
近端策略优化算法PPO(Proximal Policy Optimization)
PPO算法在openai的论文《Training language models to follow instructions with human feedback》提出的RLHF范式中使用,用于对其人类偏好。
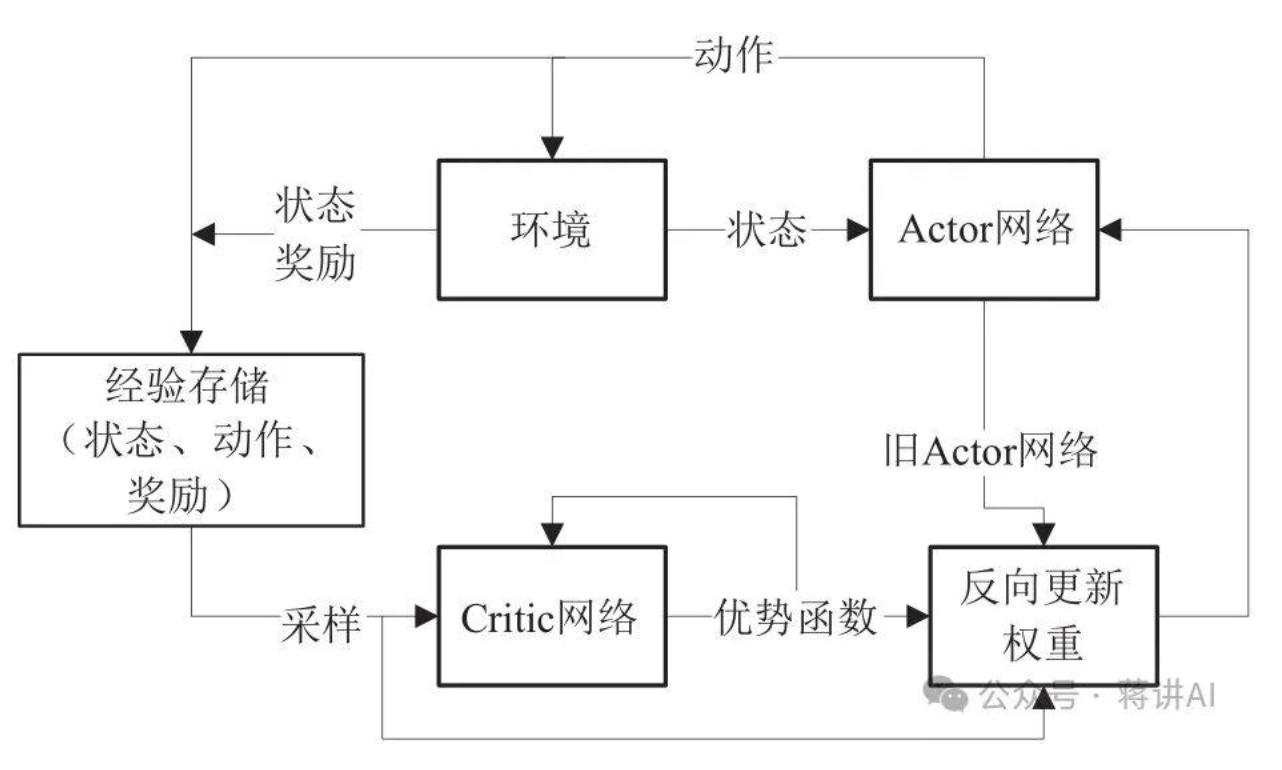
PPO算法模型构成
其中,针对RLHF场景中的PPO算法一共存在四个模型:策略模型(policy model)、奖励模型(value model)、参考模型(reference model)以及critic模型。
- 策略模型:又称Actor,当前需要训练的“学生”模型,即目标的语言模型。接收用户输入的指令(prompt),生成对应的响应。通过与环境(即奖励模型)交互,学习优化生成策略,以最大化奖励信号。
- 奖励模型:“裁判”模型,评估生成内容的质量,对“指令-响应”进行评分,输出标量奖励指(如回答的有用性、无害性)。评分基于人类偏好数据巡林啊,例如人工标注的优质回答排序。参数冻结,不参与训练更新。提供优化方向,将模糊的“人类偏好”量化为可计算的奖励
- 参考模型:即SFT训练后得到的模型,将其作为“不变”的基准,防止策略偏离初始能力。约束公式为:最终奖励=奖励模型分-α×KL散度(α为惩罚系数)
- 批评家模型:动态的“评论家”,预测未来累积奖励。输入指令(状态),预测当前策略下未来能获得的总奖励期望值。用于计算优势函数(Advantage),衡量当前动作比平均表现好多少。与策略模型同步更新,通过最小化预测值与实际回报的均方误差(MSE)优化。减少奖励信号的方差,提升训练稳定性。
直接策略优化算法DPO(Directly Policy Optimization)
现有的大模型的对齐方法,例如PPO,往往程序复杂且稳定性不足,通常需要先你和一个能够反映人类偏好的奖励模型,然后通过强化学习来微调大模型,同时要确保模型行为不会过分偏离其原始状态。
相比之下,DPO算法简化该流程,无需训练专门的奖励模型,而是利用简单的分类损失来解决标准的PLHF(基于人类反馈的强化学习)问题。DPO不仅算法稳定、性能优良,而且计算量较小。
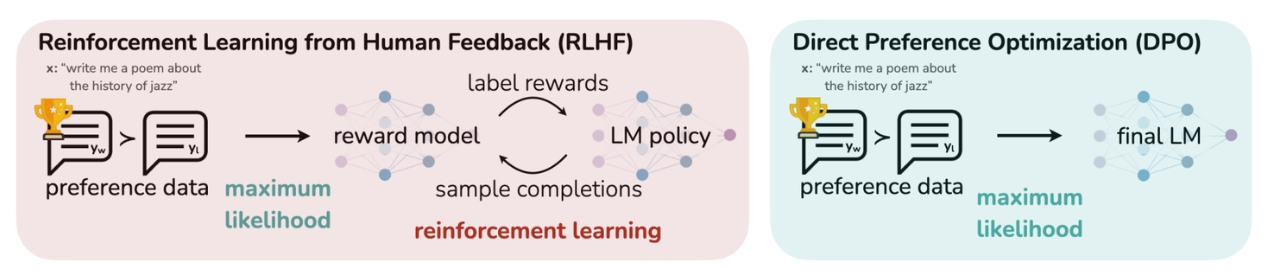
DPO算法仅包含RLHF中的两个模型,即演员模型(Actor model)和参考模型(Reference model),且训练过程中不需要进行数据采样。
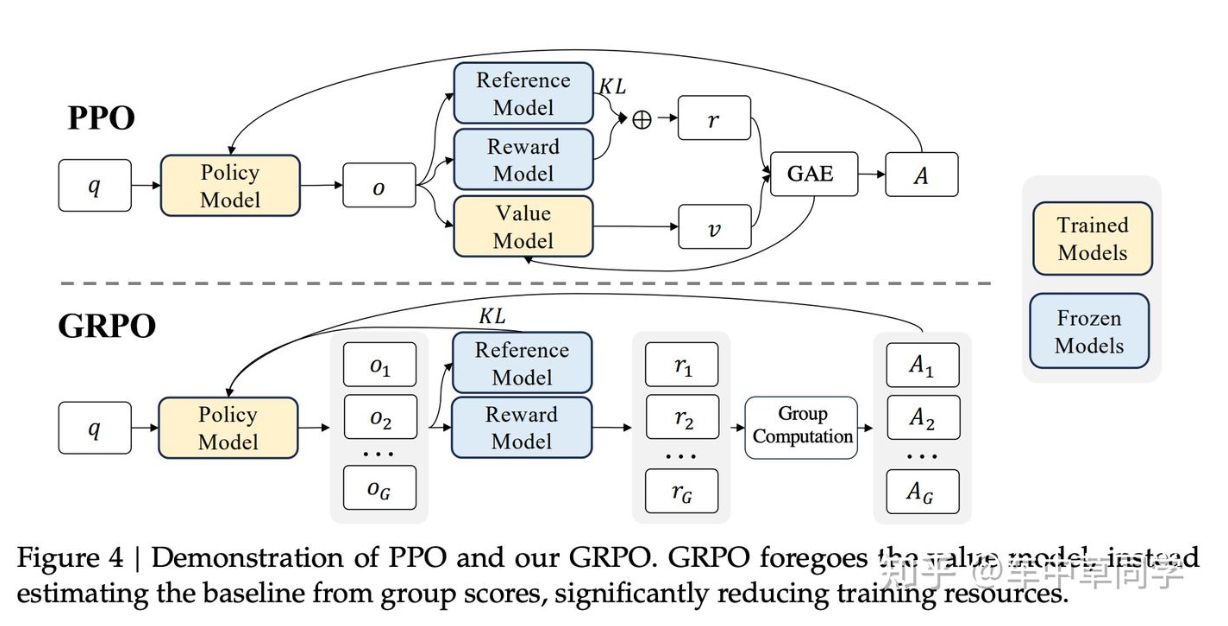
组间相对策略优化算法GRPO(Group Relative Policy Optimization)
GRPO摒弃了价值函数模型的训练,二是通过组内奖励分数来评估基准线(advantage),大幅降低了训练资源的需求。GRPO首先根据问题q,生成一组回答(o1,...,oG),然后问题+回答输入Reference模型,并与Policy模型计算KL散度,约束Policy模型的更新幅度。此外,问题+回答输入Reward模型中输出一组奖励分数(r1,...,rG),与PPO显著不同的是,GRPO使用这一组奖励分数来估算A,具体公式为:
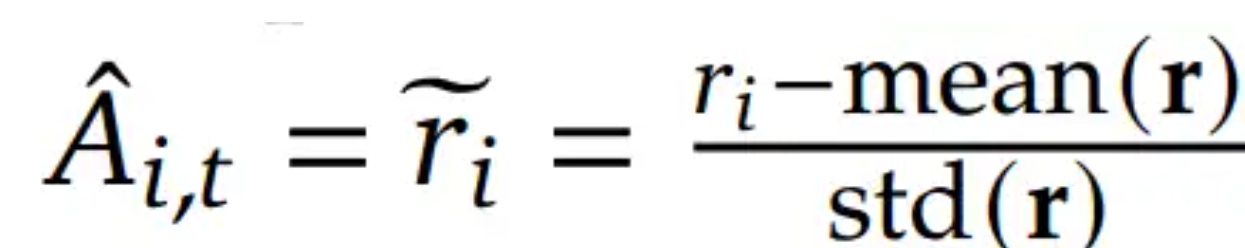
Comments NOTHING