
大数据拓展篇
大数据的特点:5V
- 大规模volume
- 高速度Velocity
- 多样化 Variety
- 价值密度低 Value
- 真实性 Veracity
大数据的应用领域:制造业的应用、服务业的应用、交通行业的应用、医疗行业的应用等。
大数据面临着5个主要问题,分别是异构性、规模、时间性、复杂性和隐私性。
大数据的研究工作面临5个方面的挑战:
- 挑战一:数据获取问题
- 挑战二:数据结构问题
- 挑战三:数据继承问题
- 挑战四:数据分析、组织、抽取和建模是大数据本质的功能性挑战
- 挑战五:如何呈现数据分析的结果,并与非技术的领域专家进行交互
大数据分析的分析步骤大致分为五个主要阶段:
- 数据获取/记录【实时数据+离线数据】
- 信息抽取/清洗/标注
- 数据集成/聚集/表现
- 数据分析/建模
- 数据解释
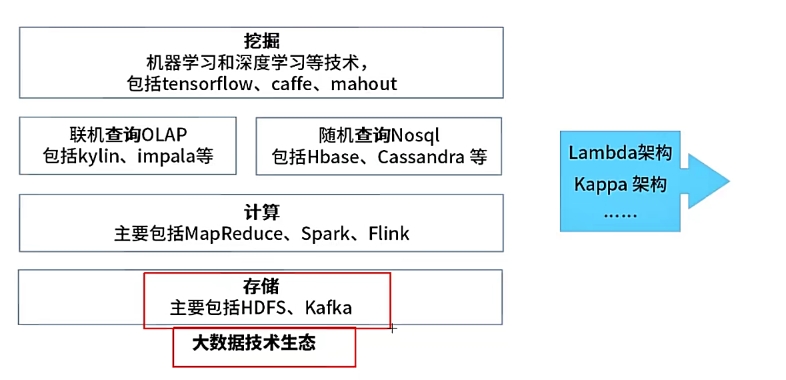
Hbase:分布式、面向列的开源数据库,适合于非结构化数据存储【实时数据和离线数据均支持】
HDFS(Hadoop分布式文件系统):适合运行在通用硬件上的分布式文件系统。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用【通常用于处理离线数据的存储】
Flume:高可靠/可用,分布式海量日志采集、聚合和传输的系统。Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据的简单处理,并写到各种数据接受方(可定制)的能力。
Kafka:一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。
ZooKeeper:开放源码的分布式应用程序协调服务,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
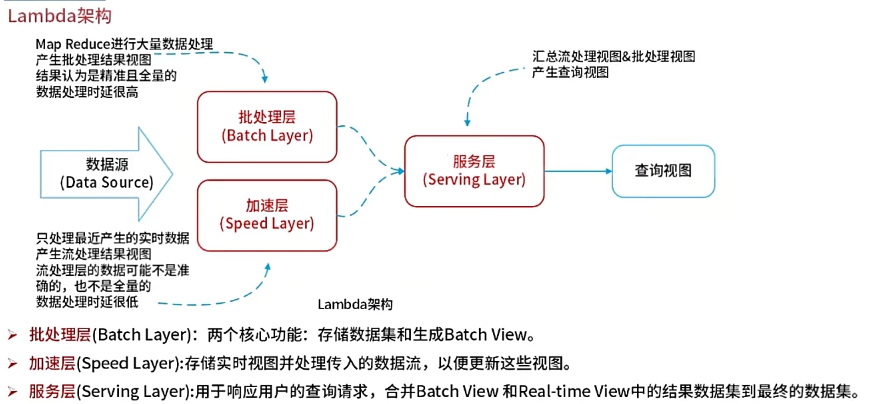
Lambda架构的优缺点:
| 优点 | 缺点 |
|---|---|
| 容错性好 查询灵活度高 易伸缩 易拓展 |
全场景覆盖带来的编码开销 针对具体场景重新离线训练一遍益处并不大 重新部署和迁移成本很高 |
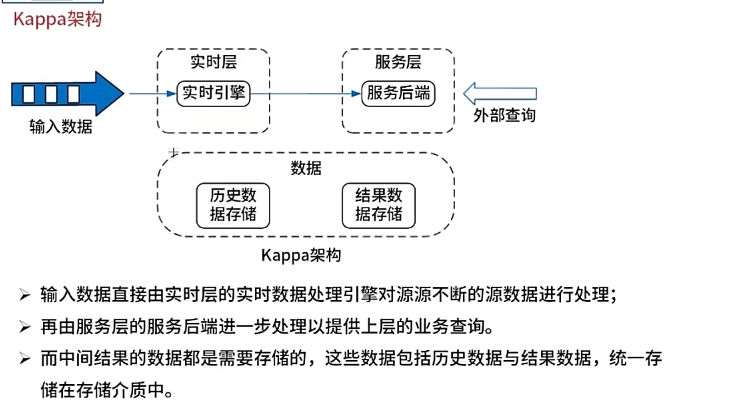
Kappa架构的优缺点
| 优点 | 缺点 |
|---|---|
| 将实时和离线代码统一起来了 方便维护而且统一了数据口径 避免了Lambda架构中与离线数据合并的问题 |
消息中间件缓存的数据量和回溯数据有性能瓶颈 在实时数据处理时,遇到大量不同的实时流进行关联时,非常依赖实时计算系统的能力,很可能因为数据流先后顺序的问题,导致数据丢失 Kappa在抛弃了离线数据处理模块的时候,同时抛弃了离线计算更稳定更可靠的特点 |
| 对比内容 | Lambda架构 | Kappa架构 |
|---|---|---|
| 复杂度与开发维护成本 | 需要维护两套系统(引擎),复杂度高,开发、维护成本高 | 只需要维护一套系统(引擎),复杂度低,开发、维护成本低 |
| 计算开销 | 需要一直运行批处理和实时计算,计算开销大 | 必要时进行全量计算,计算开销相对较小 |
| 实时性 | 满足实时性 | 满足实时性 |
| 历史数据处理能力 | 批式全量处理,吞吐量大,历史数据处理能力强 | 流式全量处理,吞吐量相对较弱,历史数据处理能力相对较弱 |
| 使用场景 | 直接支持批处理,更适合对历史数据分析查询的场景,期望尽快得到分析结果,批处理可以更直接高效的满足这些需求 | 不是Lambda的替代架构,而是简化,Kappa放弃了对批处理的支持,更擅长业务本身为增量数据写入场景的分析需求 |
选择依据:
- 根据两种架构对比分析,将业务需求、技术要求、系统复杂度、开发维护成本和历史数据处理能力作为选择考虑因素。
- 计算开销虽然存在一定差别,但是相差不是很大,所以不作为考虑因素。
Comments NOTHING