
Meta Data
- 发表时间 2025.04.23
- 作者:Fan Zhou, Siqiao Xue, Danrui Qi etc.
- 论文链接:https://arxiv.org/abs/2503.01840
- 项目链接:https://github.com/SafeAILab/EAGLE
Abstract
现代 llm 的顺序性使其昂贵且缓慢,推测采样已被证明是该问题的有效解决方案。像 EAGLE这样的方法在特征级别执行自回归,重用目标模型的顶层特征,以取得比普通的推测采样更好的结果。LLM 社区的一个日益增长的趋势是扩大训练数据,以在不增加推理成本的情况下提高模型智能。然而,我们观察到扩展数据对 EAGLE 的改进有限。发现这种限制来自 EAGLE 的特征预测约束。本文提出了 EAGLE-3, 放弃了特征预测而是直接进行 token 预测,并通过一种名为训练时间拓展(Training-Time Test)的技术,将对顶层特征的依赖替换为多层特征融合。这些改进显著提高了性能,并使草案模型能够充分受益于扩大训练数据。实验包括聊天模型和推理模型,在五个任务上进行了评估。实验结果表明,与 EAGLE-2 相比,EAGLE-3 的加速比最高可达 6.5x, 提升约 1.4 倍。在 SGLang 框架中,当批量大小为 64 时,EAGLE-3 实现了 1.38 倍的吞吐量提升。代码可以在https://github.com/SafeAILab/EAGLE上找到。
Introduction
现代大型语言模型 (llm) 正被应用于更多领域,其能力提升由模型参数扩展驱动 —— 部分 LLM 参数已超千亿。自回归生成中,每个令牌需访问全部模型参数,导致 LLM 推理缓慢且昂贵。
近期,测试时间增加受到广泛关注。ChatGPT o1、DeepSeek-R1 (Guo et al., 2025) 等模型在响应前执行深思推理,以更长推理时间为代价提升 LLM 能力边界。但这类模型推理过程漫长、成本极高,响应时间增加严重影响用户体验。这类推理模型显著推高 LLM 全流程推理成本,推动研究者探索更廉价、快速的推理优化方法。
推测采样方法可通过部分并行化生成过程降低 LLM 延迟。该方法快速生成草稿 token, 再并行验证,允许一次前向传递生成多个令牌,显著降低延迟。普通推测采样中,草案模型是独立小型 LLM, 通常为目标模型同系列低参版本,独立运行。与普通推测采样不同,EAGLE (Li et al., 2024c) 重用目标模型顶层特征 (LM 头前特征), 训练草案模型自回归预测下一特征,再用目标模型 LM 头得到草案 token。借助目标模型丰富信息,EAGLE 实现优于普通推测采样的加速效果。后续 HASS (Zhang et al., 2024)、Falcon (Gao et al., 2024) 等方法也采用当前特征序列预测下一特征的思路。
当前 LLM 愈发依赖更大训练数据集提升性能。例如,7B (8B) 规模 LLaMA 系列模型分别使用 LLaMA 1 (Touvron et al., 2023a)、LLaMA 2 (Touvron et al., 2023b)、LLaMA 3 (Dubey et al., 2024) 的 1T、2T、15T 训练数据 token, 在模型架构与推理成本基本不变的前提下,各项指标显著提升。本文同样尝试扩大 EAGLE 训练数据以提高接受率与加速比,但发现额外数据对 EAGLE 增益有限。本文分析其原因:如图 3 上半部分,EAGLE 在特征级执行自回归预测,先预测下一特征,再将特征输入目标模型 LM 头得到 token 分布。EAGLE 损失函数包含两部分:特征预测损失 l_{\text {fea}} 与token 预测损失 l_{\text {token}}。特征预测损失使仅在步骤1训练的草案模型能适配步骤2并获得多步预测能力。
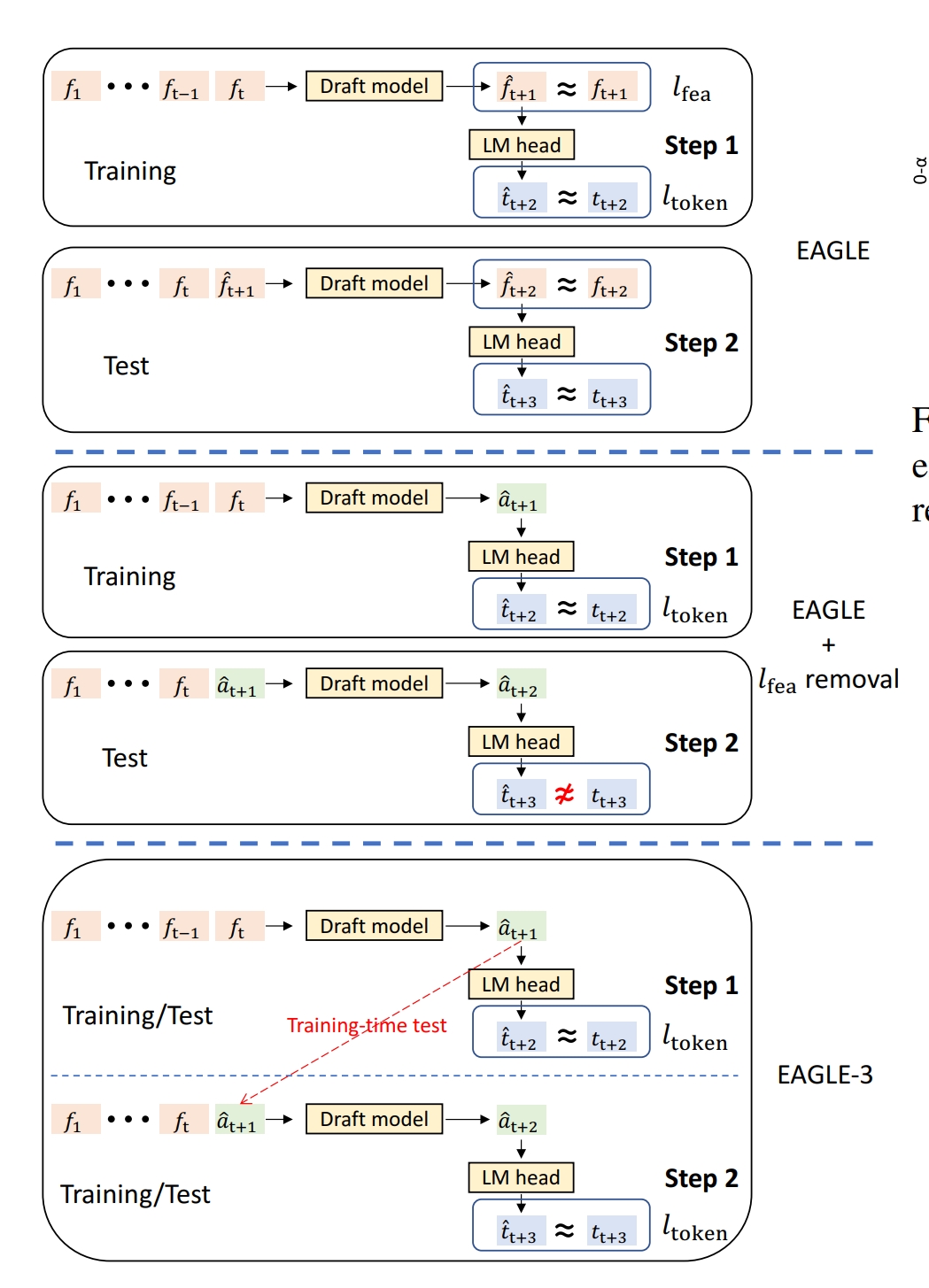
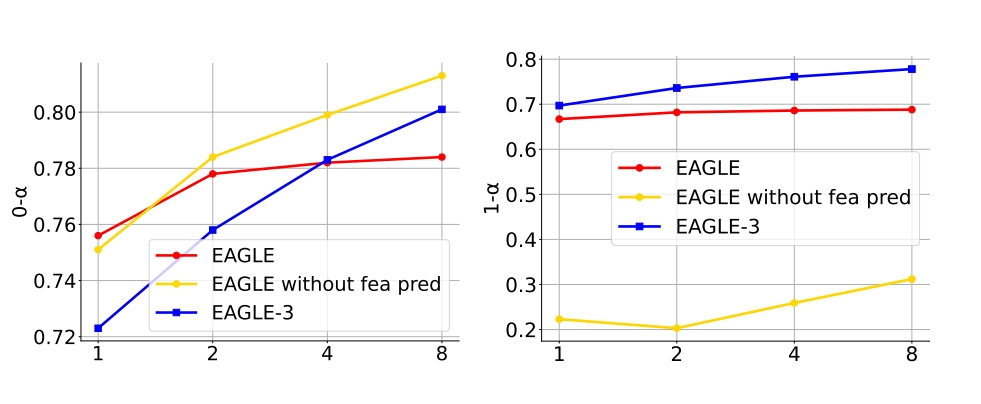
但以 token 预测为最终目标时,特征预测可视为额外约束,限制草案模型表达能力,使其难以从数据扩展中获益。移除特征约束并扩展训练数据后 (图 3 中部), 如图 4 所示,初稿 token 接受率 0\text {-}\alpha 显著提升。但步骤 1 草案模型输出 \hat {a}{t+1} 与真值 f{t+1} 偏差较大,导致步骤 2 输入序列 f_1,f_2,\cdots,f_t,\hat {a}_{t+1} 明显偏离训练分布,使第二步草案 token 接受率 1\text {-}\alpha 极低 (图 4)。将步骤 1 并入训练过程可解决该问题 (图 3 底部), 使扩大训练数据的收益更明显,该技术命名为训练时间测试。
EAGLE、Medusa (Cai et al., 2024) 等推测采样方法重用目标模型顶层特征 (尤其 LM 头前特征)。对满秩权重矩阵 LM 头,对应下一个 token logits 的顶层特征唯一,确保特征信息与下一个 token logits 直接对齐。但仅基于顶层特征预测下一个 token—— 这类特征天然局限于下一个 token—— 构成重大挑战。幸运的是,训练时间测试技术允许使用中间层特征,而非仅依赖顶层,因训练期间已移除特征预测损失 l_{\text {fea}}。
综上,本文提出 EAGLE-3, 为 EAGLE 增强版,实现显著加速。EAGLE-3 并行化设计,完全兼容 EAGLE-2 (Li et al., 2024b) 的绘图树技术。主要贡献:
草案模型新训练时间测试架构:训练中模拟多步生成,移除特征预测约束,直接预测 token。直接 token 预测为草案模型输入提供完全灵活性。融合利用目标模型低、中、高层特征,捕获多维度丰富语义信息,而非仅复用顶层特征。
发现 LLM 推理加速缩放律:新架构下,扩大草案模型训练数据量使 EAGLE-3 加速比成比例提升,该缩放行为在原始 EAGLE 架构中未被观察到。
推理加速优化:EAGLE-3 使用约 8 倍于 EAGLE 的数据训练,批量大小为 1 时较 EAGLE-2 实现 1.4 倍延迟加速。推测采样通常被认为在大批量下降低吞吐量,但在生产级框架 SGLang (Zheng et al., 2024) 中,EAGLE-3 在批量大小 64 时仍将吞吐量提升 40%。预计更大数据量可进一步提升加速比。
Preliminaries
投机抽样(Speculative Sampling)
推测采样 (Leviathan et al., 2023; Chen et al., 2023; Sun et al., 2024c,b) 是一种无损 LLM 加速技术,在起草和验证之间交替进行,其中起草以低成本执行,验证是并行的,分别对应于草案的生成和验证过程。我们使用 t_{i} 来表示 i-th 标记,使用 T_{a: b} 来表示标记序列 t_{a}, t_{a+1}, \cdots, t_{b}。当使用 T_{1: j} 作为前缀时,推测抽样的两个阶段如下。
在起草阶段,推测采样利用草案模型 (与目标模型相同系列的较小版本) 来自动回归生成 k token 以形成草案 \hat {T}_{j+1: j+k}, 同时也记录每个令牌的概率 \hat {p}。
在验证阶段,推测抽样调用目标模型对草案进行评估 \hat {T}{j+1: j+k} 并记录其概率 p。然后,投机性抽样从前到后依次确定草案token的接受情况。对于令牌 \hat {t}{j+i}, 接受的概率由 \min\left (1, \frac {p_{j+i}(\hat {t}{j+i})}{\hat{p}{j+i}(\hat{t}{j+i})}\right) 给出。如果令牌被接受,则进程移动到下一个令牌。否则,将从分布 \text {Normal}\left (\max\left (0, p{j+i}-\hat{p}{j+i}\right)\right) 中采样一个令牌来替换 \hat {t}{j+i}, 并丢弃草案中剩余的令牌。(Leviathan et al., 2023) 的附录 A.1 证明了推测抽样与 vanilla 自回归解码的分布一致。
EAGLE and EAGLE-2
能力有限的模型草案难以精确逼近大规模目标模型。EAGLE 利用目标模型的顶层特征作为附加信息,并在特征级别执行自回归,简化了起草过程。EAGLE 在特征级别执行自回归,然后使用目标模型的 LM 头来获得草案 token。由于 token 层的采样结果被隐藏,特征级自回归引入了不确定性。EAGLE 通过将前一个时间步长的 token 序列 (即采样结果) 输入到草案模型中来解决这个问题。与 Vanilla 投机采样的链式草稿不同,EAGLE 在同一位置生成多个草稿token,导致树形草稿。在验证阶段,EAGLE 使用树注意力对草案树进行并行化验证。有趣的是,EAGLE 启发了用于 DeepSeek-v3 预训练的多 token 预测技术 (Liu et al., 2024a), 这反过来又启发了 EAGLE-3 的新架构设计。
EAGLE (Li et al., 2024c) 和 Medusa (Cai et al., 2024) 等人使用树状草稿,其中草稿树的结构是预定义的、静态的和上下文无关的。起草的难度与上下文密切相关,静态的草案树可能会导致资源浪费。EAGLE-2 (Li et al., 2024b) 使用草案模型的置信度估算接受率,并基于此动态生成草案树,在起草阶段结束时执行草案树的修剪。EAGLE-3 还采用了 EAGLE-2 中提出的上下文感知的动态草案树。
EAGLE-3
在本节中,我们将详细描述 EAGLE-3 的实现。
推理流水线
与其他推测抽样方法一致,EAGLE-3 在起草和验证阶段交替进行。EAGLE-3 和 EAGLE 的区别在于起草阶段,我们用一个例子来介绍,如图 5 所示。以前缀 “How can” 为例。在预填充阶段或之前的验证阶段,目标模型执行正向传递以生成下一个令牌‘I’。我们从目标模型的前向传递中记录低、中和高级特征序列,分别记为 l、m 和 h。我们连接 k 维向量 l、m 和 h 以形成 3k 维向量,然后将其通过全连接 (FC) 层将其减少到 k 维,获得集成不同层信息的特征 g。这里,k 指的是目标模型的隐藏大小。
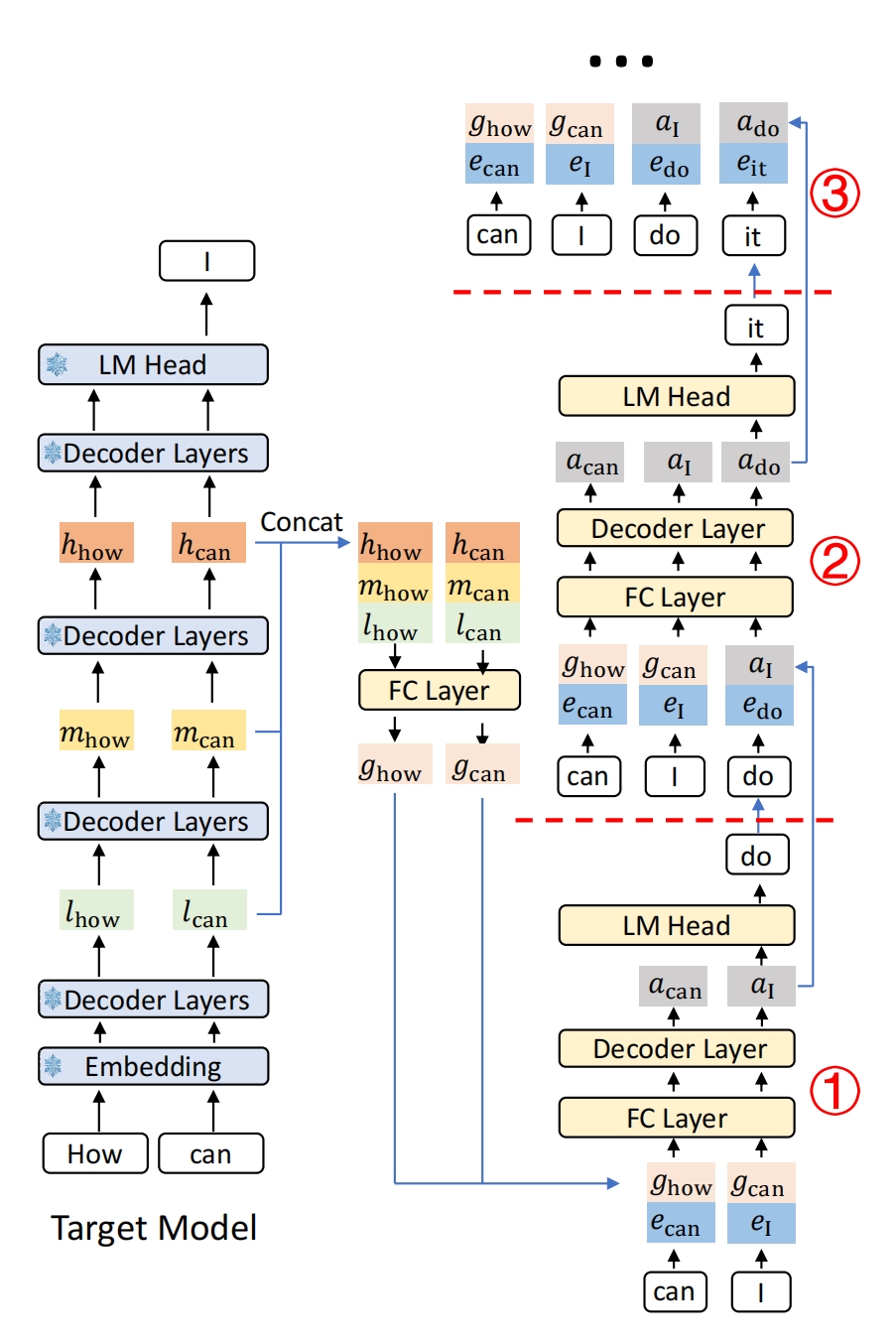
我们的目标是生成一个以 “How can I” 为前缀的 token 序列草案。由于只输入 g_{\text {how}} 和 g_{\text {can}}, 草稿模型无法访问随机抽样过程。因此,与 EAGLE (Li et al., 2024c) 类似,我们引入了采样 token‘I’的嵌入 e_{I}。然后,连接后的向量通过 FC 层将其维度降低到 k, 随后输入到单层解码器,产生输出 a。最后,我们将 a_{1} 输入到 LM 头并采样,以获得草案 token‘do’。
在步骤 1 中,使用前缀 “How can”, 我们从目标模型中重用 g_{\text {how}} 和 g_{\text {can}}。在第二步中,前缀变成了‘How can I’。理想情况下,我们将重用目标模型中的 g_{\text {how}} \cdot g_{\text {can}} 和 g_{I}。然而,这是不可能的,因为令牌‘I’还没有被目标模型检查,我们无法获得 g_{I}。相反,我们使用上一步中草稿模型的输出 a_{1} 来替换 g_{I}, 并将 a_{1} 与采样结果 “do” 的嵌入 e_{\text {do}} 连接起来,作为第 1 步中草稿模型的输入。在步骤 3 中,我们同样无法获得 g_{\text {do}}, 因此我们使用 a_{\text {do}} 作为替代将 a_{\text {do}} 与 e_{\text {it}} 连接起来作为草稿模型的输入。后续步骤也采用相同的方法。
草稿模型的训练
EAGLE 中的草稿模型的输入是目标模型的顶层特征 f_{1}, f_{2}, \cdots, f_{t}, 或者至少近似于顶层特征。相反,EAGLE-3 草案模型的输入可能包括来自目标模型的特性 g_{1}, g_{2}, \cdots, g_{t}, 也可能包括来自草案模型的输出 a_{t+1}, a_{t+2} \cdots, a_{t+j}。因此,我们需要训练草案模型以适应不同的输入。在训练过程中,我们执行测试步骤,在这里我们生成 a 并将其反馈给草稿模型以进行进一步训练。
EAGLE-3 草案模型的核心是 Transformer 解码器层。除了自注意力操作外,没有其他组件与上下文交互,因此在训练或测试期间不需要进一步修改。唯一需要稍微修改的组件是 self-attention, 我们将在下面详细描述。
虽然实际输入由特征组成,但为清晰起见,我们使用标记作为输入来描述这个过程。如图 6 所示,原始训练数据是一个长度为 3 的序列,‘How can I’, 在上下文中具有正常的序列依赖关系。因此,注意力模板是一个标准的下三角矩阵。在三个位置的输出是 “are”、“we” 和 “do”, 它们与 “how”、“can” 和 “I” 具有树状的上下文关系。因此,当输入 “are”、“we”、“do” 进入步骤 2 时,注意力掩码需要进行相应的调整,如图 6 右上角所示。除了使用原始训练数据作为键外,所有的注意力掩码都是对角线的。在这种情况下使用矩阵乘法会导致显著的计算浪费,因此我们可以使用向量点积来计算对应位置的注意力得分。
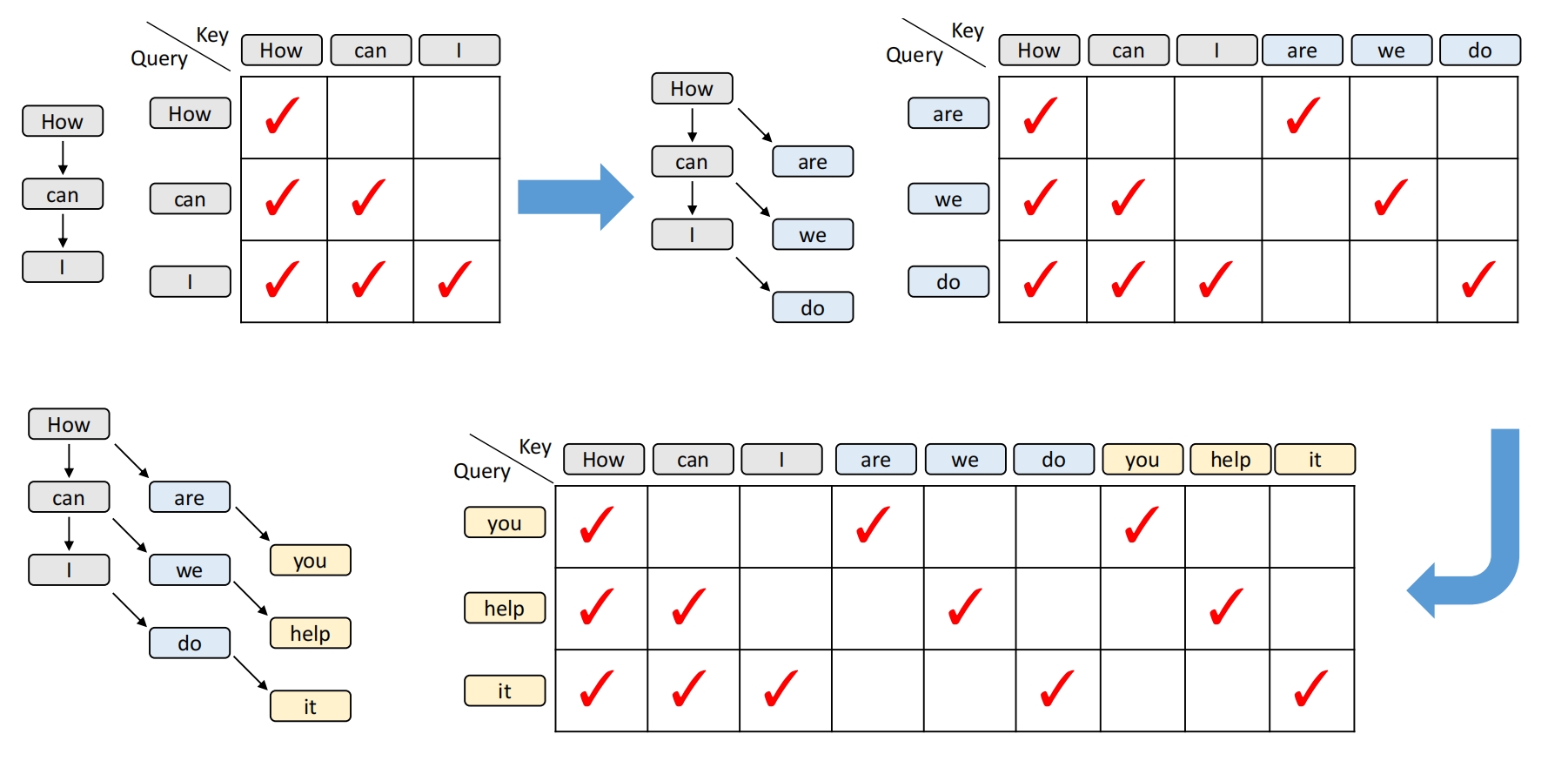
HASS (Zhang et al., 2024) 和 EAGLE-3 都对注意力机制进行了类似的修改,以模拟训练期间的测试过程,但这不是 EAGLE-3 的主要重点。两种方法的动机、方法和结果截然不同。HASS 背后的动机是减少 EAGLE 中不准确的特征预测造成的误差累积。HASS 仍然执行特征预测,包括特征预测损失 l_{\text {fea}}, 并且草案模型的输入必须是顶层特征。相比之下,EAGLE-3 背后的动机是消除不必要的约束,以增强模型的表达能力。EAGLE-3 不再需要草案模型的输出来拟合目标模型的顶层特征,从而避免了误差累积。去除特征预测后,EAGLE-3 的输入是完全自由的,取而代之的是来自不同层次语义信息的特征融合。特征预测损失的去除还使我们能够发现以前从未发现过的新的推理加速的尺度律。图 2 还显示了 EAGLE-3 和 HASS 的加速比,其中 EAGLE-3 表现出了明显更好的性能。
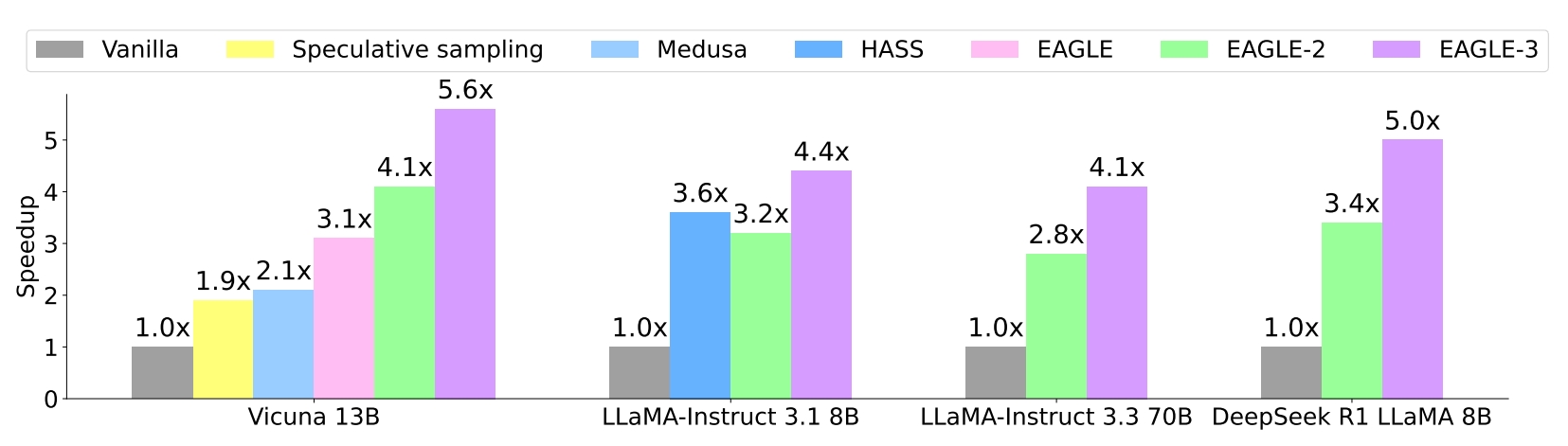
实验
模型。使用最先进的开源聊天和推理模型进行了实验,包括 Vicuna 13B (Chiang et al., 2023)、LLaMA-Instruct 3.1 8B、LLaMA-Instruct 3.3 70B (Dubey et al., 2024) 和 DeepSeek-R1-Distill-LLaMA 8B (Chen et al., 2021)。由于 GPU 的限制,我们无法在 405B 和 671B 模型上测试 EAGLE-3。
任务。在 EAGLE (Li et al., 2024c) 和 SpecBench (Xia et al., 2024) 之后,对五个常见任务进行评估,对所有任务使用相同的权重,而不对各自的任务进行微调。对于多轮对话、代码生成、数学推理、指令遵循和总结,我们分别选择了 MT-bench (Zheng et al., 2023), HumanEval, GSM8K (Cobbe et al., 2021), Alpaca (Taori et al., 2023) 和 CNN/Daily Mail (Nallapati et al., 2016) 数据集。
指标。EAGLE-3 不修改目标模型的权重,并使用严格的推测采样接受条件,确保不损失性能。因此,我们不评估生成质量。相反,我们使用以下指标来评估加速性能:
- 加速比(Speedup Ratio):相对于普通自回归解码的实际测试加速比。
- 平均接受长度(Average Acceptance Length)τ: 每个起草 - 验证周期生成的令牌的平均数量,它对应于从草案中接受的令牌数量。
- 接受率(Acceptance Rate)n-α: 草稿token被接受的比例直接反映了草稿模型与目标模型的近似程度。按照 EAGLE 的设置,我们在测试接受率时使用链式草稿而不是树形草稿。EAGLE 受到误差累积的困扰,这意味着草案模型的输入可能是它自己的估计,而不是来自目标模型的准确值。因此,EAGLE 使用 n-α 表示输入包含 n 估计特征时的接受率,前提是先前估计的 token 都被目标模型接受。换句话说,输入的接受率 f_{1}, f_{2}, \cdots, f_{i}, \hat {f}{i+1}, \cdots, \hat{f}{i+n}, 其中 f 是准确值,\hat {f} 是模型草案的估计。类似地当输入包含 n 自预测值 a 时,我们使用 n-α 来表示 EAGLE-3 中的接受率,即输入的接受率 g_{1}, g_{2}, \cdots, g_{i}, a_{i+1}, \cdots, a_{i+n}, 其中 g 是来自目标模型的融合特征。
实现。我们使用 AdamW 优化器,beta 值 (\beta_{1}, \beta_{2}) 设置为 (0.9,0.95) 并实现梯度裁剪为 0.5。学习率设置为 5e-5。我们使用 ShareGPT 和 UltraChat-200K (Ding et al., 2023) 作为训练数据,分别包含大约 68K 和 464K 数据项。我们调用目标模型来生成响应,而不是使用固定的数据集。对于推理模型 DeepSeek-R1-Distill-LLaMA 8B, 我们还使用 OpenThoughts-114k-math 数据集进行训练。
比较。我们使用普通的自回归解码作为基准,它作为加速比的基准 (1.00x)。我们将 EAGLE-3 与最近的无损推测采样方法进行了比较,包括标准推测采样 (Leviathan et al., 2023; Chen et al., 2023; Gante, 2023), PLD (Saxena, 2023), Medusa (Cai et al., 2024), Lookahead (Fu et al., 2024), Hydra (Ankner et al., 2024), HASS (Zhang et al., 2024), EAGLE (Li et al., 2024c), 和 EAGLE-2 (Li et al., 2024b)。
有效性
图 1 和表 1 展示了 EAGLE-3 的加速性能。在所有任务和目标模型上,EAGLE-3 实现了最高的加速比和平均接受长度。与 vanilla 自回归生成相比,EAGLE-3 提供了大约 3.0x-6.5 倍的加速,比 EAGLE-2 提高了 20%-40%。不同的任务会影响草案模型的接受率,因此平均接受长度和加速比都是与任务相关的。由于在代码生成任务中存在许多固定模板,生成草稿是最简单的,这就是为什么 EAGLE-3 在 HumanEval 上表现最好的原因,实现了高达 6.5 倍的加速比和高达 7.5 的平均接受长度。DeepSeek-R1-Distill-LLaMA 8B 是个例外,在数学推理数据集 GSM8K 上具有最高的加速比。这可能是因为我们使用 OpenThoughts-114k-math 数据集训练了 DeepSeek-R1-Distill-LLaMA 8B 的模型草案。
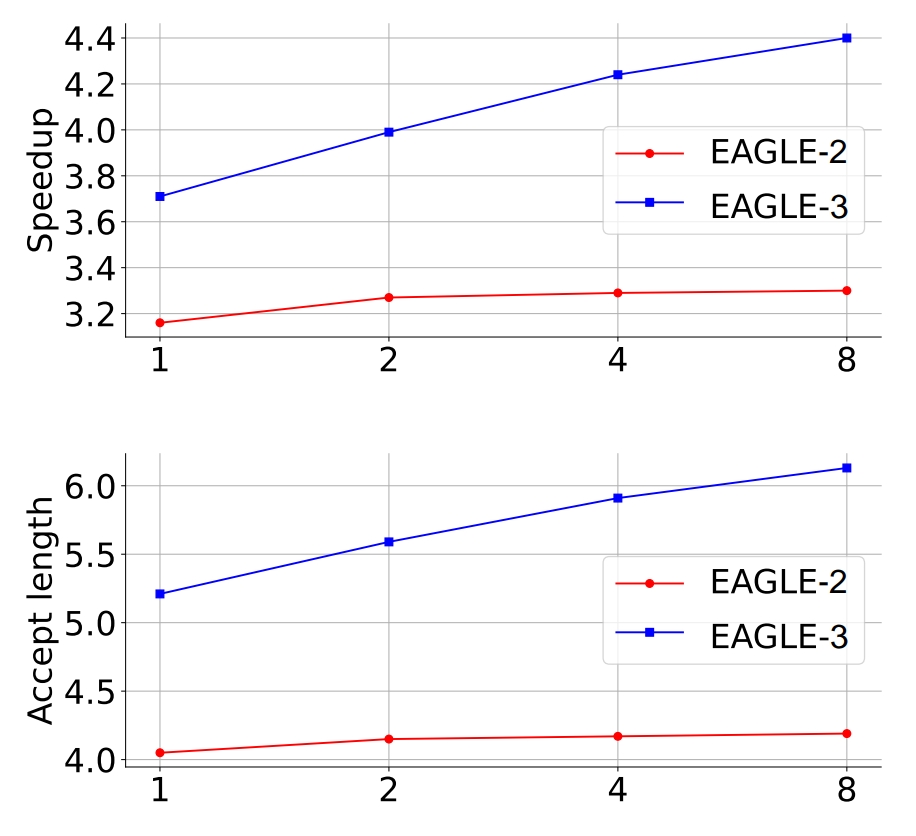
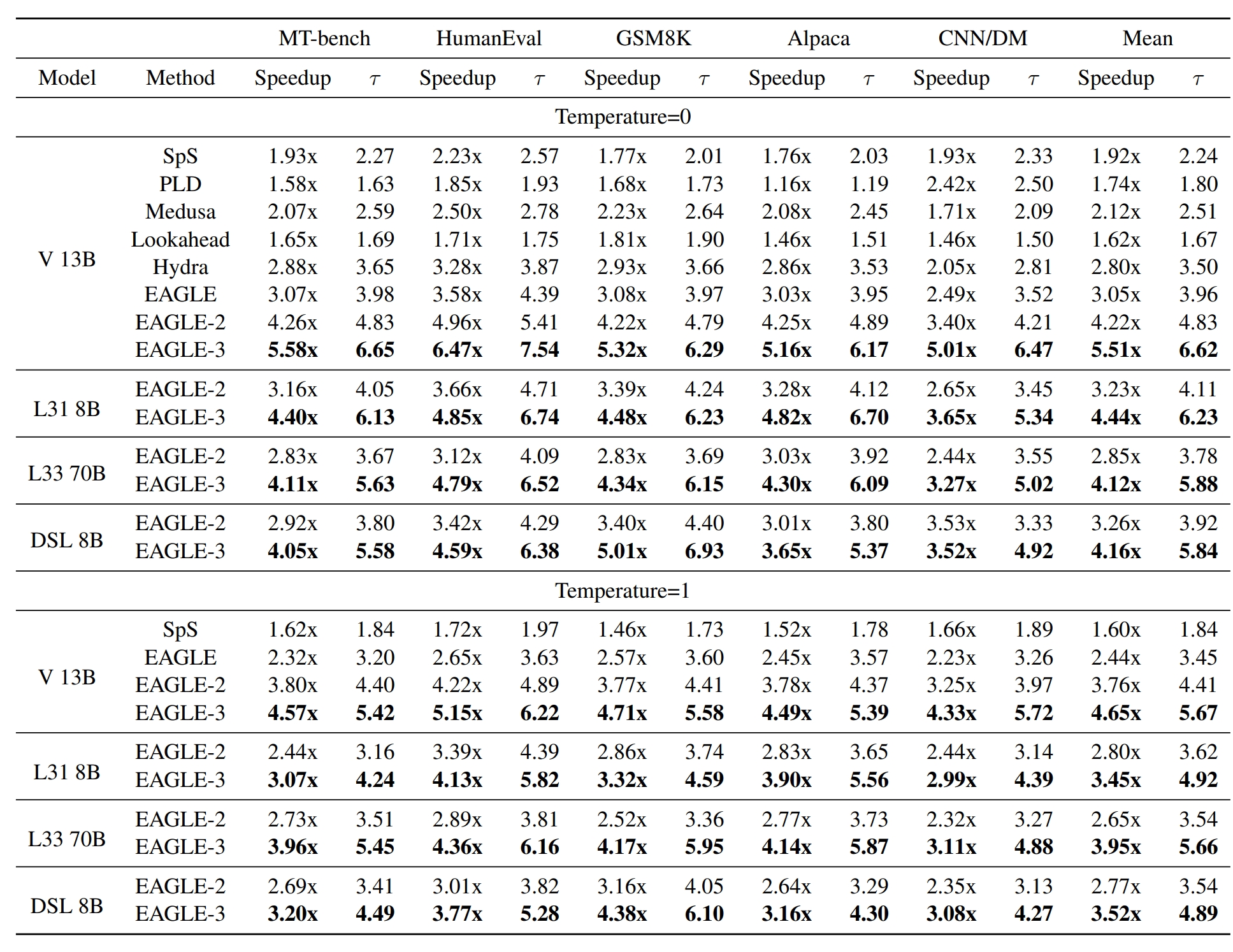
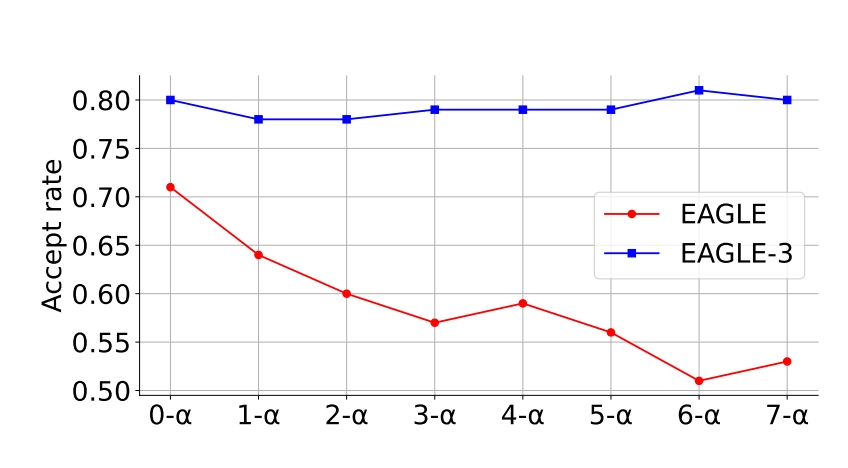
图 7 显示了以 LLaMA-Instruct 3.1 8B 为目标模型的 EAGLE 和 EAGLE-3 在 MT-bench 上的接受率。EAGLE-3 的录取率显著高于 EAGLE。随着草案模型本身的输入增加,EAGLE 的接受率显著下降,而 EAGLE-3 的接受率几乎保持不变,证明了训练时间测试的有效性。
Comments NOTHING