
Meta Data
- 发表时间:2025-02-24;最新 arXiv 修订:2026-04-08
- 作者:Penghui Yang, Cunxiao Du, Fengzhuo Zhang, Haonan Wang, Tianyu Pang, Chao Du, Bo An
- 论文链接:https://arxiv.org/pdf/2502.17421.pdf
- 项目链接:https://github.com/sail-sg/LongSpec
LongSpec:面向长上下文的无损推测解码,通过高效草稿生成与验证实现加速
摘要
随着大语言模型(Large Language Models, LLMs)现在能够处理极长上下文,在这些扩展输入上的高效推理变得越来越重要,尤其是对于 LLM agents 等高度依赖这一能力的新兴应用。与量化和模型级联等有损替代方案相比,推测解码(Speculative Decoding, SD)提供了一种很有前景的无损加速技术。然而,大多数最先进的 SD 方法是在短文本上训练的(通常少于 4k tokens),这使它们不适合长上下文场景。具体来说,将这些方法适配到长上下文会面临三个关键挑战:(1)由于大型 Key-Value(KV)缓存,草稿模型会带来过高的内存需求;(2)短上下文训练与长上下文推理之间的不匹配会导致性能下降;(3)在管理长 token 序列时,树注意力机制效率低下。本文提出了 LongSpec,这是一个通过三项核心创新来解决这些挑战的框架:具有常数大小 KV 缓存的内存高效草稿模型;缓解训练-推理不匹配的新型位置索引;以及一种将快速前缀计算与标准树注意力结合起来、从而实现高效解码的注意力聚合策略。实验结果证实了 LongSpec 的有效性:在五个长上下文理解数据集上,相比强大的 Flash Attention 基线,最高实现 3.26\times 加速;同时,在使用 QwQ 模型的四个数学推理任务上,墙钟时间减少 2.34\times,展示出面向长上下文应用的显著延迟改进。
引言
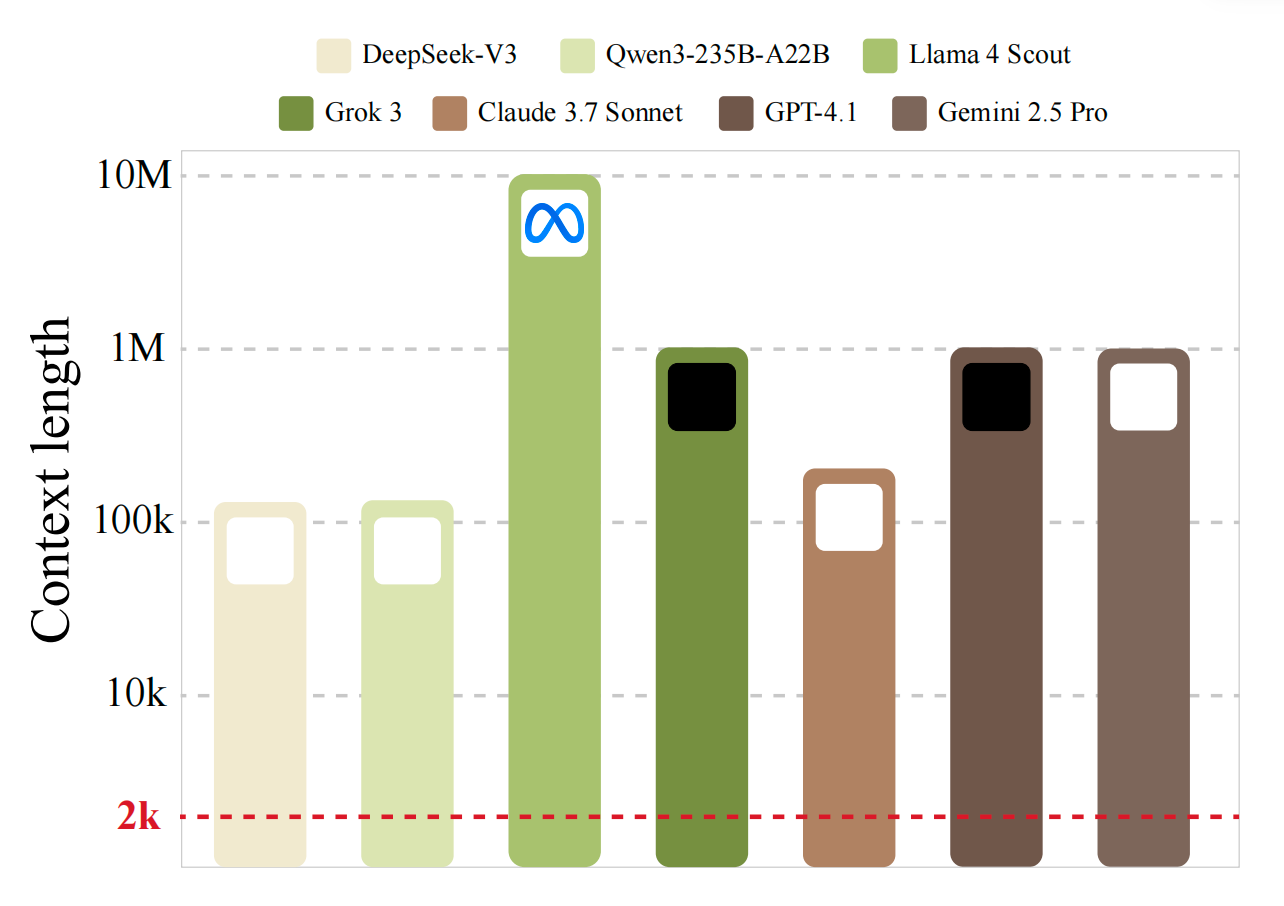
大语言模型(LLMs)已经展示出卓越能力,而它们处理扩展上下文的能力正在成为 LLM agents 和长推理任务等新兴应用的关键能力,这些应用现在运行在可扩展到数百万 tokens 的上下文窗口之上。在这些要求很高的长上下文场景中,标准自回归解码的高推理延迟会成为明显瓶颈。虽然量化、稀疏注意力和模型级联等多种加速技术已经被提出用于缓解这一问题,但它们往往会牺牲输出质量,因此属于有损方案。相比之下,推测解码(SD)通过使用一个更小的草稿模型来提出 token 序列,再由更大的目标模型并行验证这些序列,从而提供一种无损加速策略。
然而,最先进的 SD 方法(例如 EAGLE)通常依赖一个小型且独立的草稿模型,主要面向短上下文数据进行设计和评估,典型序列长度少于 4k tokens。虽然一些现有 SD 方法可以扩展到更长上下文,但它们通常使用完整目标模型并配合压缩的 Key-Value(KV)缓存作为草稿模型。这些方法避免了训练专用草稿模型的开销,但它们依赖完整目标模型,而完整目标模型并不够轻量,这限制了草稿生成速度。因此,这些方法可能不如最先进的短上下文 SD 技术表现好。
这种差异提出了一个关键问题:
对于这个问题,我们将有效短上下文 SoTA SD 技术难以直接适配到长上下文设置归因于三个新出现的挑战:
- 架构: 在 SoTA SD 方法中(例如 EAGLE),草稿模型的 KV cache 仍然会随上下文长度线性增长。随着上下文长度增加,这种线性增长会成为难以承受的内存瓶颈。
- 训练: 语言模型训练通常依赖大量短序列数据,而长序列数据相对稀缺。训练数据的不平衡使模型难以泛化到更长上下文。为了解决这一点,训练长上下文 LLM 的传统经验通常采用长度外推,尤其是通过扩展 Rotary Position Embedding(RoPE)的 base 来容纳更长上下文。然而,这一方案不能直接应用到 SoTA SD 草稿模型,因为它们的 RoPE base 必须与目标模型匹配;而目标模型的 RoPE base 是固定的,并且已经为长上下文场景进行了缩放。SoTA SD 技术通常要求草稿模型使用来自目标模型的中间特征(例如 hidden states 或 KV cache),这些信息对于让草稿模型更好地对齐并预测目标模型输出非常关键。
- 推理: 树注意力验证在长上下文场景中的有效性会下降。尤其是,长上下文场景中的常见推理优化主要面向规则、结构化的 attention mask 设计,并没有针对任意或非结构化 attention mask 优化。因此,推测可能带来的潜在加速低于预期。
为解决这些挑战,我们提出 LongSpec,一个用于高效长上下文无损推测解码的综合框架。 LongSpec 通过三项关键创新克服上述障碍:
- 内存高效架构。 我们提出一种无论上下文长度如何都保持常数内存使用量的草稿模型架构,从而有效解决已有 SoTA 自回归草稿模型的可扩展性限制。
- 有效训练机制。 我们开发了一种涉及 Anchor-Offset Indices 的新型训练策略,使在短序列上训练的草稿模型能够在推理时稳健地泛化到长得多的上下文。
- 快速树注意力。 我们提出 Hybrid Tree Attention,这是一种新的计算方法,通过分解注意力计算并利用优化的 Triton kernels,显著加速树验证。
在使用五个 LLM 作为目标模型、覆盖五个长上下文理解数据集的实验中,我们的 LongSpec 能够显著降低长上下文推理延迟:相比使用 Flash Attention 的强基线最高实现 3.26\times 加速;相比使用 HuggingFace 实现的常见基线最高实现 7\times 加速。在使用长推理模型 QwQ 的四个数学推理数据集上的额外实验进一步验证了 LongSpec 的有效性,墙钟时间加速达到 2.34\times。此外,我们提出的 Anchor-Offset Indices 使模型达到相同 loss 水平的速度提升 3.93\times,而 Hybrid Tree Attention 相比标准 HuggingFace 实现将注意力计算延迟降低约 75%。
相关工作
推测解码提供了一种在不损害 LLM 输出质量的情况下加速 LLM 的有前景方法。本文关注原始的无损推测解码方法;一些近期工作探索了有损推测解码,附录中给出简要概览。早期工作依赖现有小型 LLM 来生成草稿序列。另一些方法则试图改进这些早期方案。也有一些工作使用目标模型的一部分作为草稿模型。基于检索的推测解码方法则通过使用 N-gram 匹配而不是依赖小模型来提供另一种替代方案。这些方法绕开了额外模型训练需求,利用已有数据模式高效构造草稿序列。
更近期的进展在这些基础上进行了扩展:它们设计专用草稿模型,并引入树推测与验证技术。这些方法利用为推测解码定制的草稿模型,实现更高效率和性能。此外,这些方法采用的基于树的方案允许更自适应、更易并行的解码过程,为视觉-语言模型等真实系统中的更广泛应用铺平道路。
尽管推测解码在常规上下文长度上已经取得显著进展,但只有少数现有论文关注长上下文场景中的无损推测解码。TriForce 引入了一个可扩展到长序列生成的三层推测解码系统。MagicDec 使用推测解码同时提升 LLM 推理吞吐和延迟。QuantSpec 对草稿模型采用分层 4-bit 量化 KV cache 和 4-bit 量化权重。然而,这些方法主要使用带稀疏 KV cache 的目标模型作为草稿模型。计算密集型草稿模型限制了这些方法在不同 batch size 下的实际使用。相比之下,我们的工作关注如何高效构建一个仅包含一个 transformer block 的草稿模型,从而在不同场景中实现更有效的性能。
方法
在本节中,我们介绍用于长上下文推测解码的 LongSpec 框架。它通过以下三点解决三个关键挑战:(1)设计一个具有常数大小内存开销的轻量草稿模型架构;(2)设计带 anchor-offset indices 的训练策略,以有效处理长上下文;(3)实现一种快速注意力聚合机制,利用基于树的推测与验证来支持实际使用。
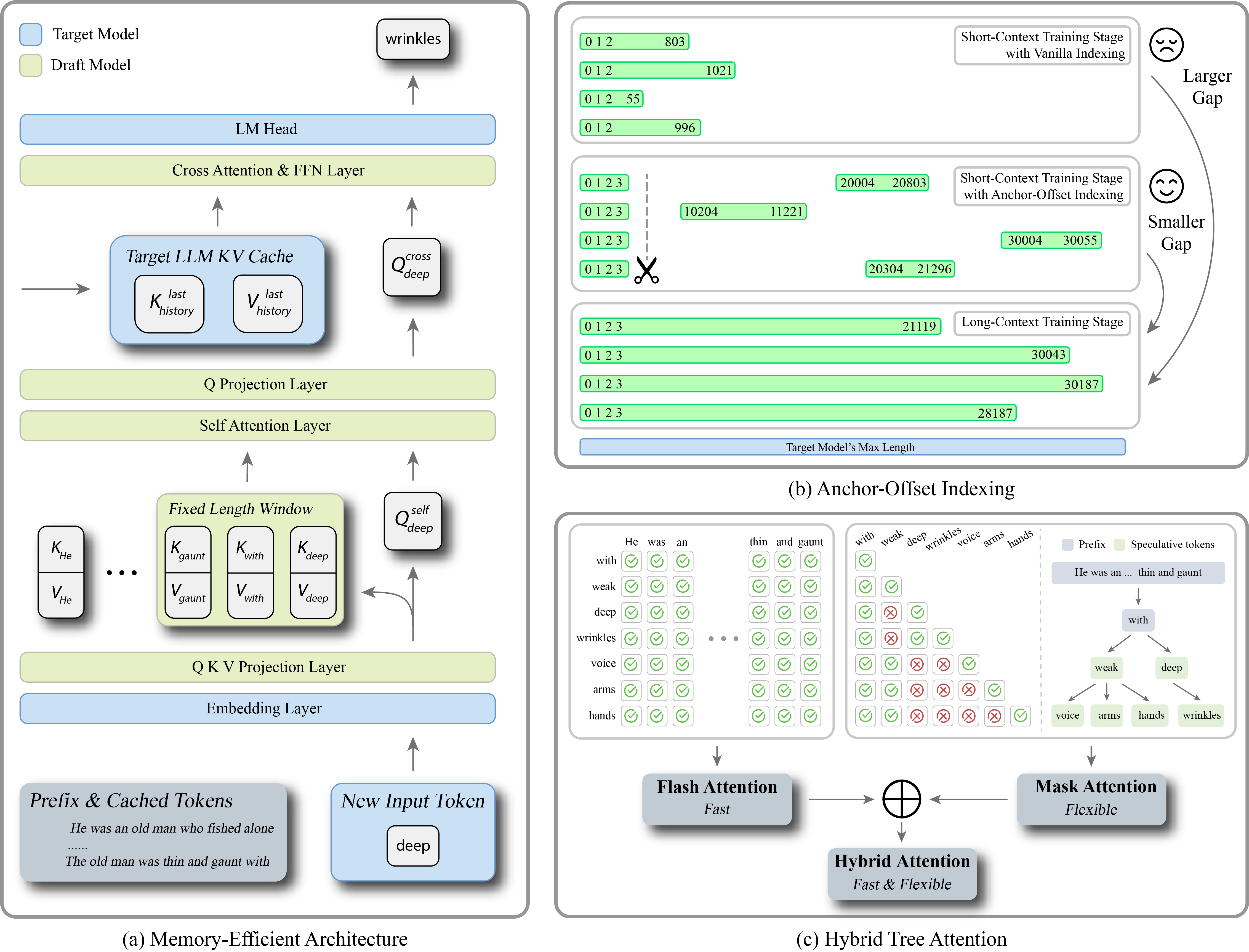
Flash Attention 与我们基于 Triton 实现的 Attention 的优势。内存高效架构
在先前工作中,SoTA 模型 EAGLE 的成功依赖两个关键因素:(1)目标模型提供的 hidden states;(2)它的自回归结构。然而,自回归草稿模型不可避免地需要维护自己的 KV cache,这会在长上下文推理期间引入额外开销,并需要大量 GPU 内存,尤其是在 LLM agents 和长推理等会产生大量输出的任务中。
为避免这种额外内存开销,我们提出一种内存使用量与上下文长度无关、保持常数的草稿模型。如图 2(a)所示,我们的模型由两个组件构成:self-attention 模块,以及其后的 cross-attention 模块。self-attention 模块专注于建模局部上下文,而 cross-attention 模块捕获长程依赖。为限制内存使用,我们对 self-attention 模块应用滑动窗口注意力机制,这是现代 LLM 中广泛采用的技术。因此,在推理期间,self-attention 不会超过窗口大小;本文将窗口大小设为 512。
对于 cross-attention 组件,受 GliDe 启发,我们利用目标模型的 KV cache。该设计不仅使模型能更好地建模历史信息,还完全消除了长上下文的额外存储开销,因为无论是否采用推测解码,大模型的 KV cache 都必须被存储。不同于 GliDe,我们还在目标模型与草稿模型之间共享 Embedding Layer 和 LM Head 的权重,这显著降低了 LLaMA-3(词表大小 128,256)和 Qwen-2.5(词表大小 152,064)等大词表 LLM 的内存消耗。
有效训练机制
Anchor-Offset Indices。 使用 vanilla position indices 时,位置索引由从 0 开始的连续整数组成,序列中较早出现的索引会比较大的位置索引出现得更频繁,如图 2(b)上半部分所示。因此,较大的位置索引获得的训练更新不足,从而导致训练-推理差异。正如我们在引言中指出的,常见的基于 RoPE 的外推不能直接在这里使用,因为一旦目标模型被选定,RoPE base 就固定了。为利用目标模型的 KV cache,草稿模型必须保持与目标模型相同的 RoPE base。
为应对这一挑战,我们只能利用精心设计的索引。这些索引必须确保:(1)草稿模型中的位置索引能够用短上下文数据得到充分训练;(2)这些索引不会让目标模型表现出分布外行为,因为训练期间目标模型与草稿模型共享相同索引。
为满足这些约束,我们提出 Anchor-Offset Indices 策略。具体来说,我们将前四个位置 [0,1,2,3] 保留为 attention sink tokens;随后将所有 token 分配到从随机 offset 开始的大型连续索引上,例如 [0,1,2,3,8192,8193,8194,\dots]。根据 attention sink 现象,LLM 在处理长文本时,注意力权重主要集中在前四个 token 和最近 token 上。利用这一现象,我们认为 Anchor-Offset Indices 能自然地引导目标模型表现出分布内行为。anchor indices 与随机 offset 确保每个位置索引都能得到充分训练,解决 vanilla 方法反复只训练较小索引的问题。在实验中,在目标模型中采用这些索引只会使 loss 增加约 0.001,说明目标模型确实非常适合这种改变。伪代码见附录。
Flash Noisy Training。 在训练期间,草稿模型利用来自大模型的 KV cache;但在推理期间,这个 KV cache 并不总是可见。这是因为大模型只有在验证完成时才更新其 KV cache。具体来说,对于草稿模型中的第 t 个 cross-attention query Q_t,我们只能保证访问满足下式的对应 key-value states K_{\lt t^{\prime}}、V_{\lt t^{\prime}}:
1\le|t^{\prime} - t|\lt \gamma其中 \gamma 是推测步数。
为确保训练与推理一致,一个直接方案是添加 attention mask。然而,这种方法与 Flash Attention 不兼容,会显著降低训练速度,并造成不可接受的内存开销,尤其是在长上下文训练场景中。因此,我们提出一种称为 flash noisy training 的技术。在训练期间,我们以 1 \le j \lt \gamma 随机移动 queries 与 key-value states 的索引。假设序列长度为 l,则计算:
通过这种方式,我们有效模拟了推理阶段相同的可见性约束,即 1\le|t^{\prime} - t|\lt \gamma,从而对齐训练时行为与推理行为。使用 Flash Noisy Training 时,我们观察到 acceptance length 相比不使用它训练时提升 14.7%,提升最集中在最后的推测 tokens 上。这突出了它在缓解训练-推理 gap 中的作用。伪代码见附录。
快速树注意力
Tree Speculative Decoding 利用 speculation trees 和 LLM 的因果结构,使草稿模型能够提出多个候选序列,而目标模型只需验证一次,并且不会改变最终结果。在这个过程中,Tree Attention 在确保正确性与效率方面发挥关键作用。早期工作将由 prefix trees 得到的 attention masks 应用于 QK^\mathsf{T} attention matrix,从而禁用推测 tokens 之间的错误组合。然而,这些方法只能运行在 PyTorch eager execution mode 上,无法使用 Flash Attention 等更先进的 attention kernels。因此,随着序列长度增加,推理速度会显著下降。
为解决这些性能瓶颈,我们提出 Hybrid Tree Attention 机制,如图 2(c)所示。我们的方法基于两个关键观察:(1)执行 Tree Attention 时,queries 与缓存的 key-value pairs \{K_{\mathrm{cache}}, V_{\mathrm{cache}}\} 不需要额外 masks;(2)只有 queries 与来自当前 speculative tokens 的 key-value pairs \{K_{\mathrm{specs}}, V_{\mathrm{specs}}\} 需要 masking,而这类 speculative tokens 的数量通常较小。基于这些观察,我们采用 divide and aggregate 方法,将 attention 计算拆成两部分,并在之后合并。
拆分 Key-Value Pairs。 我们将所有 key-value pairs 分成两组:\{K_{\mathrm{cache}}, V_{\mathrm{cache}}\},即主序列的缓存部分,不需要 attention mask;以及 \{K_{\mathrm{specs}}, V_{\mathrm{specs}}\},即推测阶段部分,需要 attention masks。对于 \{K_{\mathrm{cache}}, V_{\mathrm{cache}}\},我们调用高效的 Flash Attention kernel。对于 \{K_{\mathrm{specs}}, V_{\mathrm{specs}}\},我们使用自定义 Triton kernel fused_mask_attn,它在 KV 维度中应用 blockwise loading 与 masking,从而实现快速 attention 计算。该步骤产生两组 attention outputs \{O_{\mathrm{cache}}, O_{\mathrm{specs}}\},以及它们对应的 denominators(即所有 attention scores 的 log-sum-exp)\{\mathrm{LSE}_{\mathrm{cache}}, \mathrm{LSE}_{\mathrm{specs}}\}。
聚合。 然后我们通过 log-sum-exp trick 将这两部分合并成最终 attention output O_{\mathrm{merge}}。首先计算:
\begin{aligned} \mathrm{LSE}_{\mathrm{merge}} &= \log\Bigl(\exp\bigl(\mathrm{LSE}_{\mathrm{cache}}\bigr) + \exp\bigl(\mathrm{LSE}_{\mathrm{specs}}\bigr)\Bigr), \end{aligned}然后对两个 outputs 应用加权求和:
\begin{aligned} O_{\mathrm{merge}} =\; &O_{\mathrm{cache}} \cdot \exp\bigl(\mathrm{LSE}_{\mathrm{cache}} - \mathrm{LSE}_{\mathrm{merge}}\bigr)\\ +\; &O_{\mathrm{specs}} \cdot \exp\bigl(\mathrm{LSE}_{\mathrm{specs}} - \mathrm{LSE}_{\mathrm{merge}}\bigr). \end{aligned}理论保证见附录。如上所述,这种 hybrid 方法在长序列推理的大部分计算中使用高度高效的 Flash Attention kernel,并且只对少量 speculative tokens 使用自定义 masking attention fused_mask_attn。kernel fused_mask_attn 遵循 Flash Attention 2 的设计哲学,将 Q、K_{\text{specs}} 与 V_{\text{specs}} 拆分成小 block。该策略减少全局内存 I/O,并充分利用 GPU streaming multiprocessors。此外,在计算 QK_{\text{specs}}^\top 的每个 block 时,mask matrix 会被加载并用于应用 masking 操作。Hybrid Tree Attention 在多个分支的并行验证与更高推理速度之间实现了有效平衡,同时不损害正确性。
实验
设置
目标模型与草稿模型。 我们选择四类广泛使用的长上下文 LLM 作为目标模型:Vicuna(包括 7B 和 13B)、LongChat(包括 7B 和 13B)、LLaMA-3.1-8B-Instruct,以及 QwQ-32B。为使草稿模型与目标模型更加兼容,我们的草稿模型在多种参数上与目标模型保持一致,例如 KV heads 数量。
训练过程。 我们首先在 SlimPajama-6B 预训练数据集上使用 Anchor-Offset Indices 训练草稿模型。对于 Vicuna 模型和 LongChat-7B,random offset 设为 0 到 15k 之间的随机整数;对于另外三个模型,由于它们最大上下文长度更长,random offset 设为 0 到 30k。然后我们在 Prolong-64k 长上下文数据集的一个小子集上训练模型,以获得处理长文本的能力。最后,我们在自建长上下文 supervised-finetuning(SFT)数据集上微调模型,以进一步提升模型性能。后两个阶段的位置索引采用 vanilla indexing policy,因为训练数据已经足够长。我们在所有三个阶段都应用 flash noisy training,以缓解训练与推理不一致问题,并且 flash noisy training 的额外开销可以忽略。更多模型训练细节见附录。
Flash Attention。加速比统计的是相对 Vanilla HF 方法的加速比例。所有结果均在 T=0 下计算。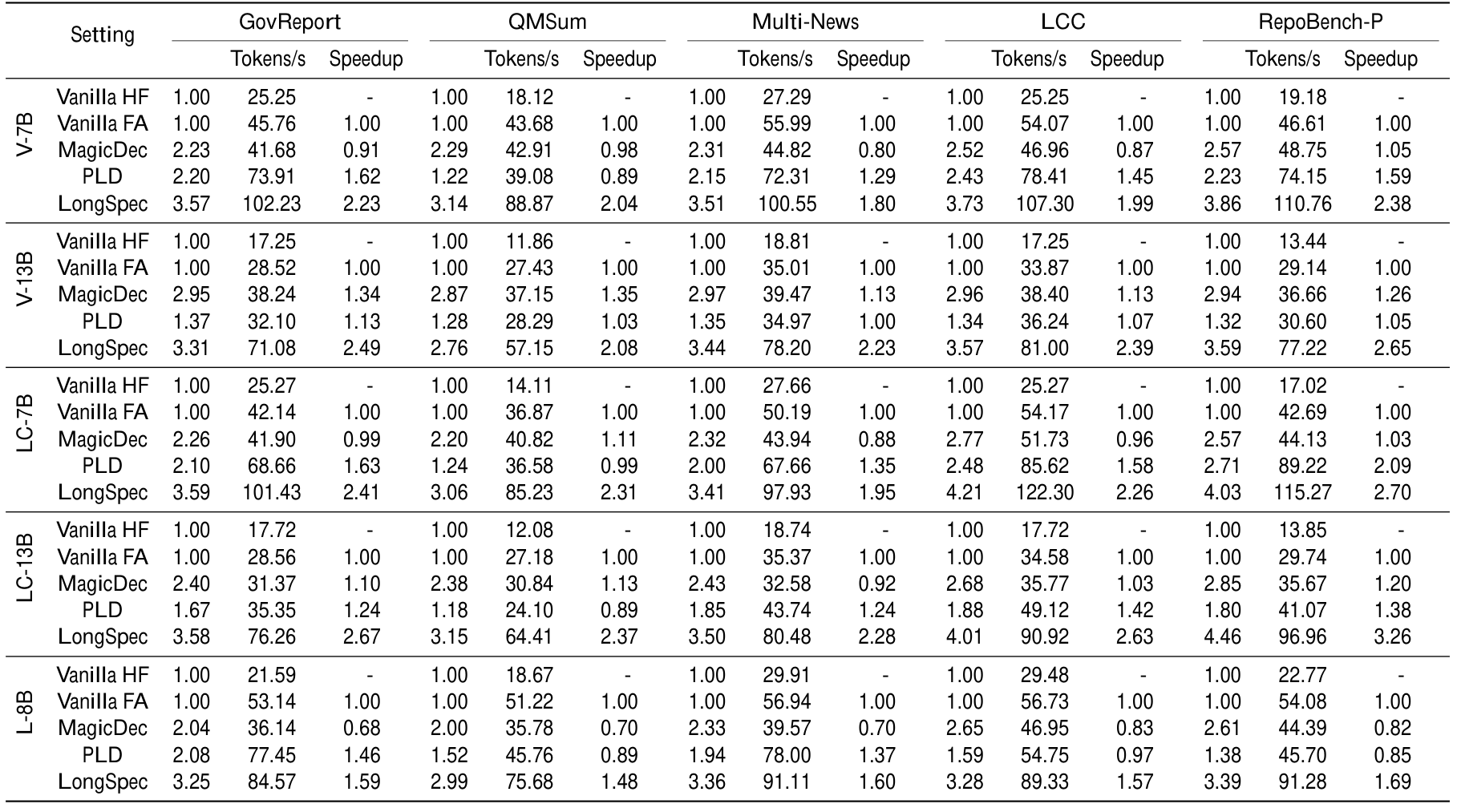
测试基准。 对于常规长上下文理解任务,我们从 LongBench benchmark 中选择需要生成较长输出的任务,因为输出较短的任务(例如 document-QA)会让推测解码的加速比难以公平衡量。具体而言,我们关注长文档摘要和代码补全任务,并在五个数据集上测试:GovReport、QMSum、Multi-News、LCC 和 RepoBench-P。对于数学推理任务,我们在四个数学推理数据集上测试 QwQ-32B:AIME24、AMC、MATH500 和 Minerva Math。
我们将方法与原始目标模型、PLD 和 MagicDec 比较。PLD 是最流行的基于检索的方法,也被称为 vLLM 中的 n-gram SD;MagicDec 是 TriForce 的简单原型。为突出 Flash Attention 在长上下文场景中的重要性,我们还展示了原始目标模型分别使用 HuggingFace eager attention 和 Flash Attention 的性能。为公平比较,MagicDec 基线也使用 Flash Attention。推测解码最重要的指标是 walltime speedup ratio,即相对于 vanilla autoregressive decoding 的实际测试加速比。我们也测试 average acceptance length \tau,即目标 LLM 每次 forward pass 平均接受的 tokens 数。
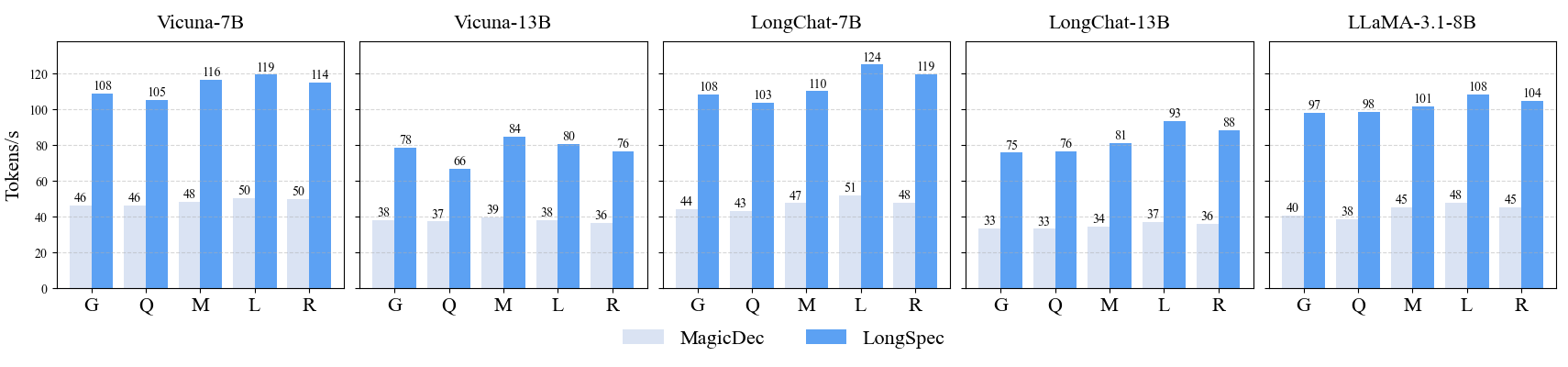
主要结果
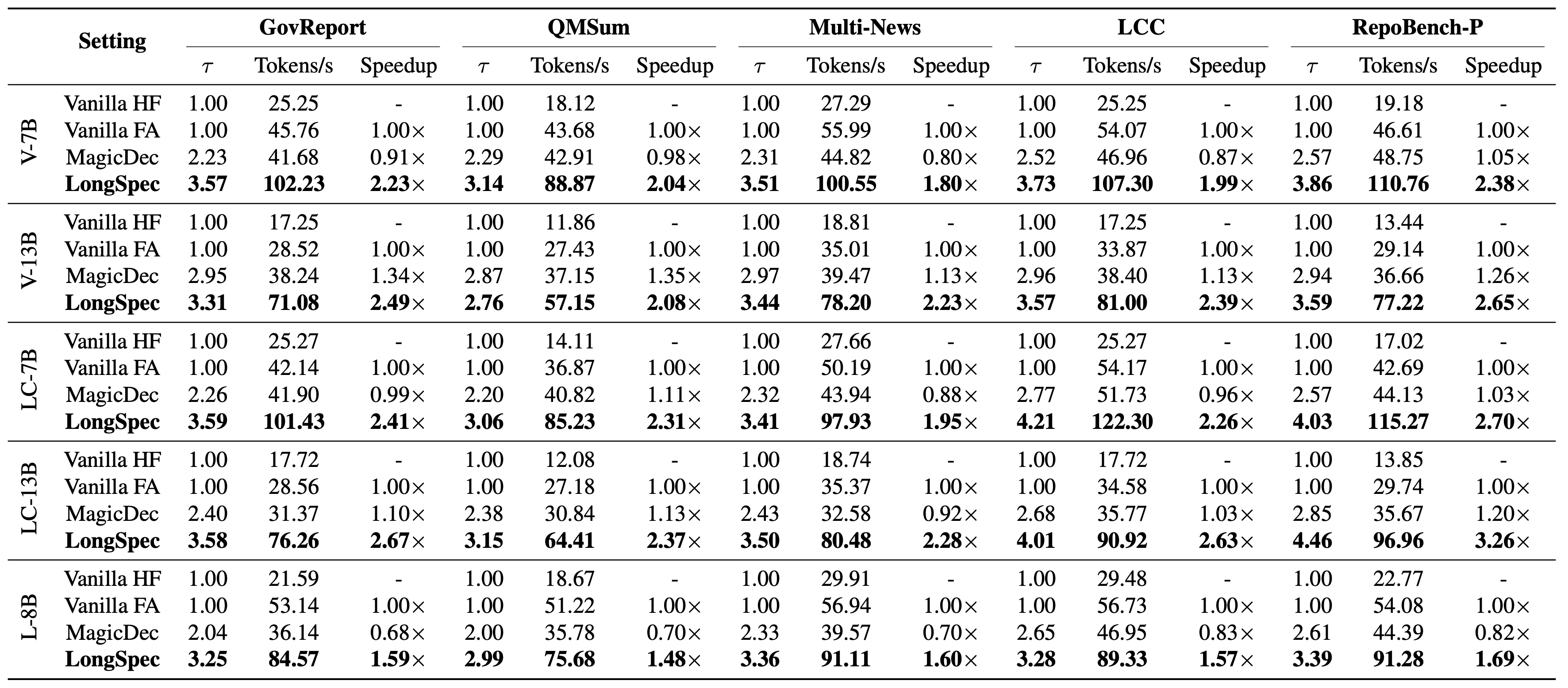
表 1 和图 3 展示了五个评估数据集在 T=0 和 T=1 下的解码速度与平均接受长度,其中 T 表示 LLM sampling 使用的 temperature。我们提出的方法在摘要任务和代码补全任务上都显著优于所有其他方法。当 T=0 时,在摘要任务上,我们的方法可实现约 3.5 的平均接受长度和最高 2.67\times 加速;在代码补全任务上,我们的方法可实现约 4 的平均接受长度和最高 3.26\times 加速。这突出了我们推测解码方法的稳健性和泛化能力,尤其是在长文本生成任务中。在 T=1 时,我们的方法实现约 2.5\times 加速,仍显著领先 MagicDec。这表明我们的方法在不同 temperature 设置下都很稳健,进一步验证了其合理性和效率。
虽然 PLD 能在许多数据集上加速生成,但它仍不及我们提出的 LongSpec。在某些场景中(例如 retrieval 很少时),PLD 甚至可能产生负加速。对于另一个基线 MagicDec,尽管它展示出与 LongSpec 相比具有竞争力的 acceptance rates,但在我们的实验中其加速明显更低。这是因为 MagicDec 主要为大 batch size 和 tensor parallelism 场景设计。在低 batch size 设置中,它的草稿模型使用带稀疏 KV cache 的目标模型全部参数,因而变得过重。这一设计选择导致低效,因为草稿模型的计算开销超过了其推测收益。我们的结果显示,当 guess length \gamma=2 时,MagicDec 只在部分数据集上实现 \gt \!1 的加速比;当 \gamma\geq3 时,它持续表现出约 0.7\times 的负加速,进一步突出了该方法在这些配置下的局限性。MagicDec 在更大 batch size 下的性能见吞吐量小节。
最后,我们发现 attention 实现对长上下文推测解码性能起着关键作用。在我们的实验中,“Vanilla HF” 指 HuggingFace 的 attention 实现,而 “Vanilla FA” 使用 Flash Attention。后者即使作为独立组件,也相比前者展示出近 2\times 加速,而我们的方法在代码补全数据集上相比 HF Attention 可实现最高 6\times 加速。该结果强调,推测解码方法必须与 Flash Attention 等优化 attention 机制兼容,尤其是在长文本设置中。我们的 hybrid tree attention 方法实现了这种兼容性,使我们能充分利用 Flash Attention 的优势并进一步加速。
消融研究
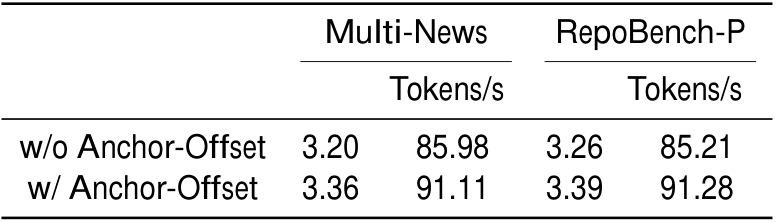
Anchor-Offset Indices。 实验结果展示了引入 Anchor-Offset Indices 的显著收益。图 4 表明,在真实长上下文数据集上训练时,使用 Anchor-Offset Indices 训练的模型相比不使用它的模型具有更低的 initial loss 和 final loss。值得注意的是,使用 Anchor-Offset Indices 初始化的模型达到相同 loss 水平的速度比对应模型快 3.93\times。表 2 进一步展示了它在两个数据集上的性能提升:一个摘要数据集 Multi-News,以及一个代码补全数据集 RepoBench-P。带 Anchor-Offset Indices 的模型展现出更快输出速度和更大的平均接受长度 \tau。这些结果强调了 Anchor-Offset Indices 在提升训练效率和模型性能方面的有效性。
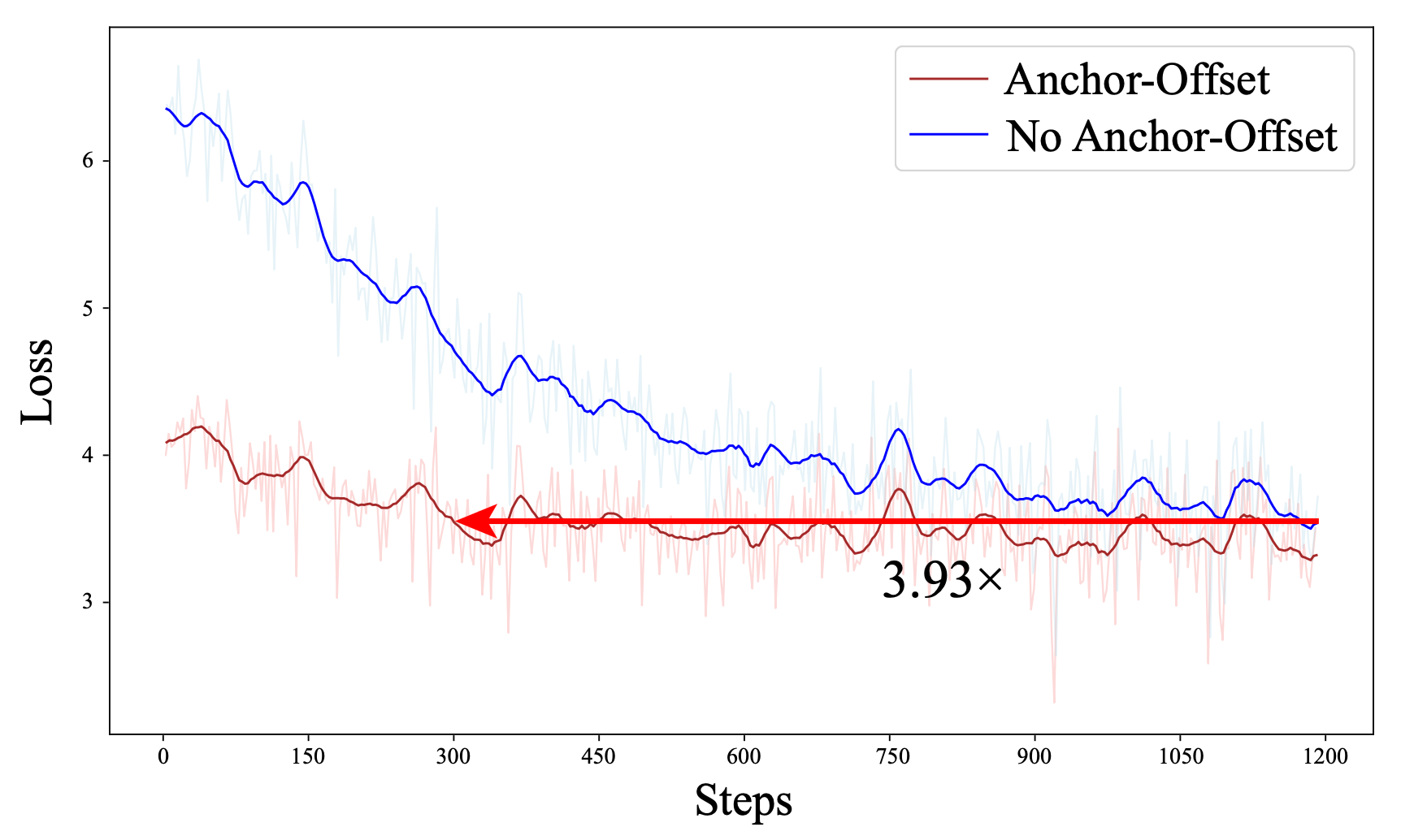
Hybrid Tree Attention。 图 5 所示结果突出了所提出 Hybrid Tree Attention 的有效性,它结合了 Flash Attention 与 Triton kernel fused_mask_attn。虽然两种方法在草稿模型 forward pass 和目标模型 FFN 计算上的耗时相近,但 hybrid 方法在目标模型 attention layer(黄色部分)上显著降低了延迟。具体来说,attention computation latency 从 HF 实现中的 49.92 ms 降至 hybrid 方法中的 12.54 ms,带来约 75% 的改进。验证步骤的时间差异很小,进一步巩固了主要性能收益来自优化 attention mechanism 的结论。
长推理加速
长推理任务最近受到广泛关注,因为它们能够让模型在扩展输出上执行复杂推理和问题求解。在这些任务中,虽然前缀输入通常相对较短,但生成输出可能极长,从而在效率和 token acceptance 方面带来独特挑战。我们的方法特别适合解决这些挑战,能够有效处理长输出场景。值得一提的是,MagicDec 不适用于这种长输出场景,因为长推理任务的初始推理阶段与传统长上下文任务不同。在长推理任务中,prefix 相对较短,MagicDec 中的草稿模型会完全退化为目标模型,无法实现加速。
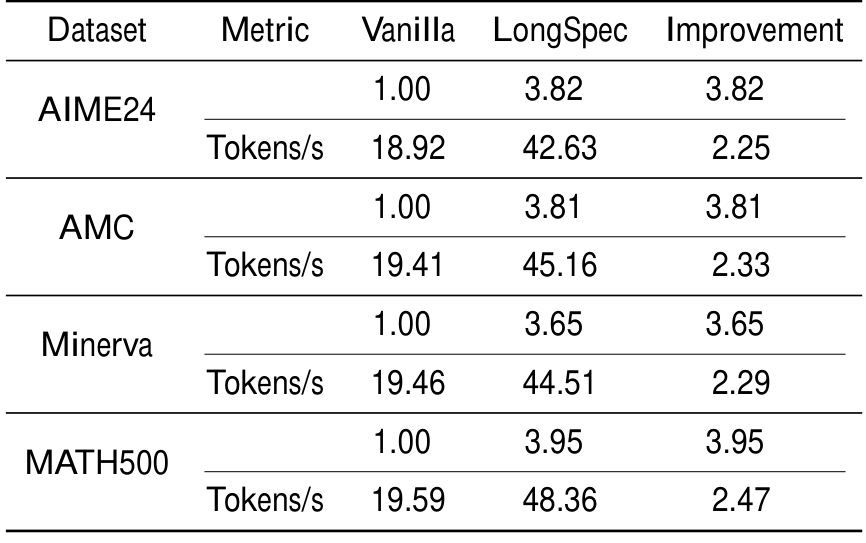
我们在 QwQ-32B 模型上使用四个广泛使用的 benchmark 评估方法,最大输出长度设为 32k tokens。表 3 所示结果展示了生成速度和平均接受 tokens 数方面的显著提升。具体来说,我们的方法实现约 45 tokens/s 的生成率,比强 Flash Attention 基线高 2.34\times,并具有平均 3.81 个 accepted tokens。值得注意的是,带 LongSpec 的 QwQ-32B 甚至比带 Flash Attention 的标准 7B 模型延迟更低,表明我们的方法有效加速了长推理模型。这些发现不仅突出了我们方法在长推理任务中的有效性,也为 o1-like 模型的无损推理加速提供了新见解。我们相信,推测解码未来将在加速这类模型中发挥关键作用。
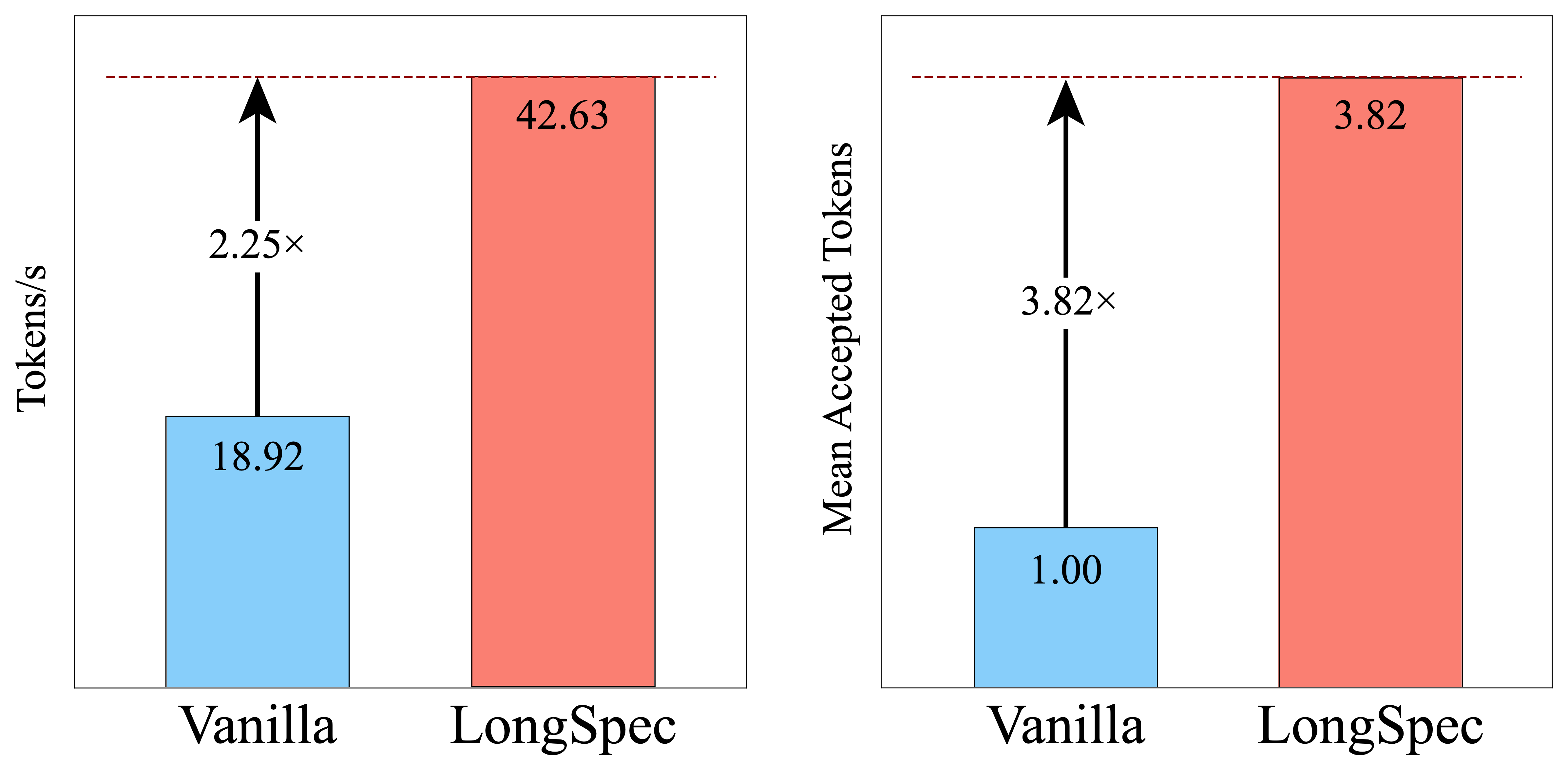
吞吐量
如图 7 所示,Vicuna-7B 在 RepoBench-P 数据集上的吞吐量结果表明,LongSpec 在所有 batch sizes 下都持续优于 Vanilla 和 MagicDec。当 batch size 为 8 时,LongSpec 实现 561.32 tokens/s 的吞吐量,约为 MagicDec(310.58 tokens/s)的 1.8\times,并且接近 Vanilla(286.96 tokens/s)的 2\times。MagicDec 以吞吐优化为目标进行设计,因此随着 batch size 增加会超过 Vanilla,反映出其针对性改进。然而,LongSpec 仍然保持优势,在所有测试 batch sizes 下维持更高吞吐量。
结论
本文提出了 LongSpec,一个旨在增强长上下文场景下无损推测解码的新框架。不同于此前主要关注短上下文设置的推测解码方法,LongSpec 直接处理三个关键挑战:过高内存开销、大位置索引训练不足,以及低效的树注意力计算。为缓解内存约束,我们引入了一种高效草稿模型架构,它通过结合滑动窗口 self-attention 与无缓存 cross-attention,将内存占用保持为常数。为解决短上下文数据相关的训练限制,我们提出 Anchor-Offset Indices,确保即使在短序列数据集中,大位置索引也能得到充分训练。最后,我们提出 Hybrid Tree Attention,它将基于树的推测解码与 Flash Attention 高效结合。大量实验展示了 LongSpec 在长上下文理解任务和真实长推理任务中的有效性。我们的发现强调了为长上下文设置专门设计推测解码方法的重要性,并指出了高效大规模语言模型推理未来研究的有前景方向。
附录
关于有损推测解码的相关工作
虽然原始推测解码方法主要是无损的,但一些近期工作尝试放宽约束并探索有损推测解码。例如,BiLD 使用一个小模型进行自回归文本生成,并偶尔以非自回归方式调用一个更大的模型来修正不准确预测,从而在质量退化很小的情况下实现加速。Narasimhan 等人提出 speculative cascading,这是一种将 cascade-style deferral rules 与 speculative execution 集成的方法,相比单独使用任一方法都能获得更好的 cost-quality trade-off。另一种方法 MTAD 使用一个较小辅助模型来近似大模型的 multi-token joint distribution,通过接受这种近似中的有界误差,同时提升推理速度与输出有效性。为解决高质量但未对齐 draft tokens 被拒绝的问题,Bachmann 等人提出通过训练一个紧凑的 “judge” 模块来识别有效 continuation,从而适配 verification step,即使没有完美目标模型对齐也能显著提高 acceptance rates 和速度。RSD 引入 process reward model 来评估中间解码步骤,动态决定何时调用目标模型,并引入朝向高奖励输出的受控偏置,以优化 cost-quality trade-off。RAPID 使用基于 RAG 的方法在缩短上下文上作为 drafter。TokenSwift 综合使用带部分 KV cache 的 LLM 和 N-gram tables 来加速超长序列生成(最高 100k tokens),同时将计算时间从数小时减少到数分钟。
为什么 KV Cache 能提供帮助的直觉
KV cache 存储了模型在处理先前 tokens 时积累的上下文信息。在预测下一个 token 时,目标模型依赖三个组件:KV cache(上下文记忆)、输入词嵌入,以及模型参数。
在我们的方法中,草稿模型已经与目标模型共享输入嵌入,因此二者预测中的主要差异来自 KV cache 和内部参数。通过允许草稿模型使用由目标模型生成的 KV cache,我们消除了另一个变化来源。因此,它们预测之间唯一剩下的差异来自模型参数。这种共享使草稿模型的预测更接近目标模型的预测,因为它移除了由不同上下文表示造成的差异。
注意力聚合的正确性
因为 query matrix Q 可以分解成若干行,每一行代表一个单独 query q,所以我们只需考虑每一行 q 与 KV 计算 attention 后的输出。这样可以假设参与计算的 KV 已经经过 tree mask 处理,从而简化证明。我们只需证明由每个单独 q 得到的输出 o 满足要求,这即可说明整个矩阵 Q 的整体输出 O 也满足要求。
命题。 记 merged attention 的 log-sum-exp 为:
\mathrm{LSE}_{\mathrm{merge}} = \log\Bigl(\exp\bigl(\mathrm{LSE}_{\mathrm{cache}}\bigr) \;+\; \exp\bigl(\mathrm{LSE}_{\mathrm{specs}}\bigr)\Bigr),则 merged attention output 可写为:
o_{\mathrm{merge}} = o_{\mathrm{cache}} \cdot \exp\bigl(\mathrm{LSE}_{\mathrm{cache}} - \mathrm{LSE}_{\mathrm{merge}}\bigr) + o_{\mathrm{specs}} \cdot\exp\bigl(\mathrm{LSE}_{\mathrm{specs}} - \mathrm{LSE}_{\mathrm{merge}}\bigr).证明。 对大小为 d_{qk} 的 q,对 K_{\mathrm{merge}} 和 V_{\mathrm{merge}} 执行标准 scaled dot-product attention,其中二者大小分别为 (M+N) \times d_{qk} 和 (M+N) \times d_v,可写作:
\begin{aligned} o_{\mathrm{merge}} &= \operatorname{mha}\left(q, K_{\mathrm{merge}}, V_{\mathrm{merge}}\right) \\ &= \operatorname{softmax}\left(qK_{\mathrm{merge}}^\top/\sqrt{d_{qk}}\right) V_{\mathrm{merge}}. \end{aligned}由于 K 和 V 由 \left(K_{\mathrm{specs}}, K_{\mathrm{cache}}\right) 与 \left(V_{\mathrm{specs}}, V_{\mathrm{cache}}\right) 堆叠形成,我们相应拆分 logit matrix:
q K_{\mathrm{merge}}^\top / \sqrt{d_{qk}} = \operatorname{concat}\Bigl( q K_{\mathrm{cache}}^\top / \sqrt{d_{qk}}, q K_{\mathrm{specs}}^\top / \sqrt{d_{qk}} \Bigr).记这些 sub-logit matrices 为:
Z_{\mathrm{cache}} = q K_{\mathrm{cache}}^\top / \sqrt{d_{qk}},\quad Z_{\mathrm{specs}} = q K_{\mathrm{specs}}^\top / \sqrt{d_{qk}}.Z_{\mathrm{specs}} 的每一行对应 q 中第 i 个 query 与 K_{\mathrm{specs}} 中所有行的点积;Z_{\mathrm{cache}} 的行则对应同一个 query 与 K_{\mathrm{cache}}。
为组合 partial attentions,我们记录每个 sub-logit set 的 exponentials 之和的对数。具体定义:
\begin{aligned} \mathrm{LSE}_{\mathrm{cache}} &= \log\left(\sum\nolimits_{j=1}^{N} \exp\left(Z_{\mathrm{cache}}^{(j)}\right)\right),\\ \mathrm{LSE}_{\mathrm{specs}} &= \log\left(\sum\nolimits_{j=1}^{M} \exp\left(Z_{\mathrm{specs}}^{(j)}\right)\right), \end{aligned}其中 Z_{\mathrm{specs}}^{(j)} 表示第 j 个元素的 logit,Z_{\mathrm{cache}}^{(j)} 类似。
于是 o_{\mathrm{cache}} 和 o_{\mathrm{specs}} 可写为:
\begin{aligned} o_{\mathrm{cache}} &= \frac{\sum_{j=1}^{N} \exp\left(Z_{\mathrm{cache}}^{(j)}\right) V_{\mathrm{cache}}^{(j)}}{\exp\left(\mathrm{LSE}_{\mathrm{cache}}\right)},\\ o_{\mathrm{specs}} &= \frac{\sum_{j=1}^{M} \exp\left(Z_{\mathrm{specs}}^{(j)}\right) V_{\mathrm{specs}}^{(j)}}{\exp\left(\mathrm{LSE}_{\mathrm{specs}}\right)}. \end{aligned}整个 attention score 可写为:
\begin{aligned} N_{\mathrm{num}} &= \sum_{j=1}^{N} \exp\bigl(Z_{\mathrm{cache}}^{(j)}\bigr) V_{\mathrm{cache}}^{(j)} + \sum_{j=1}^{M} \exp\bigl(Z_{\mathrm{specs}}^{(j)}\bigr) V_{\mathrm{specs}}^{(j)},\\ D_{\mathrm{den}} &= \exp\bigl(\mathrm{LSE}_{\mathrm{cache}}\bigr) + \exp\bigl(\mathrm{LSE}_{\mathrm{specs}}\bigr),\\ o_{\mathrm{merge}} &= \frac{N_{\mathrm{num}}}{D_{\mathrm{den}}}. \end{aligned}将 split attention 聚合进 whole attention,即可得到:
o_{\mathrm{merge}} = o_{\mathrm{cache}} \cdot\exp\bigl(\mathrm{LSE}_{\mathrm{cache}} - \mathrm{LSE}_{\mathrm{merge}}\bigr) + o_{\mathrm{specs}} \cdot \exp\bigl(\mathrm{LSE}_{\mathrm{specs}} - \mathrm{LSE}_{\mathrm{merge}}\bigr).证毕。
实验细节
所有模型均使用 8 张 A100 80GB GPU 训练。对于在短上下文数据上训练的 7B、8B 和 13B 目标模型,我们使用带 ZeRO-1 的 LongSpec。对于在长上下文数据上训练的 7B、8B 和 13B 模型,以及所有 33B 目标模型设置,我们使用 ZeRO-3。
标准 cross-entropy 用于优化草稿模型,同时目标模型参数保持冻结。为缓解 logits 计算造成的 VRAM 峰值,我们使用由 Liger Kernel 实现的 fused-linear-and-cross-entropy loss,它将 LM head 与 softmax function 一起计算,并能大幅缓解该问题。
对于 SlimPajama-6B 数据集,我们将 batch size(包括 accumulation)配置为 2048,将最大 learning rate 设为 5e-4,使用 cosine learning rate schedule,并用 AdamW 优化草稿模型。在长上下文数据集上训练时,我们采用 batch size 256 和最大 learning rate 5e-6。草稿模型在所有数据集上都只训练一个 epoch。
需要注意的是,主要计算成本来自对目标模型进行 forward 以获得 KV cache。近期,一些公司引入了一种称为 context caching 的服务,涉及存储大量 KV cache。因此,在真实部署中,这些预存储 KV caches 可直接作为训练数据使用,从而显著加速训练过程。
对于 LongSpec 的 tree decoding,我们采用 dynamic beam search 来构造树。先前研究表明,beam search 虽然能实现高 acceptance rates,但在推测解码中处理速度较慢。我们的研究发现,该 slowdown 主要由 KV cache movement 引起。在传统 beam search 中,不属于 top-k likelihood 的 nodes 会被丢弃,这一步需要移动 KV cache。然而,在推测解码中,丢弃这些 nodes 并无必要,因为 draft sequences 不需要保持统一长度。相反,我们可以简单地停止对低 likelihood branches 的 descendant nodes 进行计算,而不完全移除它们。采用这一方法后,beam search 能获得强性能而不会带来过高计算开销。在实验中,每个推测步骤的 beam width 设为 [4, 16, 16, 16, 16]。本文所有推理实验均在单张 A100 80GB GPU 上使用 float16 precision 进行。
EAGLE 与 Token Recycling 在长上下文推测解码上的实验结果
在表 4 中,我们比较两个模型在五种设置下的平均接受长度 \tau 和解码速度(tokens/s):来自 HuggingFace 的 baseline PyTorch 实现(“Vanilla HF”)、使用 Flash Attention 的相同模型(“Vanilla FA”)、Token Recycling(“TR”,一种 SoTA retrieval-based 方法)、EAGLE(使用 anchor offset indices 训练,并使用 HuggingFace 推理),以及我们带 hybrid tree attention 的 LongSpec。在五个数据集(GovReport、QMSum、MultiNews、LCC 和 RB-P)上,Vanilla HF 的解码速度被限制在 14 到 30 tokens/s 之间,而切换到 Flash Attention 后速度提升到约 50 tokens/s,带来超过 2.5\times 的加速。
EAGLE 将 acceptance length 扩展到约 2,并实现 26-40 tokens/s,相比 Vanilla HF 获得 30-50% 的加速。然而,由于 EAGLE 无法利用 Flash Attention,它在每种设置下的解码速度都显著低于 Vanilla FA。至于 TR,虽然它将 acceptance length 扩展到约 3(远大于 EAGLE),并在许多任务上取得中等程度加速,但它在整体上始终不如 LongSpec。
相比之下,带 hybrid tree attention 的 LongSpec 在所有模型和数据集上实现约 100 tokens/s 的高得多的解码速度。这表明 EAGLE 与 Flash Attention 的不兼容从根本上限制了它的解码性能。我们的 hybrid tree attention 保持了与 Flash Attention 的兼容性,因此释放出显著更高的解码速度,凸显了将 tree-structured attention 与 Flash Attention 等 SoTA 长上下文推理技术结合的重要性。
Flash Attention。所有结果均在 T=0 下计算。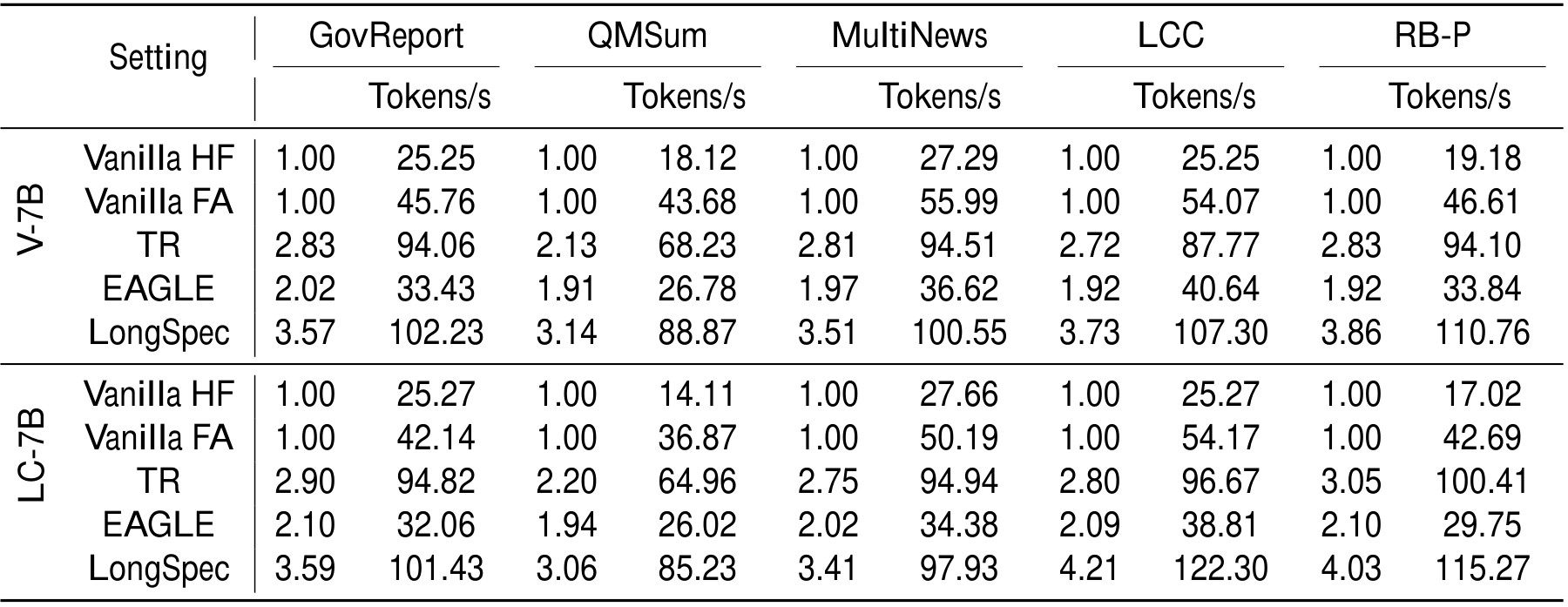
不同 Prefill 长度下的性能分析
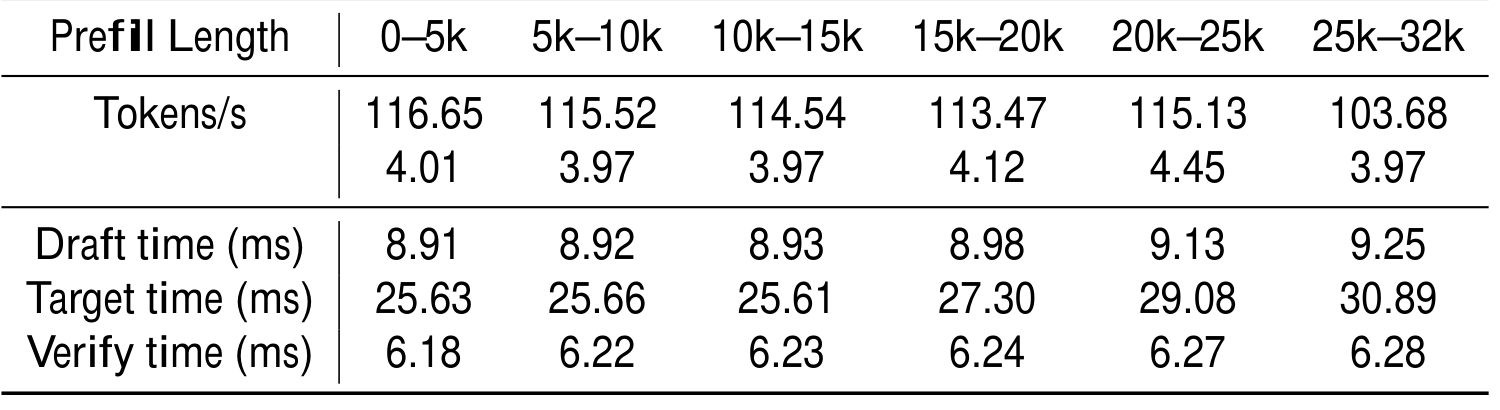
在表 5 中,我们展示了随着 prefill length 增加时的详细性能分解,设置为 LongChat-7B on GovReport。在所有 token ranges 中,生成速度都保持非常稳定,只在 25k-32k 范围内略有下降。平均 acceptance length 在所有 ranges 中保持一致,这表明系统在生成过程中选择保留的 tokens 数表现稳定。这种稳定性说明 draft quality 不受 prefill 长度影响,并能维持一致的输出动态。
在延迟方面,draft time 只小幅增加,从最短上下文范围中的 8.91 ms 增至最长上下文范围中的 9.25 ms;而 target time 从 25.63 ms 逐步增加到 30.89 ms,反映出管理更大上下文所增加的计算负载。Verify time 在所有 ranges 中几乎保持常数,只从 6.18 ms 略增至 6.28 ms。
总体而言,这些结果表明,系统能够随着更长输入上下文有效扩展,在延迟仅适度增加的情况下,保持高吞吐和一致的 drafting quality。这突出了我们的方法在涉及扩展输入序列的真实应用中的实用性和稳健性。
伪代码
这里给出 Anchor-Offset Indexing 和 Flash Noisy Training 的伪代码。
输入:序列长度 N;最大长度 MAX_LEN;Query states q_s。
输出:使用修改后索引应用 RoPE 的 Query states。
P <- {0, 1, ..., N-1} // 初始位置索引
o <- RandomInt(0, MAX_LEN - N) // 生成随机 offset
P[4:] += o // 对前 4 个 anchors 之后的索引应用 offset
// 例如,当 N=128, o=16257 时,P 变为 [0, 1, 2, 3, 16261, ..., 16385]
return RoPE(q_s, P)输入:Queries Q,Key cache K,Value cache V。
输出:最终 attention output。
j <- RandomInt(1, 4) // 随机选择要丢弃的 tokens 数
// 在切片输入上执行 attention
Q' <- Q[j:] // 丢弃前 j 个 queries
K' <- K[:-j] // 从 cache 中丢弃最后 j 个 keys
V' <- V[:-j] // 从 cache 中丢弃最后 j 个 values
attn_out <- FlashAttention(Q', K', V')
// 对 output 进行 padding,以匹配原始 query length
padded_out <- Concat(Zeros(j), attn_out)
return OutputProjection(padded_out)案例研究
这里展示 LongChat-7B 模型在 GovReport 上的一些说明性案例,其中蓝色标记的 tokens 表示被目标模型接受的 draft tokens。由于篇幅限制,论文未展示完整答案。
Comments NOTHING