
为什么要创建flash-attention?
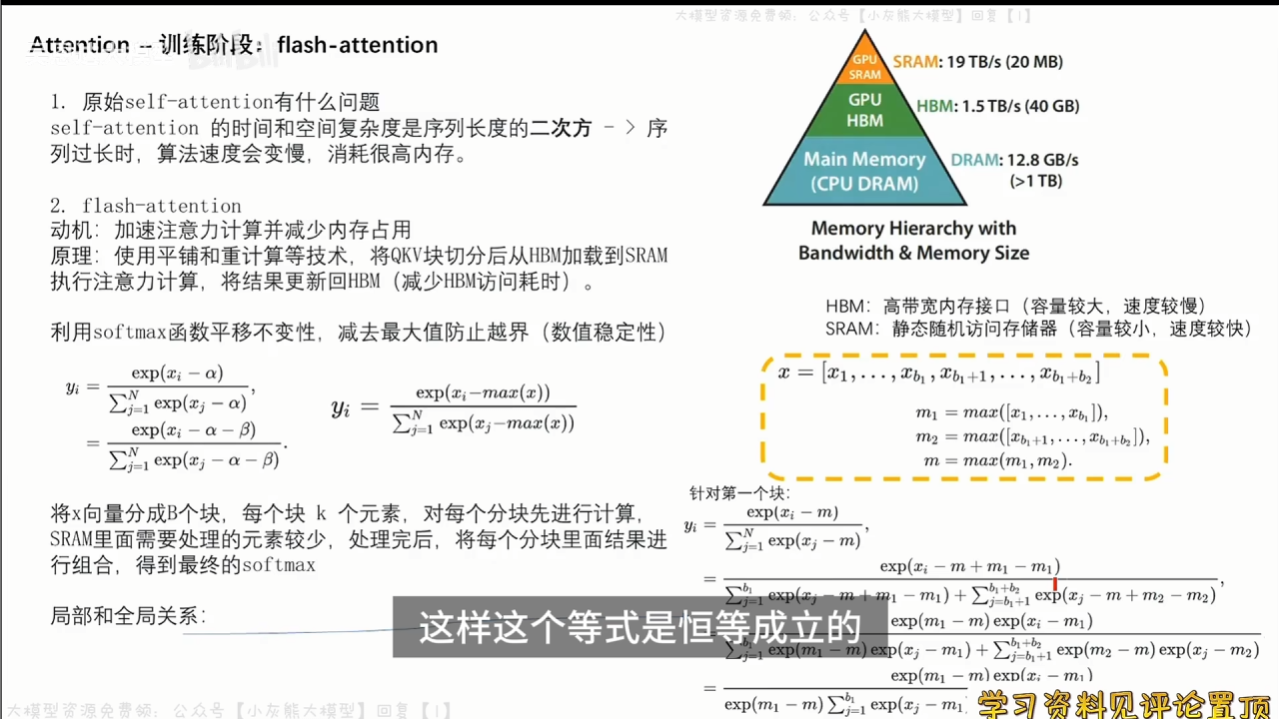
原始self-attention的时间和空间复杂度是序列长度的二次方,当序列长度过长时,算法速度会变慢,内存消耗变高。
flash-attention使用平铺和重计算等技术,将QKV块切分后从HBM加载到SRAM执行注意力计算,最后将结果更新会HBM,从而减少HBM访问耗时。
利用softmax函数的平移不变形,将x向量分为B个块,每个块K个元素,先对每个分块进行计算,SRAM里面需要处理的元素较少,处理完后,再将每个分块的结果进行组合,得到最终的softmax。
为什么要使用Kv-cache
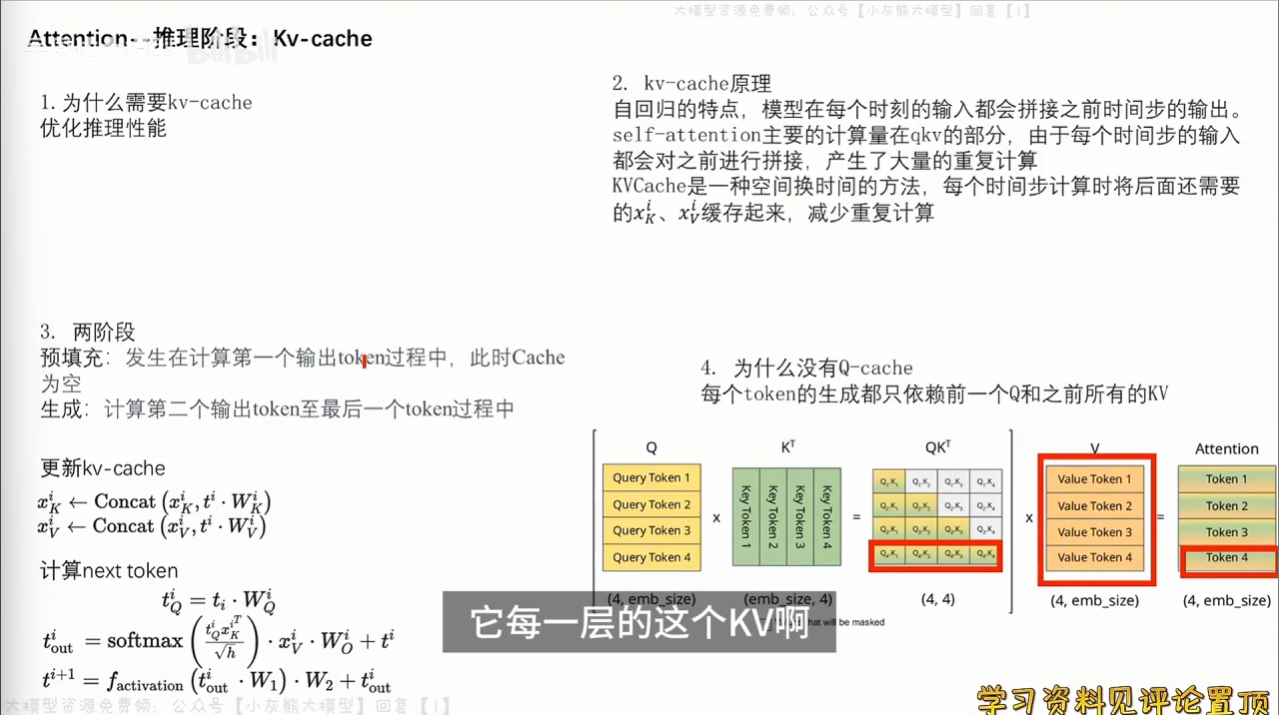
大模型为decode-only框架,自回归的特点决定了模型在每个时刻的输入都会拼接之前步长的输出,kv-cache使用以空间换时间的计算方法,每个时间步长计算时,将xk和xv进行缓存,从而减少同步计算。
每一个token在生成的时候,只依赖上一个时间步的Q和之前所有的KV,所以不需要Q-cache。
KV-cache显存占用计算公式为:
Seq_length*batch_size*[d_head*n_head]*layers*2*2
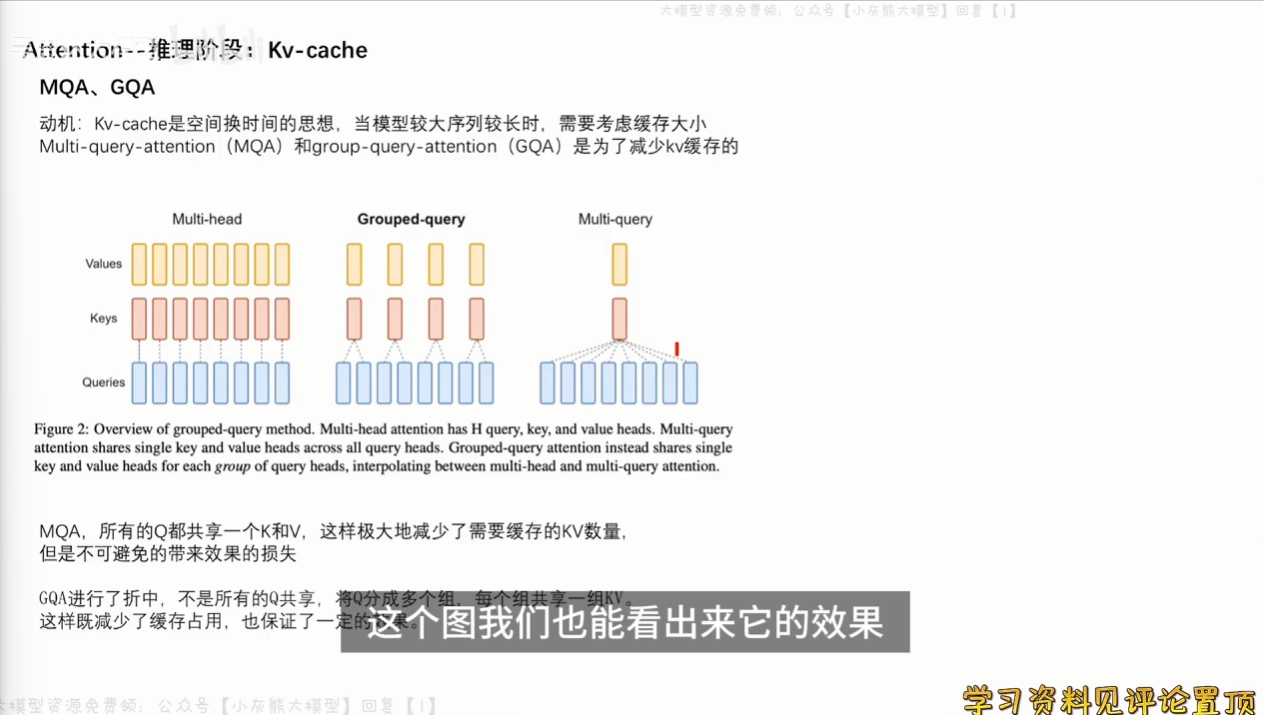
当模型较大序列较长时,需要考虑kv-cache的缓存大小,因此,MQA和GQA被提出,减少kv缓存。
在MQA中,所有的Q共享一套K和V,从而极大减少需要缓存的KV数量,但鱼刺同时带来效果损失
GQA进行了这种,不是所有的Q都共享,而是将Q进行分组,每组Q共享一组KV,这样既减少了缓存占用,也保证了一定的泛化能力,当前主流大模型都有使用GQA的思想。
为什么要进行量化
为了降低部署成本,但可能会带来一定的效果损失。
推理成本≈模型token的平均推理时间×功耗×电费。
按照量化的执行阶段划分,可以划分为训练中量化(QAT,Quantization-Aware-Training)和训练后量化(PTQ,Post-Training-Quantization),当前主流为PTQ的量化方法。
量化针对的主要对象包括:
- PTQ主要针对权重、激活值和KV Cache进行量化
- 仅权重量化,如AWQ和GPTQ中的W4A16,W8A16(权重量化为8位,激活值仍为BF16或FP16)
- 权重、激活值都量化,如smoothQuant中的W8A8
常见的参数精度包括:
fp32:单精度
fp16:半精度
为了FP16提高训练的效率和性能,同时避免精度溢出和舍入误差的影响,一般采用fp16和fp32混合精度训练。
主流的量化算法
GPTQ
发展历程包括:OBD(剪枝)->OBS(剪枝)->OBQ(量化)->GPTQ(量化)
OBD
- 网络训练完成后,通过泰勒展开二阶信息对网络进行剪枝,使得删除的参数对于结果影响最小。
- 计算每一个参数的二阶导数,进而计算出每个参数带来的损失函数增加值(delta E)
- 提出delta E较小的参数
- 认为每个参数对于损失函数带来的影响是独立的
OBS
- 认为参数之间独立性不成立,需要考虑交叉项
- 抹去一个权重w后,计算出补偿q应用于其他权重上,寻找方法(海森矩阵逆矩阵)使其对整体的误差值增加最少
OBQ
- OBS可以看做是一种极端的量化方法,即参数只有0和1两种状态
- OBQ引入缩放因子,在OBS的基础上减少因极端量化造成的效果损失
GPTQ
- OBQ速度太慢,量化ResNet 50大约需要1个小时,量化大模型可能需要数天
- GPTQ可以看做是OBQ的加速版
- OBQ独立量化权重矩阵W的每一行,每一行内部量化的时候按照delta E最小的原则来选择量化的顺序。GPTQ认为对于参数量很大的层,严格选择顺序的量化结果和任意顺序的量化结果差别不大。因此对所有的行都采用同样的顺序进行量化,从而加速梁海过程。
- 采用int/fp16(W4A16)的混合量化方案,其中模型权重被量化为int4的数值类型,激活层则保留在float16,是一种仅量化权重的方法
AWQ
AWQ认为权重并不同等重要,仅有小部分显著权重对于结果的影响较大。判断权重重要性的方法包括:
- 随机挑选
- 基于权重绝对值大小排序后,绝对值越大越显著
- 激活值越大越显著(Q=Wq*X,K=Wk*X,X即为激活值)
AWQ的实验结果发现:随机挑选与对所有权重进行低比特量化差不多;基于权重值大小的挑选效果与随机挑选差不多;基于激活值大小的挑选与fp16相比几乎没有精度损失。
然而,仅量化部分权重会带来硬件工程问题,存储和取数的计算比较复杂。为了硬件友好,对所有权重进行量化,但是对显著权重和非显著权重进行差异化的缩放(scaling),从而降低量化误差。对于显著权重,乘以较大的s;对于非显著权重,乘以较小的s。
QLoRA
QLoRA是使用量化思想对于LoRA进行优化的量化算法,可以显著降低训练所需要的显存资源。主要优点包括:
- 定义4位标准浮点数量化(Normal Float 4-bit,NF4),结合分位数量化和分块量化(解决参数极大极小异常值;提高并行化)
- 双重量化,包含对普通参数的一次量化和对量化常数的再次量化,进一步减小缓存
- 分页优化器(Page Optimizer),显存过高时用一部分内存代替显存
PEFT微调
为什么要进行PEFT微调
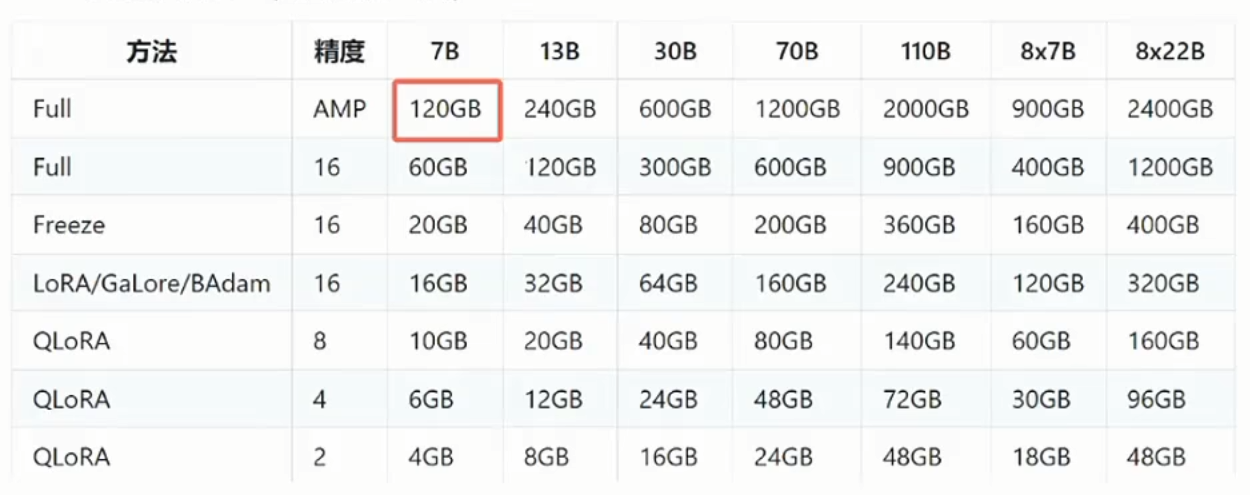
全参数微调的代价过大,包括在计算资源和微调时间上。
显存占用的计算包括:模型权重(fp16/混合精度,2x)、优化器状态(fp32,12x)、梯度(2x),激活状态,在训练时至少需要16x的显存
PEFT的几种方式
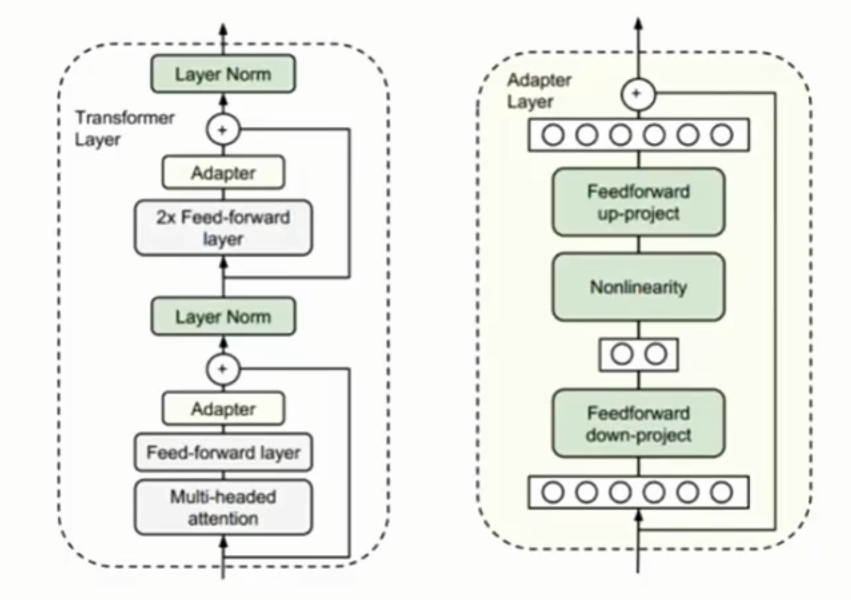
adapter
Adapter针对每个Transformer层,增加两个Adapter结构(分别是注意力和前馈层之后,但在norm前)。训练师,固定原来预训练模型采纳数不变,指对新增的Adapter结构和Layer Norm层进行微调。
该方式增加了模型的推理层数,可能造成推理延迟。
prefix tuning
- 在输入token之前构造一段virtual tokens作为Prefix,训练时只更新prefix部分的参数,其他参数不变
- 在每一层前端都加入virtual tokens
- 为了防止直接更新prefix参数导致训练不稳定和性能下降,在prefix层前面添加MLP结构,训练完成后,只保留prefix参数。
- 该方式会造成额外的token占用,降低有效序列长度
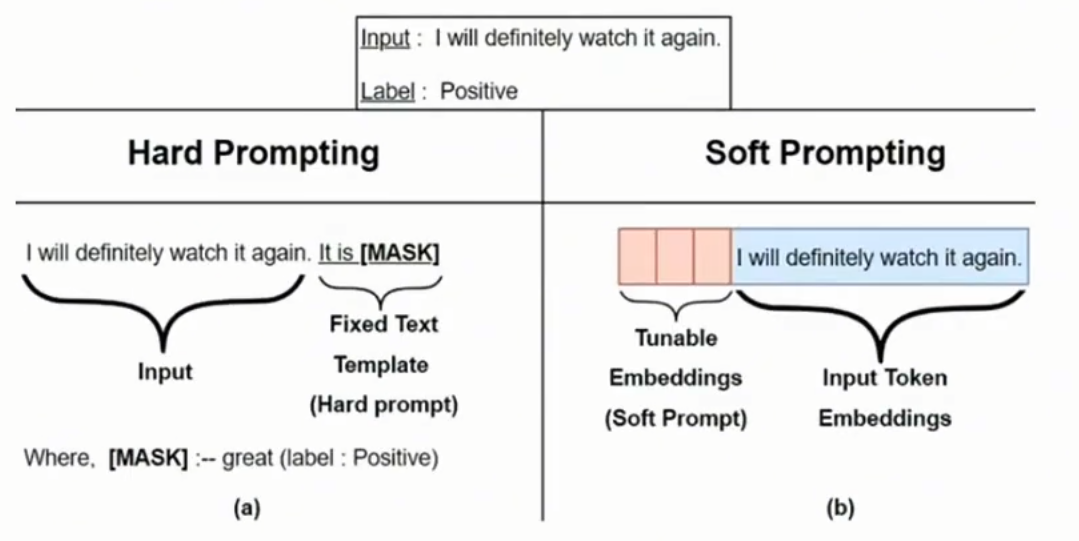
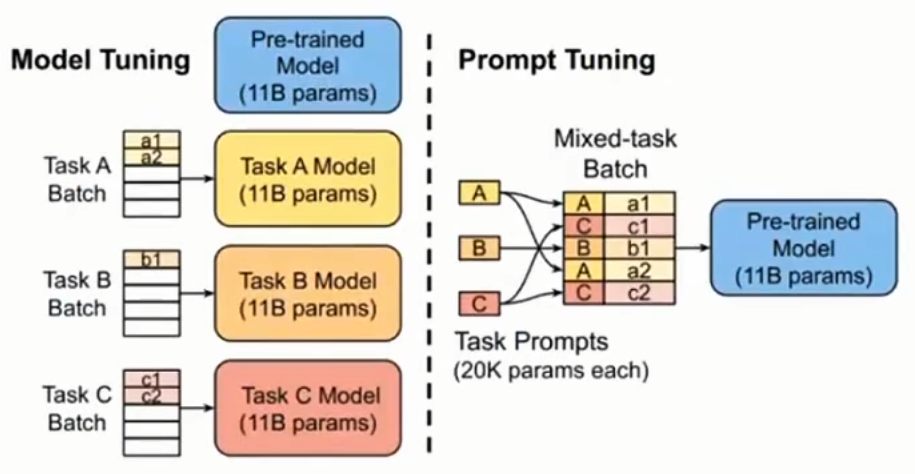
prompt tuning
给每个任务定义各自的Prompt,拼接到数据上作为输入,但只在输入层加入prompt tokens,且不加入MLP(显示的加入token)
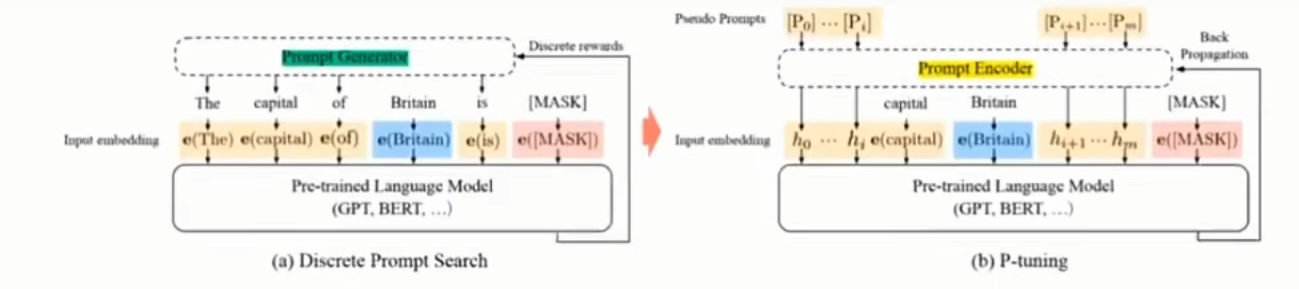
p-tuning
prompt tuning中,prompt的构造方法对结果的影响较大。在p-tuning中,将prompt转化为可学习的embedding层,并用MLP+LSTM的方式来对Prompt Embedding进行表征(只在输入层)。
与prefix tuning相比,p-tuning只在输入层添加,且不需要一定加载输入的前面,可以在任意位置添加。
p-tuning在小模型上表现较差;在NLU效果较好,训练标注任务效果较差
lora
- lora微调通过低秩分解模拟参数的改变量,从而以极小的参数量来实现大模型的间接训练
- 在原始的模型旁边增加一个通路,通过两个矩阵A、B相乘,先降维再升维,中间层维度维r,模拟本征秩
- 将两部分参数相加
- 矩阵的秩一般取1、2、4、8
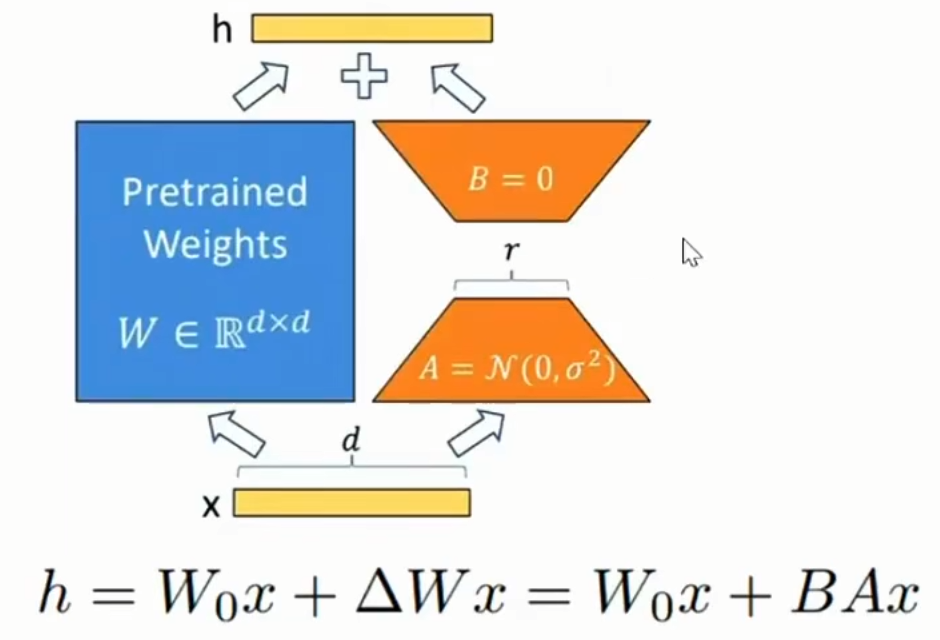
lora微调的变种包括:
- lora+:给A和B矩阵设置不同的学习率
- lora-drop:Lora矩阵可以添加到神经网络的任何一层。LoRA-drop可以选择哪些层由LoRA进行微调,哪些层不需要
- adalora:Lora-drop中各层的适配器要么完全被训练,要么完全不被训练。而AdaLoRA可以决定不同的适配器具有不同的秩
PEFT训练常用框架
- LLaMA-Factory
- SWIFT(魔搭社区)
微调主要参数设置
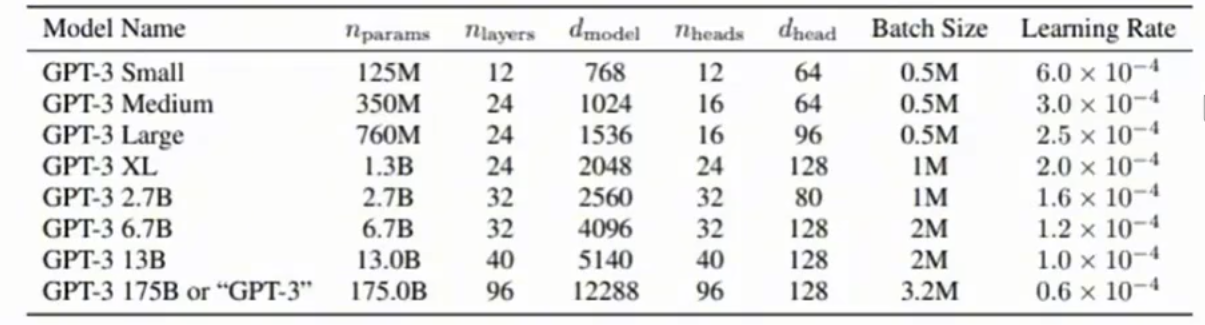
learning rate
根据gpt3 paper,一般来看,模型越大,学习率越低(无严格定义,实验导向确定)
lr_scheduler_type
- 常数学习率(constant):学习率在整个训练过程中保持不变
- 带预热的常数学习率(constant_with_warmup):在训练初期有一个预热阶段,学习率主键增加到初始学习率,然后保持常数
- 线性衰减(linear):从初始学习率线性下降到0
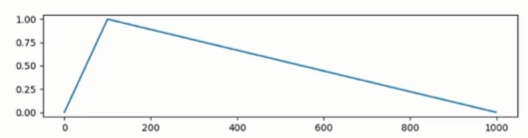
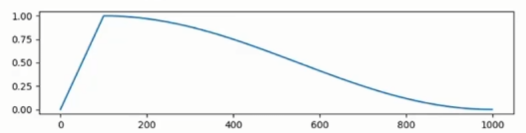
- 余弦退火(cosine):学习率按照余弦函数变化,在训练过程中逐步减小
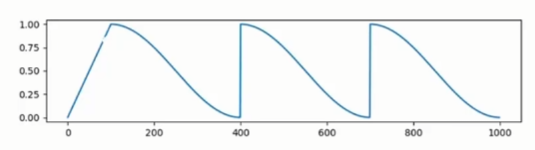
- 余弦退火与重启(cosine_with_restarts):带重启的余弦退火调度器,在训练过程中周期性的重置学习率,然后按余弦函数衰减,每个一段时间重启余弦曲线。
warmup_ratio
由于模型权重是随机初始化的,刚开始训练的时候如果学习率过大,可能造成训练不稳定。选择warmup预热学习率的方式,可以使得开始训练的几个epoch或者一些step内学习率较小。
gradient_accumlation_steps
梯度累加:每次获取1个batch的数据,计算1次梯度,梯度不清空,累积到预设值后,再更新网络参数,然后清空梯度,进行下一次循环。
为什么需要位置编码
Transformer基于自注意力机制,无法直接理解元素顺序。
使用绝对编码方法,每个位置固定编码,只于位置k有关,遇到变长序列或者长距离依赖时,无法充分表达位置信息。
使用相对编码方法,并不为每个位置分配唯一编码,而是关注序列中各元素之间的相对位置。计算序列中元素之间的距离来表示他们之间的相对关系。

好的位置编码:每一个位置编码唯一;良好的外推性;不同的句子中,token的相对位置相同时,相关性一致
旋转位置编码的具体操作流程:对序列中的每个token,先计算其对应query和key向量,然后对每个token位置计算对应的旋转位置编码,然后对每个token的query和key向量的元素应用旋转变换。最后将旋转后的query和key向量相乘,纳入对应的相对位置信息。

Transformer
传统循环神经网络(RNN/LSTM)存在量大局限:
- 串行计算:依赖时序递推,无法并行处理长序列,效率低下
- 长距离依赖衰减:梯度随序列长度指数级消失,难以捕捉远距离语义关联。Transformer通过自注意力机制和全并行架构彻底解决了这些问题,成为NLP、CV领域的通用框架。
Agent的核心定义
AI Agent是一个能够通过感知环境、自主决策、调用工具完成复杂任务的智能体,其核心功能包括:
- 任务拆解:将用户目标分解为子任务
- 工具调用:API、搜索、代码执行等
- 记忆与状态管理:包括上下文记忆、长期记忆存储等
- 自我迭代:能够反思错误、给出优化策略
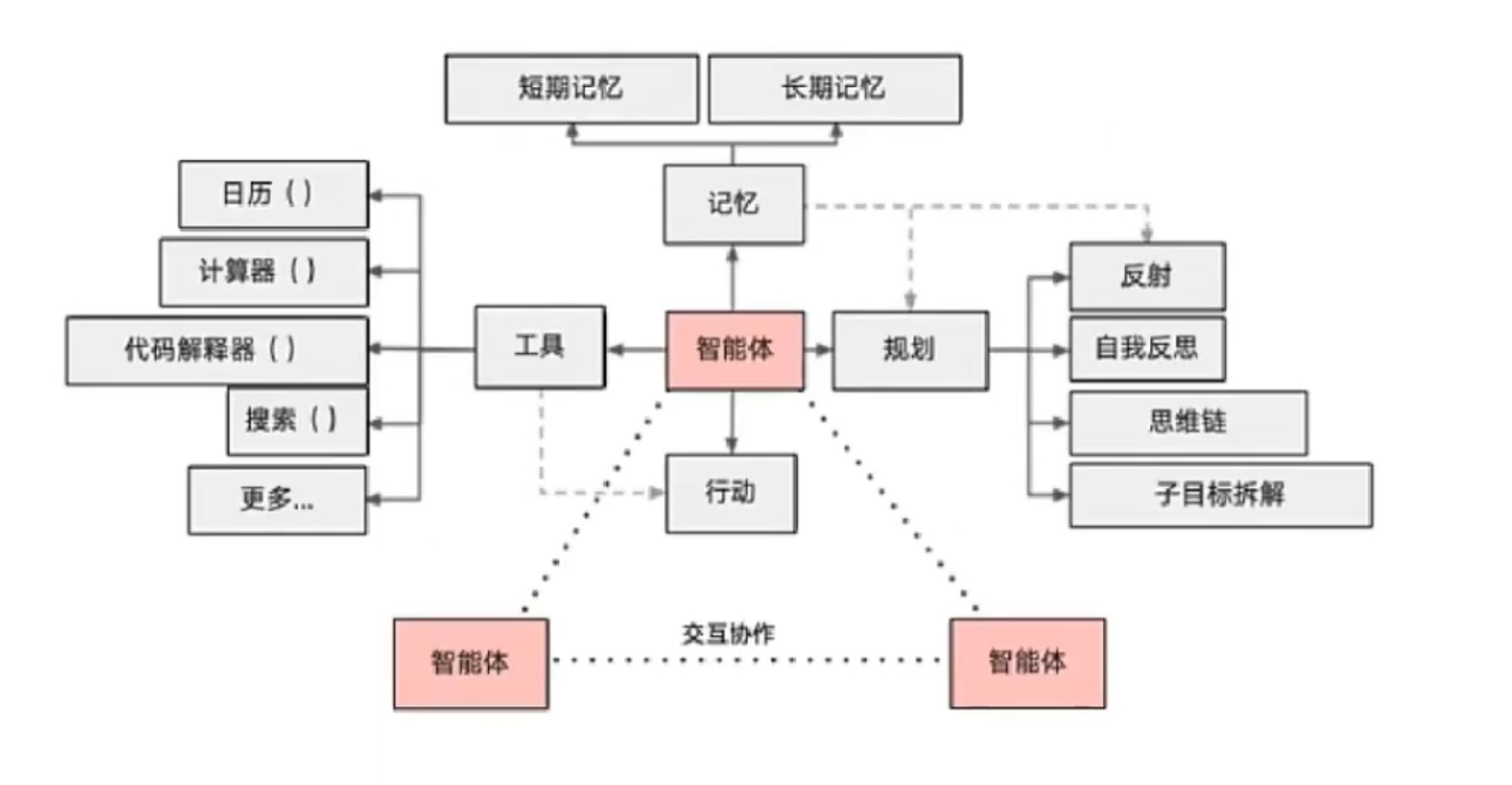
(1)任务定义与规划
- 目标解析:通过自然语言理解用户意图(如“帮我分析新能源汽车市场趋势”->拆解为数据爬取、清洗、分析、可视化等步骤)
- 规划方法:链式规划(Chain-of-Thought)、树状(Tree-of-Thought)、图状(Graph-of-Thought)任务分解
- 工具选择:根据子任务类型选择工具,如爬虫工具、pandas、matplotlib等
(2)模型层
- 核心模型:选择基础大模型,如GPT4、LLAMA2等作为推理引擎
- 角色设定:通过System Prompt定义Agent角色
- 微调需求:是否需要领域微调,如医疗、金融等场景
(3)工具库集成
- 内置工具:代码解释器、数学计算、文件读写
- 外部API:搜索引擎SerpAPI、数据库SQLAlchemy、云服务AWS S3等
- 自定义工具:业务特定工具,如内部CRM系统接口等
(4)记忆系统
- 短期记忆:上下文窗口管理,如GPT4的8k/32k Token限制
- 长期记忆:向量数据库存储历史交互
- 优先级策略:关键信息的提取和缓存,如用户偏好、任务历史等
(5)安全和可控性
- 权限控制:限制敏感工具调用,如删除文件、支付接口等
- 输出审核:敏感词过滤等
常见的Agent开发框架包括:LangChain、AutoGPT、Microsoft Guidance等
PPO和DPO的区别
PPO:通过限制策略更新幅度(KL散度约束)最大化奖励期望,需要预训练奖励模型(Reward Model),通过策略-奖励交互迭代优化
DPO:直接利用人类偏好数据,将策略对到偏好分布,绕过显式奖励建模,直接通过偏好对(好答案、坏答案)来优化策略
在训练范式上:
| 维度 | PPO | DPO |
|---|---|---|
| 数据需求 | 需要大量无标注数据+奖励模型训练数据 | 仅需偏好对(<好答案,坏答案>) |
| 计算复杂度 | 高(需要多次策略-奖励模型交互) | 低(单阶段端到端训练) |
| 稳定性 | 需谨慎调参(KL惩罚系数等) | 更鲁棒(隐式约束策略偏离) |
| 适用场景 | 复杂奖励信号,如游戏AI | 明确偏好反馈(如对话质量排序) |
vllm的推理加速是怎么实现的
vllm是一个针对大语言模型推理优化的库,主要通过PageAttention、连续批处理(continous batching)和高效的内存管理来提升推理速度。
PageAttention:传统注意力计算需要预留最大序列长度内存,导致显存浪费,如用户输入短文本时,80%的显存被闲置。PageAttention通过将key-value缓存分割成块,类似内存分页,按需动态分配内存。
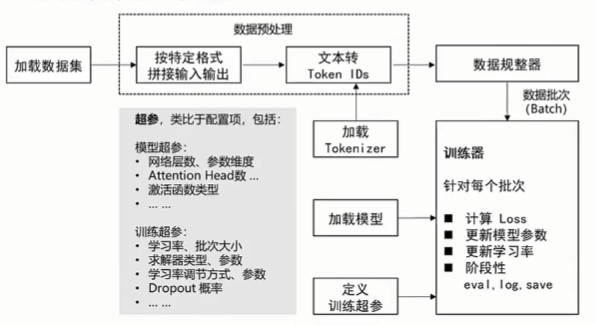
大模型微调的流程是什么样的
Parametric Sink Attention
研究发现:很多Transformer会把大量注意力权重打到序列最前面几个token(尤其BOS),即使他们在语义上并不重要。模型需要一些固定的汇聚点来稳定attention分布。
| 类型 | 做法 | 局限 |
|---|---|---|
| Token Sink | 用输入里前N个真实token(靠mask保证始终可见) | 内容绑定在prompt开头,语义受到限制 |
| Parametric Sink | 用可学习参数当K/V,与输入无关 | 模型自己学该存什么全局信息 |
并行策略比较
| 缩写 | 全称 | 中文 | 原理 | 解决的问题 |
|---|---|---|---|---|
| DP | Data Parallel | 数据并行 | 每张GPU保存完整模型,只处理不同batch的数据 | 每张卡处理不同的数据 |
| DDP | Distributed Data Parallel | 分布式数据并行 | 每张GPU独立前后向,反向结束后通过AllReduce同步梯度 | DP的高效分布式实现 |
| FSDP | Fully Sharded Data Parallel | 全分片数据并行 | 参数、梯度、优化器状态都切分存储,计算时再临时聚合 | 节省显存 |
| FSDP2 | Fully Sharded Data Parallel 2 | 第二代全分片数据并行 | 基于DTensor的新版FSDP,实现更高效、更灵活的模型状态分片 | 具有更好的拓展性和性能 |
Comments NOTHING