
Comments NOTHING