
简介
Transformer的核心部分是Attention注意力机制,通过引入Attention机制,模型能够处理序列数据的时候有效关注序列中的重点信息,而不依赖于固定的顺序或距离。
下图展示了Attention在NLP领域中的具体含义:如果考虑一个单词it的特征,那么它的特征将根据别的单词的特征加权得到,比如说the animal和it的关系比较近,那么the animal对应的权重值就会很高,从而影响下一层it的特征。

Self-Attention
自注意力机制通过计算输入序列中各个元素之间的相关性,来捕捉序列中不同位置之间的相互依赖关系。具体来说,Attention机制将序列中的每个元素同其他所有元素进行比较,从而判定哪些元素对于当前元素的输出最为重要。自注意力机制的计算过程包括:
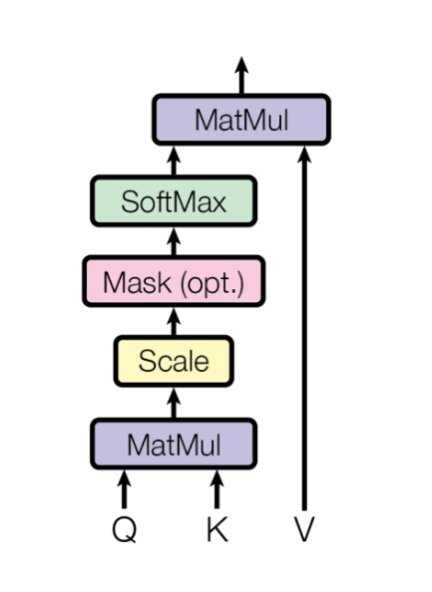
1、计算Q、K和V矩阵:
其中,X是输入序列,维度为(N,d),其中N是序列的长度,d是每一个序列的特征维度。W^Q、W^K、W^V是需要被训练的权重矩阵,维度为(d,d')。变换后,查询Q、键K和指V的维度都是(N,d'),一般来说,d'和d取值相同,均为模型的隐藏层维度。
2、计算自注意力矩阵,然后求关联度
自注意力矩阵的表达式为:
使用点积计算查询Q和键K之间的相似度,因此,A的维度是(N,N)
关联度的计算方法为:
此处通过Softmax对计算结果进行归一化,得到注意力权重。值得注意的是,在计算关联度时,需要做scale的操作,除\sqrt{d_k},从而防止点积过大,保持Softmax稳定。
3、加权求和,得到自注意力输出
最终output的输出维度为 (N,d')
Multi-Head Attention
多头注意力机制(Multi-head Self-attention, MHA)是自注意力机制的进阶,同时也是transformer架构的核心组件之一。通过加入注意力头,多头注意力机制允许模型在不同的表示子空间中并行学习,从而提高模型对于不同特征的捕捉能力,提升模型性能。
在MHA中,每一个“头”可以看作是在不同的表示子空间中进行注意力计算,从而使得每个头能够提取到输入序列的不同特征。例如,在NLP任务中,某个头可能专注于句法结构,另外一个头有可能专注于提取语义内容等。
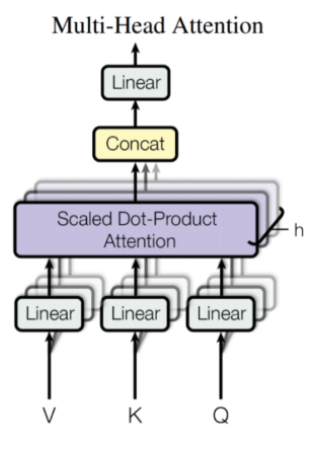
1、计算Q、K和V
计算方法与Self-Attention相同:
2、分割头
将Q、K分割成H个头,每个头的维度是\frac{d}{H},通过矩阵重排实现:
其中,Q_i、K_i和V_i
是第i个head头的查询矩阵、键矩阵和值矩阵,经过分割后,Q、K和V的维度是(N,H,\frac{d}{H})
3、计算注意力矩阵,求关联度
分别计算每一个head的注意力分数,求关联度:
4、加权求和
5、拼接头的输出,并经过线性层获得最终输出
将所有的head头的输出进行拼接:
最后,通过一个线性层W_o对拼接的输出进行投影,以得到最终的多头注意力输出:
Multi-Query Attention
多查询注意力机制是对多头注意力机制的改进,旨在减少模型的参数数量和计算复杂度,同时保持或提高模型的性能。与多头注意力机制不同,在MQA中,所有的Query共享同一组键和值,但每个Qeury可以有不同的权重。这种方法减少了需要存储的键和值的质量,同时仍然允许通过多个查询来捕捉不同子空间的特征。
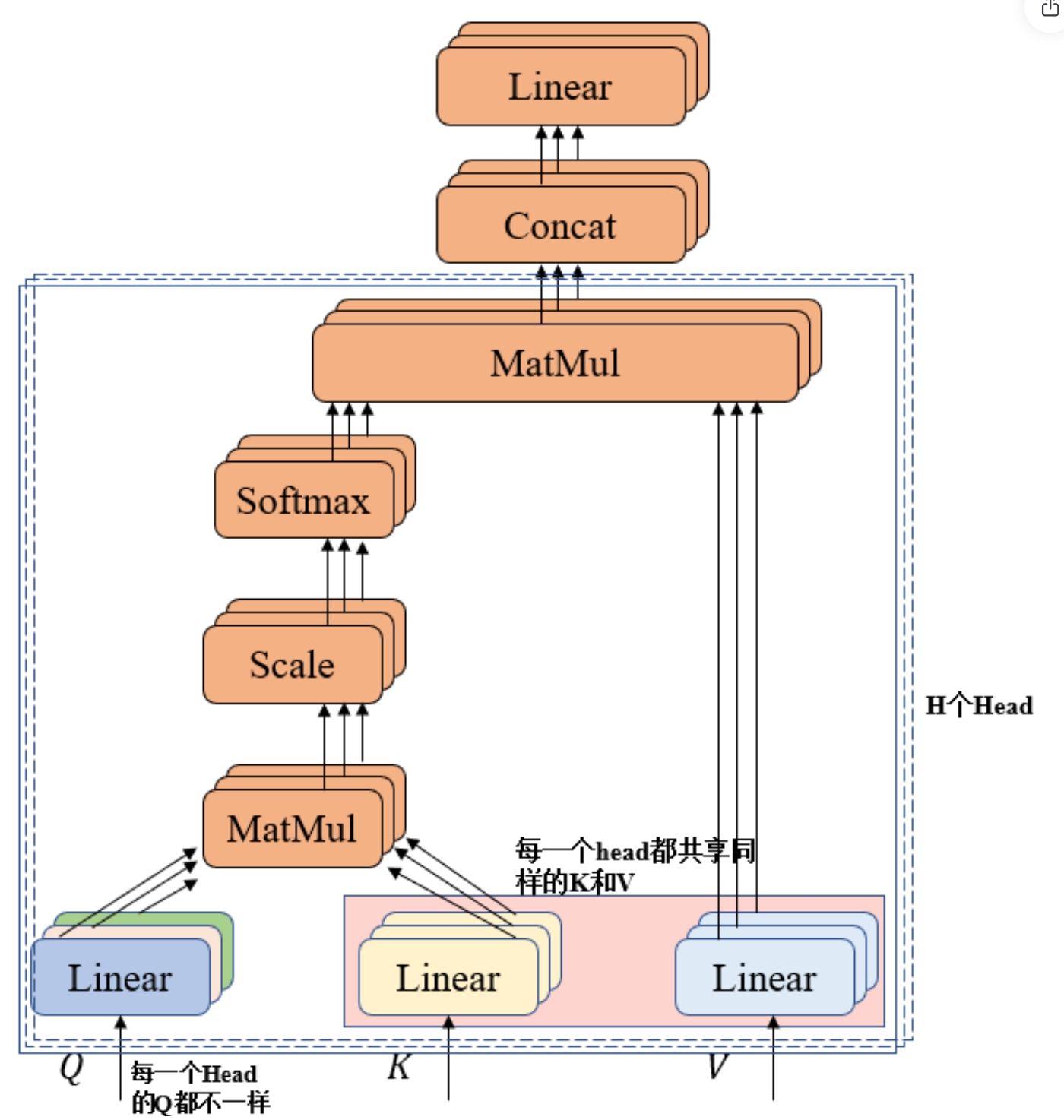
1、计算Q、K和V
其中X是输入序列,维度为(N,d),其中N是序列的长度,d是每个元素的特征维度。W^Q、W^K和W^V是需要被训练的权重矩阵
2、分割头
将Q、K和V分割成h个头,每个头的维度是\frac{d}{h},通过矩阵重排实现:
其中,Q_i是第i个head头的查询矩阵。此处的计算步骤与MHA的计算过程是完全相同的。
在MQA中,键和值得矩阵是共享的,模型参数数量减少,从而达到减少内存占用并加快推理速度的目的。然而,共享键和值矩阵可能会限制模型捕获不同头之间信息的能力,因此在某些情况下可能会牺牲性能。
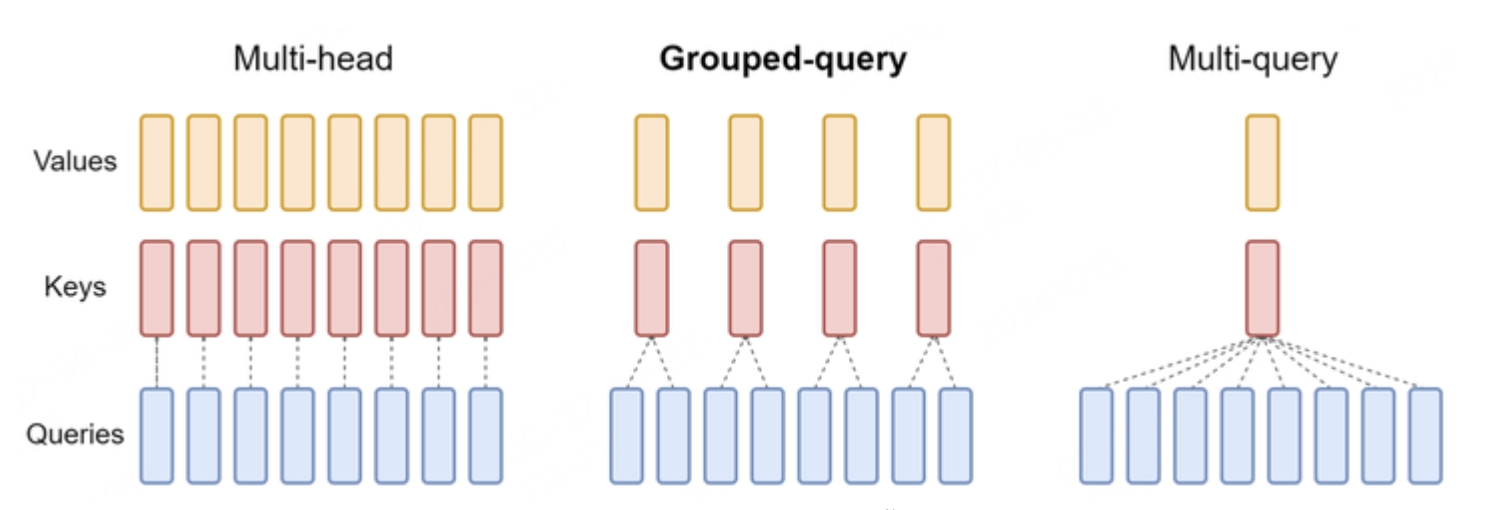
Grouped Query Attention
分组查询注意力机制进一步优化了注意力计算,通过将查询向量分组,使每个组共享一个键和值。与多查询注意力机制类似,GQA降低了计算复杂度,减少了内存占用,并且通过分组方式保留了模型的表示能力:
1、计算Q、K和V
2、按组分割查询矩阵Q
将查询矩阵Q分割成G个组,每个组包含\frac{H}{G}个头,得到G[katex]个查询子矩阵[katex]Q_1,Q_2,…,Q_G[katex]</p>
<p>**3、计算注意力矩阵,然后求关联度**
分别计算每一个组[katex]i的关联度,
4、加权求和
对于第i个组,输出结果为:
5、拼接头的输出,并经过线性层获得最终的输出
将所有头的输出进行concat
最后,通过一个线性层W_o对拼接的输出进行投影,以得到最终的多头注意力输出:
GQA能够在效率和质量之间寻求平衡,适用于需要处理大量数据和保持快速响应的场景中。然而,他也要在实现和性能上进行仔细的权衡。
总结
| 注意力机制 | 核心机制 | 核心差异 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|---|---|
| MHA(多头注意力) | 将Q、K、V通过线性映射分解为多个并行注意力头,每个头部拥有独立的Q、K、V参数,独立计算注意力分数后拼接输出 | 无参数共享,无任何压缩策略,每个头完全独立建模 | 1. 多头独立建模能捕捉丰富的语义特征和多维度依赖关系,表达能力极强;2. 技术成熟稳定,在多任务和多模态场景中表现优异;3. 无需复杂参数调优,适配多数基础Transformer任务 | 1. 内存复杂度达O(h·d),参数量和显存占用极高,长序列任务中易出现内存瓶颈;2. 计算复杂度呈平方增长,推理速度慢,部署成本高 | 1. 中小规模模型的高精度任务,如机器翻译、文本摘要等;2. 对模型性能要求高于部署效率的学术研究和基础模型训练 |
| MQA(多查询注意力) | 所有查询头保持独立,全局共享同一组K、V参数,仅通过独立查询头捕捉部分特征子空间信息 | K/V全局共享实现参数压缩,舍弃头间独立的K/V特征 | 1. 大幅减少K/V参数数量和KV缓存占用,内存复杂度低至O(d);2. 推理速度极快,较MHA吞吐量可提升30%-50%;3. 模型结构简化,部署成本低 | 1. 过度共享K/V导致上下文信息捕捉能力下降,模型精度有明显损失;2. 训练过程中模型稳定性差,容易出现收敛波动 | 1. 内存受限的长序列快速推理场景,如实时文本生成接口;2. 对精度损失容忍度较高的轻量化部署场景,如移动端简单对话模型 |
| GQA(分组查询注意力) | 把查询头划分为若干组,每组内共享一组K、V参数,组间K、V相互独立,兼顾分组独立性与共享性 | K/V分组共享完成参数压缩,通过组数调节共享程度 | 1. 可通过调节分组数量灵活平衡性能与效率,组数等于1时等效MQA,等于头数时等效MHA;2. 推理速度接近MQA,同时性能逼近MHA,T5-XXL实验中延迟降低50%且精度损失小于1%;3. 训练和推理稳定性优于MQA | 1. 分组数量为超参数,需针对不同任务反复调试以适配;2. 相比MQA,参数共享程度降低,极端场景下的内存优势略弱 | 1. 大模型的工业化部署,如LLaMA-2、ChatGLM2等大模型的推理优化;2. 兼顾用户体验和部署成本的场景,如智能客服、内容生成平台 |
| MLA(多头潜在注意力) | 通过低秩投影将输入映射到低维潜在空间,对Q、K、V进行矩阵分解压缩,搭配解耦旋转位置编码优化特征捕捉 | 低秩矩阵分解实现参数压缩,借助潜在空间降低计算负荷 | 1. 低秩分解可将参数规模大幅压缩,如r=64时可压缩16倍,KV缓存量仅为MHA的1/10;2. 长序列建模(10k tokens以上)时计算速度较MHA提升4-8倍;3. 解耦位置编码减少头部间干扰,保持较好的特征捕捉精度 | 1. 训练初期收敛速度较慢,需要适配潜在空间的参数学习;2. 潜在空间的维度设计对性能影响极大,需专业调优,适配场景有一定局限性 | 1. 10k tokens以上的超长序列建模任务,如长文档分析、视频帧序列处理;2. 资源受限的边缘设备部署,如嵌入式AI推理场景 |
Comments NOTHING