
Meta Data
- 发表时间 2026-02-12
- 作者:Jian Chen, Yesheng Liang, Zhijian Liu etc.
- 论文链接:https://arxiv.org/pdf/2602.06036.pdf
- 项目链接:https://github.com/z-lab/dflash
摘要
自回归大语言模型(LLMs)表现出色,但需要固有的顺序解码,导致推理延迟高和 GPU 利用率差。投机解码(Speculative decoding)通过使用一个快速草稿模型来缓解这一瓶颈,该模型的输出由目标 LLM 并行验证。然而,现有方法仍然依赖于自回归草稿(autoregressive drafting),这仍然是顺序的,并限制了实际的速度提升。扩散 LLM 通过实现并行生成提供了一种有前途的替代方案,但目前的扩散模型通常不如自回归模型。在本文中,我们介绍了 DFlash,一个投机解码框架,它采用轻量级的块扩散模型进行并行草稿。我们表明,投机解码为扩散模型提供了一个自然有效的设置。通过在一次前向传递中生成草稿 token,DFlash 实现了高效的草稿,并通过将草稿模型条件化在从目标模型提取的上下文特征上,它以更高的接受率实现了高质量的草稿。实验表明,DFlash 在一系列模型和任务上实现了超过 6\times 的无损加速,与最先进的投机解码方法 EAGLE-3 相比,速度提高了 2.5\times 。
Introdution
大语言模型 (LLMs) 已经实现了广泛的强大应用,包括对话式代理 (Yang et al., 2025; Guo et al., 2025) 和自动化编程工具。尽管取得了成功,LLM 推理仍然以逐个 token 的顺序生成过程为主导,其中每个输出都依赖于完整的先前上下文。这种固有的串行性造成了主要的性能瓶颈:推理速度慢、内存受限,并且未能充分利用现代 GPU。随着最近出现的长思想链(CoT)推理模型(OpenAI 等人,2024;Guo 等人,2025),这个瓶颈变得越来越严重,因为延长的推理时间现在主导了生成过程。
推测性解码 (Leviathan 等人,2023; Li 等人,2025c, 2024, b; Cai 等人,2024) 已成为解决这一瓶颈的主要解决方案。该范例采用轻量级草稿模型来推测未来 Token 的序列,然后由大型目标模型并行验证。虽然这种方法实现了无损加速并已广泛集成到生产框架中,但 EAGLE-3 (Li 等人,2025b) 等最先进的方法仍然依赖于自回归绘图。这种串行绘图过程不仅本质上效率低下,而且容易受到错误累积的影响,这实际上将可实现的加速限制在大约 2-3\times 。
最近,扩散 LLM (dLLM) (Nie 等人,2025) 通过实现并行文本生成和双向上下文建模,为自回归 LLM 提供了一种有前景的替代方案。块扩散模型(Arriola 等人,2025;Cheng 等人,2025;Wu 等人,2025)可以同时对屏蔽 Token 块进行去噪。然而,当前的开源 dLLM 在生成质量方面通常不如自回归同行。此外,保持可接受的输出质量通常需要大量的去噪步骤,这会显着降低其原始推理速度(Qian 等人,2026)。
这种情况揭示了一个关键的权衡:自回归模型提供卓越的性能,但会受到顺序延迟的影响,而扩散模型允许快速、并行生成,但通常以准确性为代价。一个自然的研究问题如下: 我们能否结合两种范式的优点,同时减轻各自的缺点? 一个引人注目的解决方案在于利用扩散模型进行高速、并行绘图,同时依靠高质量的自回归模型进行验证,以确保最终输出保持无损。
然而,利用扩散模型进行草稿生成并非易事,现有方法要么不切实际,要么只能提供有限的速度提升。 DiffuSpec (Li et al., 2025a) 和 SpecDiff-2 (Sandler et al., 2025) 等方法使用了大规模(例如.,7B 参数)的草稿模型。 这种巨大的内存占用对于实际部署而言往往代价高昂。 此外,尽管这些大型草稿模型能够生成质量相对较高且接受长度较长的草稿 token,但高草稿延迟将其实际速度提升限制在适度的 3-4\times 。 相比之下,PARD (An et al., 2025) 训练小型自回归模型来模仿扩散风格的并行生成,然后为目标 LLM 执行推测解码。 然而,由此产生的小型模型缺乏目标 LLM 的建模能力,导致接受长度有限,速度提升上限约为 3\times 。
真的 “没有免费的午餐” 吗? 我们能否构建一个既轻量又高精度的扩散草稿模型?
在本文中,我们提出了 DFlash,这是一个推测解码框架,它使用轻量级的块扩散模型来实现快速且高质量的草稿生成。 我们的核心见解很简单:目标模型最了解。 正如 Samragh et al. (2025) 所观察到的,大型自回归 LLM 的隐藏特征隐含了关于多个未来 token 的信息。 DFlash 利用这些隐藏特征作为上下文,条件化草稿模型以并行预测未来的 token 块。 实际上,草稿模型变成了一个扩散适配器,它有效地利用了大型目标模型所建模的深度上下文特征。 DFlash 没有要求一个微小的草稿模型从头开始推理,而是将目标模型的推理能力与小型扩散草稿模型的并行生成速度相结合。
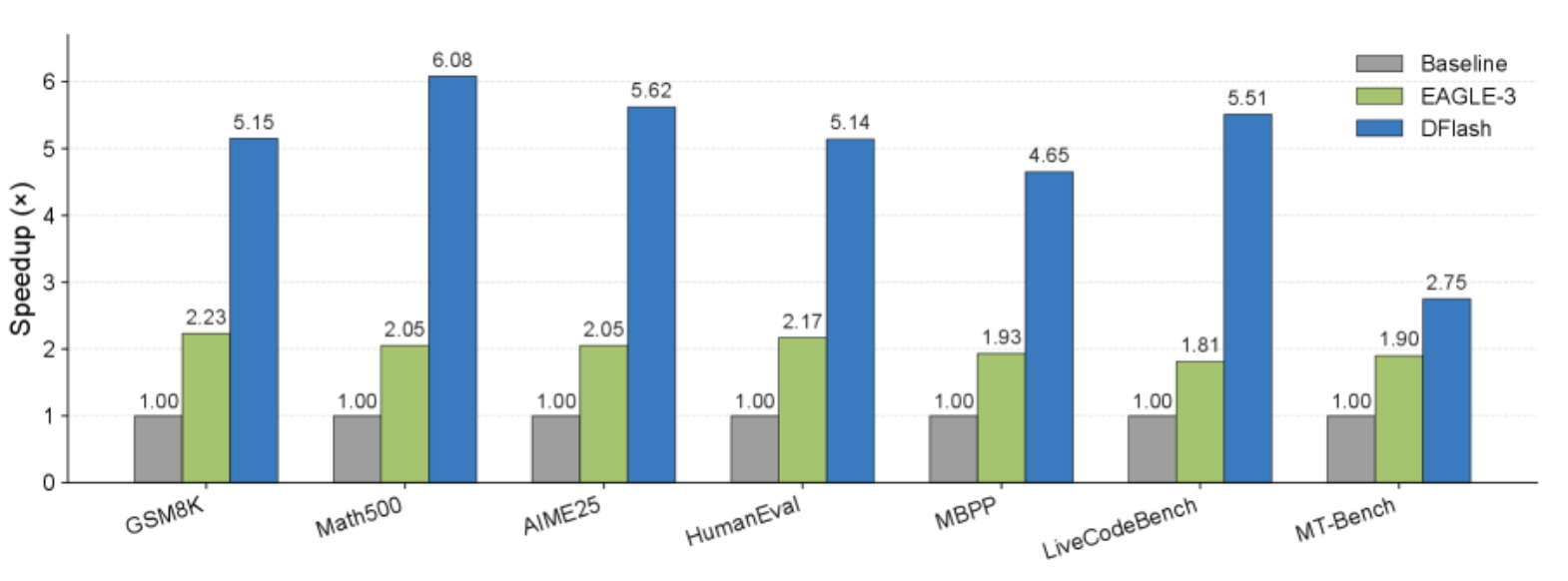
我们在广泛的模型和基准测试中评估 DFlash,并使用 SGLang (Zheng et al., 2024) 在实际部署场景下展示了它的实际效益。 正如 Figure 1 所示,DFlash 在 Qwen3-8B (Yang et al., 2025) 上实现了高达 6.1\times 的速度提升,并且在大多数基准测试上比最先进的 EAGLE-3 快近 2.5\times 。 我们相信 DFlash 在加速大语言模型推理和普及高性能人工智能方面取得了重大进展。
相关工作
投机解码(Speculative Decoding)
推测解码通过减轻自回归生成的顺序瓶颈来加速大语言模型的推理。 早期的 (Leviathan et al., 2023) 方法采用一个较小的草稿模型来提议 token 序列,然后由一个较大的目标模型并行验证。 Medusa (Cai et al., 2024) 通过增强基础大语言模型并添加多个预测头,并使用树注意力进行并行验证,从而消除了外部草稿模型。 EAGLE 系列 (Li et al., 2025c, 2024, b) 通过利用冻结的目标模型的特征级上下文,进一步改进了推测解码。 EAGLE-1 预测未来的隐藏状态分布以提高接受率,EAGLE-2 引入了自适应草稿树,EAGLE-3 精炼了训练目标以加速提速。
尽管取得了这些进展,但大多数现有方法依赖于自回归草稿,这仍然是顺序的,限制了它们的加速效果。
扩散语言模型
扩散大型语言模型 (dLLMs) 通过并行预测掩码 token,提供了一种替代自回归生成的方法。 LLaDA (Nie et al., 2025) 是第一个将 dLLMs 扩展到数十亿参数的模型,其性能可与 LLaMA-3.1-8B (Grattafiori et al., 2024) 相媲美。 然而,全并行扩散模型存在生成长度固定和缺乏高效 KV 缓存支持的问题。 块扩散模型 (Arriola et al., 2025) 通过逐块去噪序列来解决这些问题,将并行性与自回归结构相结合。 基于这一思想,Fast-dLLM v2 (Wu et al., 2025) 和 SDAR (Cheng et al., 2025) 将预训练的自回归大语言模型改编为块扩散变体,实现了并行生成,同时在特定任务上保持了生成质量。 尽管如此,现有的 dLLMs 通常性能不如最先进的自回归模型,并且通常需要大量的去噪步骤,这限制了它们的实际推理速度。
基于扩散的投机解码(Diffusion-based Speculative Decoding)
最近的工作探索使用扩散模型作为推测解码中的起草者。 TiDAR (Liu 等人, 2025) 联合训练扩散和自回归目标,通过扩散实现并行“思考”,通过自回归解码实现顺序“说话”,尽管最终生成质量尚未无损。
其他方法将自回归模型重新用于扩散式绘图。 Samragh 等人 (2025) 观察到自回归 LLM 隐式编码未来 Token 信息并训练 LoRA 适配器以实现并行起草,同时保留用于验证的基本模型。
DiffuSpec (Li 等人, 2025a) 和 SpecDiff-2 (Sandler 等人, 2025) 采用大型预训练 dLLM 作为推测起草者,通过推理时间搜索或训练测试对齐来提高接受度。 然而,这些方法依赖于大量的起草者(例如.,7B参数),导致大量的内存和延迟开销。 虽然它们实现了较长的接受长度,但高昂的起草成本往往抵消了现实服务场景中的实际加速。
准备工作
本节形式化了推测解码的加速机制,并阐明了自回归和基于扩散的起草之间的效率权衡。我们的分析强调了为什么扩散起草者具有独特的优势,可以实现低起草延迟和高接受率。
推测解码加速
推测性解码使用较小的草稿模型 \mathcal {M}_d 加速目标模型 \mathcal {M}_t 的推理。在每个解码周期中,草稿模型都会提出 \gamma 标记,这些标记由目标模型并行验证。
在 Sadhukhan 等人 (2025) 之后,每个 Token 的平均延迟为
其中 T_{\text {draft}} 是生成草稿 Token 所花费的时间, T_{\text {verify}} 是验证成本,\tau\in [1,\gamma+1] 是每个周期接受的 Token 的预期数量,包括目标模型产生的奖励 Token。令 L_{\text {target}} 表示 \mathcal {M}t 的每个 Token 的自回归延迟;最终的加速比是
\eta = \frac {L{\text{target}}}{L}
该表达式使权衡变得明确:通过增加预期接受长度 \tau 或减少起草开销 T_{\text {draft}} 来提高速度。
自回归(Autoregressive)vs. 扩散绘图(Diffusion Drafting)
自回归起草者按顺序生成 Token ,从而产生起草成本
T_{\text {draft}} = \gamma \cdot t_{\text {step}}
其中 t_{\text {step}} 是单个前向传递的延迟。 因此,起草成本随着推测预算 \gamma 线性增长。
为了保持延迟可控,自回归绘图器被限制在非常浅的架构 (例如.,EAGLE-3 中的单个转换器层)。 这严重限制了草图质量:虽然增加 \gamma 会增加绘图成本,但由于模型容量有限,接受长度 \tau 很快就会饱和。 实际上,这种不平衡限制了可实现的加速。
扩散起草者在一次前向传递中并行生成所有 \gamma Token ,产生
T_{\text {draft}} = t_{\text {parallel}}
其中 t_{\text {parallel}} 表示区块生成的延迟。 现代 GPU 执行此类并行操作的效率远高于多次顺序传递,使得
t_{\text {parallel}} \ll \gamma \cdot t_{\text {step}}
对于大小相当的模型而言。 因此,对于中等大小的块, T_{\text {draft}} 在很大程度上对 \gamma 不敏感。
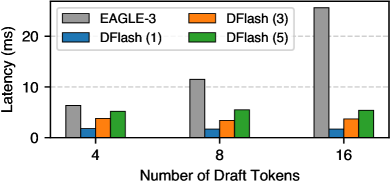
这种并行性从根本上改变了设计空间。 由于起草成本不再随生成的 token 数量而扩展,扩散起草器可以负担得起更深、更具表现力的架构,而不会牺牲延迟。 这种增加的容量显著提高了起草质量和接受长度。 经验上,一个生成 16 个 token 的五层 DFlash 起草模型在达到更低延迟(Figure 3)和更高接受长度方面优于生成 8 个 token 的 EAGLE-3,这使得 DFlash 在起草质量和起草成本之间处于更有利的帕累托前沿。
方法论
推理
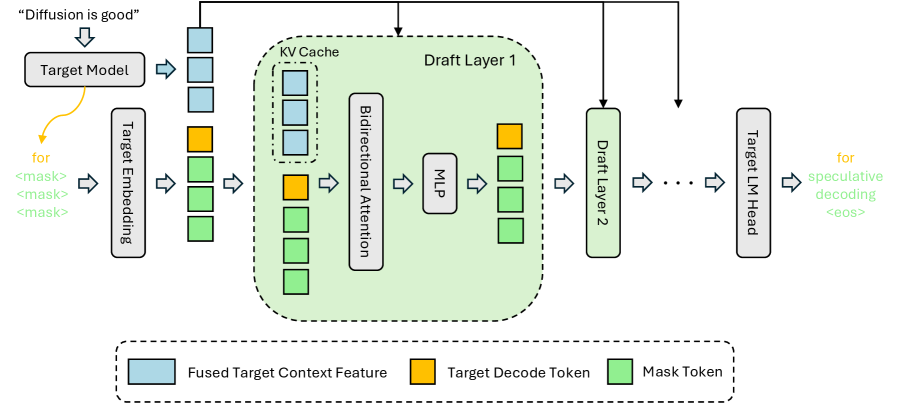
DFlash的系统设计如图Figure 2所示。 在本节中,我们将解释DFlash能够使用非常小的、高效的起草模型实现高起草接受长度的关键设计选择。
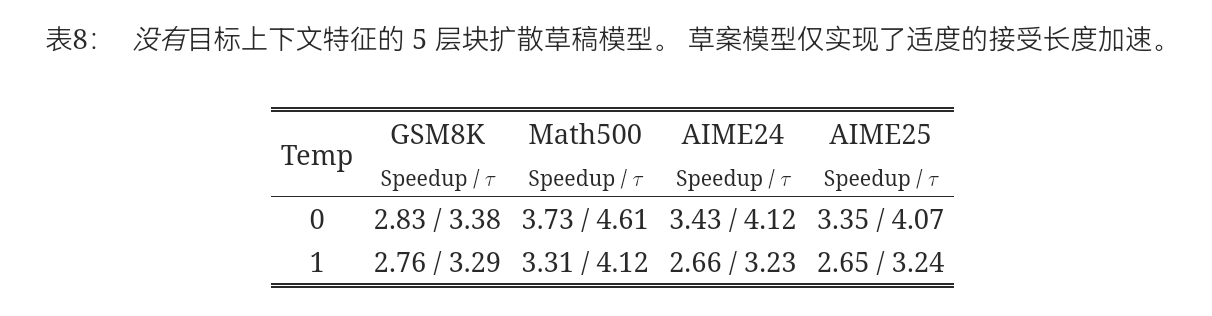
来自目标模型的上下文特征:像 An 等人 (2025) 这样的先前工作应用了小型扩散模型作为推测性起草者,这导致了较差的接受长度和有限的加速。为了验证这一点,我们训练了一个五层块扩散起草模型,没有任何来自目标模型的条件,并在几个数学基准上对其进行评估。 如Table 8所示的结果,由此产生的速度提升是适度的,通常在2-3\times之间。 这种限制源于缺乏丰富的上下文引导:在无法访问目标模型的内部表示的情况下,扩散起草器必须有效地从头开始预测未来的token。
相比之下,大型自回归目标模型的隐藏表示比token级别的logits编码了更多信息。 这些特征捕捉了长距离依赖关系和任务特定的语义,并且——至关重要的是——隐式地编码了未来 token 预测的信息,正如 Samragh et al. (2025) 所观察到的那样。
在 DFlash 中,给定一个输入提示,目标模型首先执行标准的预填充(prefill)过程来生成第一个 token。 在此过程中,我们从均匀采样的一组固定层(从浅层到深层)中提取隐藏表示。 这些隐藏状态被连接起来,并通过一个轻量级的投影层进行处理,将跨层信息融合到一个紧凑的 目标上下文特征 中,然后该特征用于条件化草稿模型。
通过 KV 注入进行条件化可以实现接受度(acceptance)的缩放。 像 EAGLE-3 这样的现有方法也利用了目标模型的隐藏特征,但它们将这些特征与草稿模型的 token 嵌入融合,并将它们仅作为输入提供给草稿模型。 随着草稿模型深度的增加,来自目标模型的信息变得越来越稀释,导致在增加更多草稿层时,接受长度的收益逐渐减少。
DFlash 采用了一种根本不同的策略。 我们将融合的目标上下文特征视为持久的上下文信息,并将其直接注入到每一个草稿模型层的 Key 和 Value 投影中。 投影后的特征存储在草稿模型的 KV 缓存中,并在草稿迭代之间重用。 这种设计在整个草稿模型中提供了强大而一致的条件化,使得接受长度能够有效地随着草稿层数的增加而扩展。 我们在 Section 5.4.2 中更详细地分析了这一行为。
并行扩散草稿:DFlash 速度的另一个关键贡献是其低草稿延迟。 自回归草稿模型必须执行多次顺序前向传播来生成草稿 token 或树,这限制了并行性并导致 GPU 利用率低下。 相比之下,DFlash 使用块级扩散过程预测下一个 token 块。 块内的所有屏蔽位置在单个前向传递中并行解码。 与自回归绘图相比,这种逐块并行生成大大减少了绘图延迟,并实现了显着更高的硬件利用率,即使在使用更深的绘图模型时也是如此。
总体而言,DFlash 将基于扩散的并行绘图与目标模型的紧密耦合调节相结合,从而实现高质量绘图并显着减少绘图延迟。
训练
DFlash 草稿模型经过训练,可将块级扩散预测与冻结自回归目标模型的输出对齐。我们没有直接采用标准的块扩散训练(Arriola 等人,2025),而是引入了一些关键的修改,以提高训练效率、可扩展性以及与推理时间推测解码行为的一致性。
KV 注入:按照推理管道,给定一个由提示及其响应组成的序列,我们首先将整个干净序列传递给目标模型,以提取和融合所有标记的隐藏特征。然后将隐藏的特征作为键和值投影注入到草稿模型中,如图4所示.
屏蔽块的随机采样:在标准块扩散训练中,响应被均匀地划分为块,并且每个块内的随机位置被屏蔽,模型经过训练以对屏蔽的标记进行去噪。
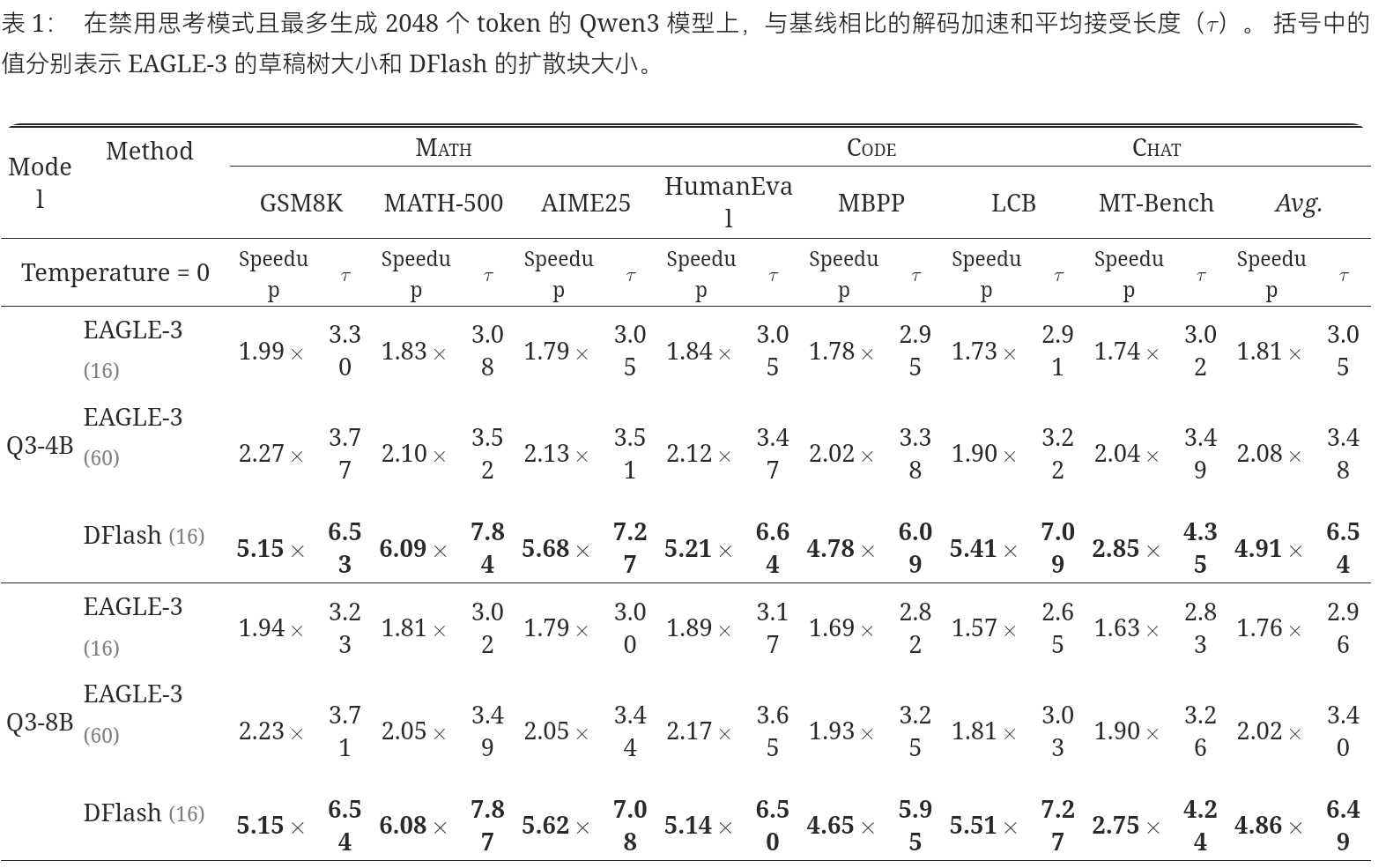
DFlash 而是为推测解码设置量身定制了块构建。 我们从响应中随机采样 锚定 token,将每个锚定作为块的第一个位置,并掩盖其余位置。 草稿模型被训练来并行预测下一个 \text {block_size}-1 token。 这直接匹配了推理时的行为,其中草稿模型始终以目标模型生成的干净 token 作为条件(即, 来自上一个验证步骤的奖励 token)。 随机化锚定位置也使草稿模型接触到更多样化的目标上下文特征,从而提高了数据效率和覆盖率。 如 Table 9 所示,该策略显著提高了接受长度和加速效果。
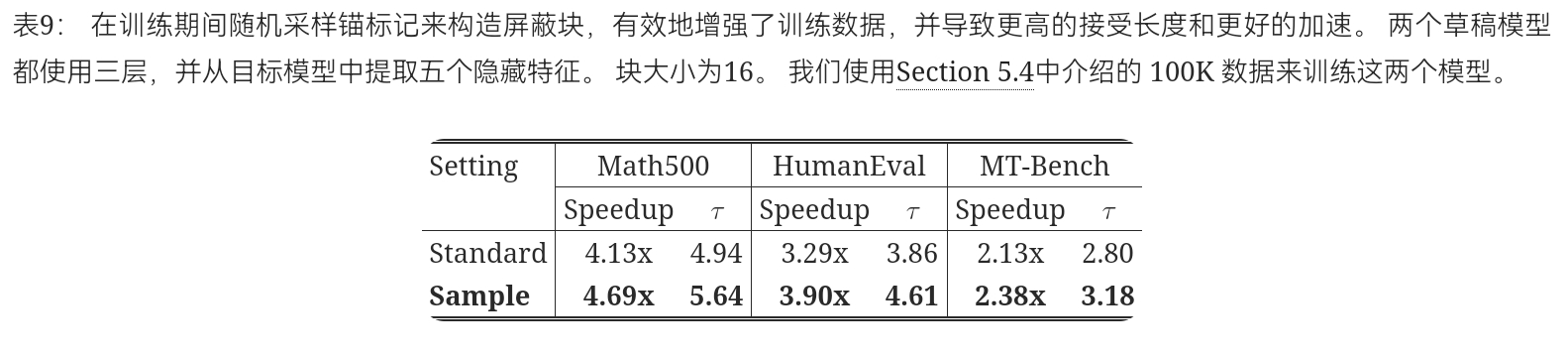
在训练期间,所有块被连接成一个单一序列,并使用稀疏注意力掩码联合处理,如 Figure 4 所示。 token 在同一块内进行双向关注,并关注相应的注入目标上下文特征,而不同块之间的注意力是不允许的。 这种设计使得多个草稿块能够使用 Flex Attention(Dong et al., 2024)在单个前向和后向传递中高效地进行训练。
高效的长上下文训练: 对于 EAGLE-3 等方法,由于其训练时的开销测试,在长上下文上训练推测草稿模型具有挑战性。 DFlash 通过固定每个序列的掩码块数量,并在每个 epoch 中为每个序列随机采样锚定位置,从而实现高效的长上下文训练。 这种策略在将训练成本限制在一定范围内时,提供了有效的数据增强。
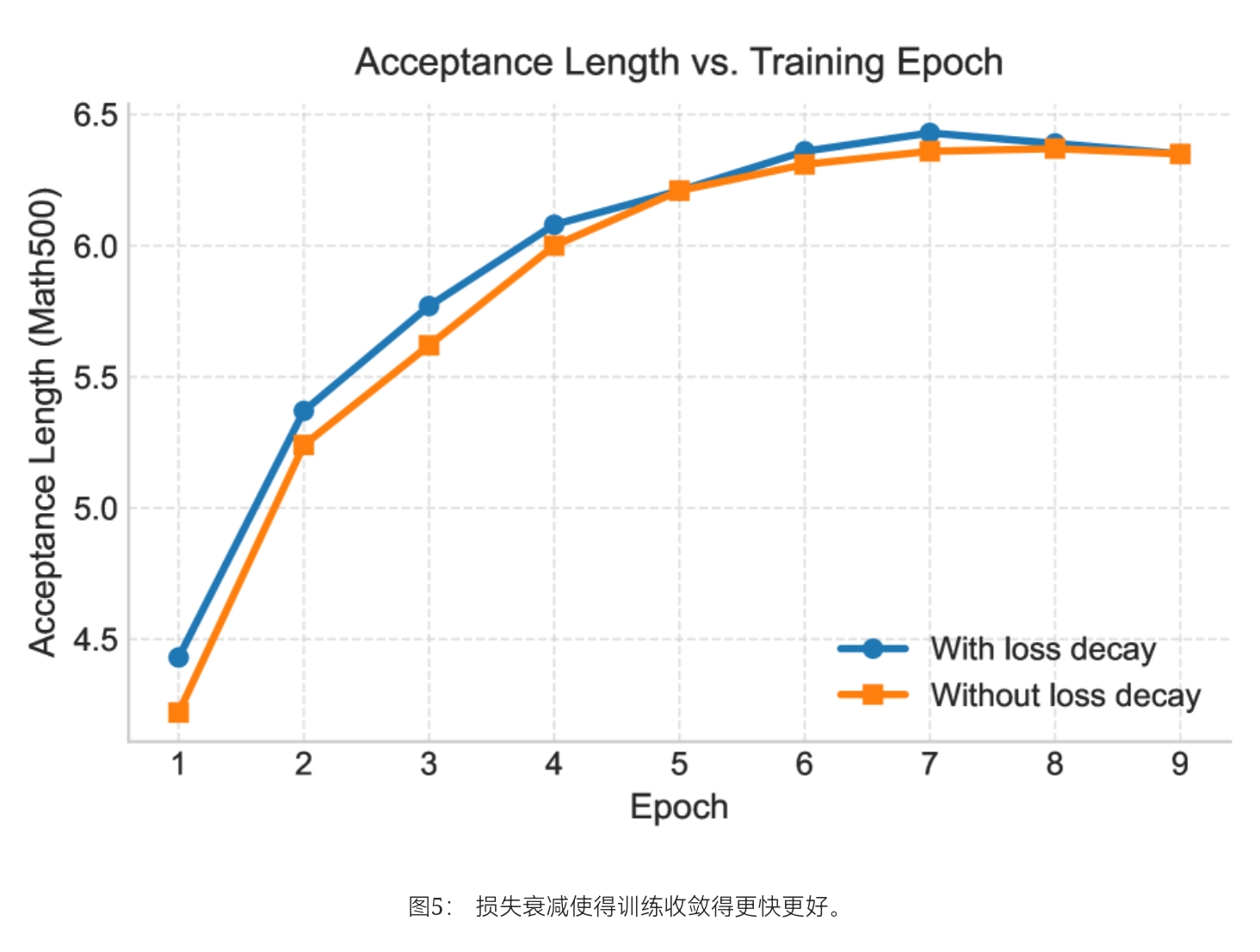
损失加权以加速收敛:在推测解码中,并非所有 token 都平等。 草稿块早期位置的错误会使所有后续 token 无效。 这使得早期预测在接受长度方面具有不成比例的重要性。 我们通过加权交叉熵损失来反映这种不对称性,以在训练期间强调早期的 token 位置。
具体来说,对于块内位置 k 的 token,我们应用指数衰减权重
w_{k}=\exp\left (-\frac {k-1}{\gamma}\right)
其中 \gamma 控制衰减率。 这种加权优先考虑早期位置,加速收敛并产生比均匀加权更高的接受长度(Figure 5)。
共享嵌入和 LM 头:为了提高训练效率,草稿模型与目标模型共享 token 嵌入层和语言模型头,并在训练期间保持冻结。 只有草稿 Transformer 层会被更新。 这种设计减少了可训练参数的数量,并鼓励草稿模型充当一个轻量级的扩散适配器,与目标模型的表示空间紧密对齐。
实验
模型和评估:我们在 LLaMA-3.1 Instruct (8B) 和 Qwen3 (4B, 8B, Coder-30B-A3B-Instruct) 预训练模型上进行实验。 我们在三个类别上评估任务:数学: GSM8K (Cobbe et al., 2021)、MATH (Lightman et al., 2023) 和 AIME25 (MAA, 2025);代码: HumanEval (Chen, 2021)、MBPP (Austin et al., 2021) 和 LiveCodeBench (Jain et al., 2024);聊天: MT-Bench (Zheng et al., 2023) 和 Alpaca (Taori et al., 2023)。 对于每项任务,我们使用平均接受长度 (\tau ) 和自回归基线上的端到端解码加速来评估草稿模型的性能。 除非另有说明,我们所有实验均在 NVIDIA H200 GPU 上进行。
数据集:为了提供多样化的训练数据集,我们从 NVIDIA Nemotron 训练后数据集 V2 (Nathawani 等人,2025) 和 CodeAlpaca (Chaudhary,2023) 收集了大约 800K 样本的混合物。 我们不是直接使用原始数据集,而是使用目标模型生成的响应构建训练集,以实现更好的目标对齐。
实施:对于 DFlash 草稿模型,我们将层数设置为 5(Qwen3 Coder 为 8),块大小为 16(LLaMA 3.1 为 10)。 目标隐藏特征是从目标模型的第二层到倒数第三层之间均匀选择的5层中提取的。 Section A.1 中介绍了更多培训细节。
基线:我们将 DFlash 与普通自回归解码(基线)和最先进的推测解码方法 EAGLE-3 (Li 等人,2025b) 进行比较。 由于缺乏开源实现,我们没有包括与其他基于 dLLM 的推测解码方法(Liu 等人,2025;Samragh 等人,2025;Li 等人,2025a;Sandler 等人,2025)的比较。 为了与 Qwen3 模型上的 EAGLE-3 进行比较(Section 5.1),我们使用 AngelSlim 发布的检查点(腾讯,2025);对于LLaMA-3.1-Instruct(Section 5.4.1),我们使用EAGLE-3团队发布的官方检查点。
Instruct Models
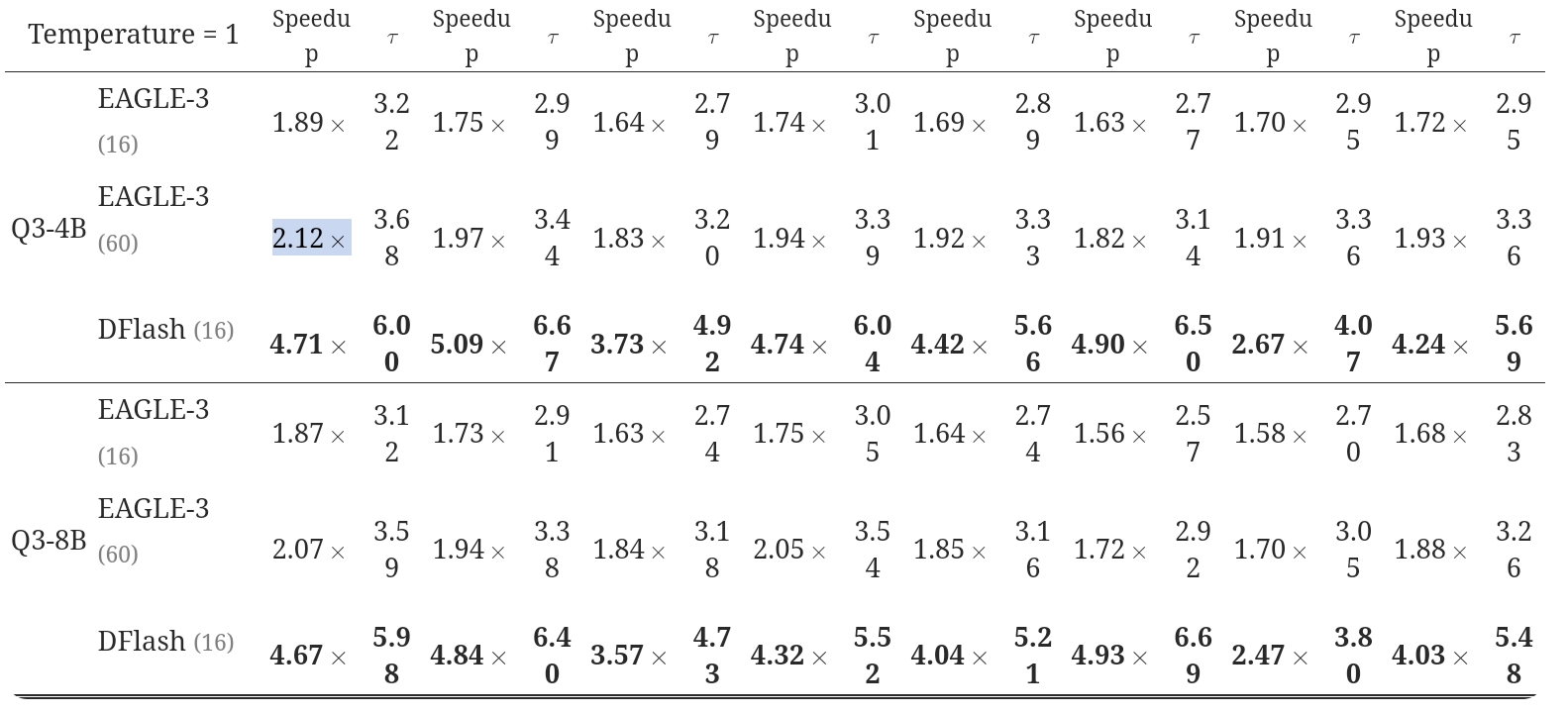
在本节中,我们将使用 Transformers 后端在禁用思维模式的 Qwen3 模型上针对 EAGLE-3 评估 DFlash。 对于 EAGLE-3,我们考虑两种设置:树大小为 16,它与块大小为 16 的 DFlash 相匹配,以进行公平的起草预算比较;树大小为 60,如 EAGLE-3 论文中使用的那样,以更高的验证成本最大化接受长度。 在这两种情况下,草稿步数和 top-k 分别设置为 7 和 10。
如 Table 1 所示,DFlash 在所有任务和设置下始终优于 EAGLE-3。 在贪婪解码(温度 = 0)下,DFlash 相较于自回归基线实现了 4.9\times 的平均加速,比 EAGLE-3(16)提升了 2.4\times。 在非贪婪采样(温度 = 1)下,DFlash 相较于基线仍有 4.1\times 的加速,相较于 EAGLE-3 有 2.2\times 的提升。 值得注意的是,DFlash 在树大小为 60 时也超过了 EAGLE-3,实现了更高的接受长度,同时带来了显著更低的验证开销。 这些结果证明了 DFlash 中基于扩散的草稿机制的有效性和效率。
Reasoning Models
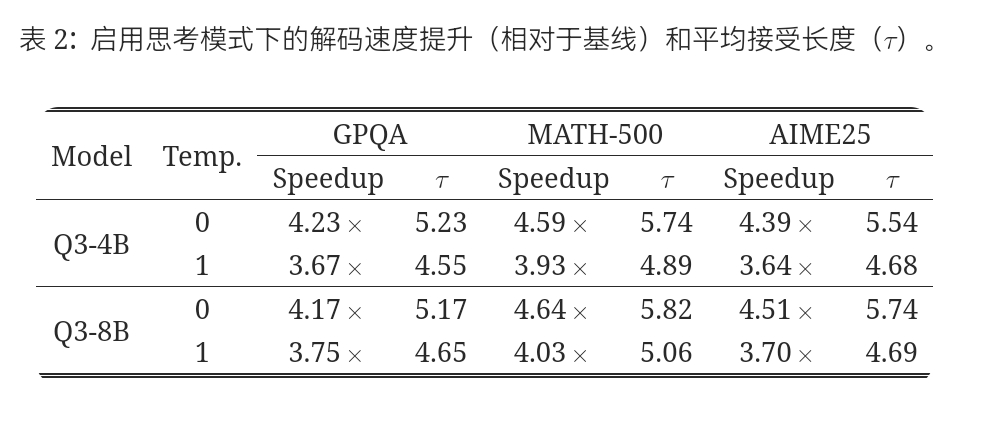
在本节中,我们使用 Transformers 评估了在启用思考模式的 Qwen3 模型上的 DFlash。 草稿模型在带有推理轨迹的目标模型输出上进行训练。
如 Table 2 所示,DFlash 保持了高接受长度,相较于基线实现了约 4.5\times 和 3.9\times 的加速。 鉴于推理模型的生成时间较长,这种效率的提升对于其在实际部署中的应用尤为宝贵。
Comments NOTHING