
基本概念
宽度优先搜索算法(Breadth First Search),是图搜索中最基础、最重要的算法之一。Dijkstra单元最短路径算法和Prim最小生成树算法都采用了和宽度搜索类似的思想。宽度优先搜索属于一种盲目搜索算法,目的是系统地展开并检查图中的所有节点,以寻找结果,即,这种算法不考虑结果的可能位置,彻底地搜索整张图,直到找到结果为止。
假设我们一开始位于某个顶点(即起点),由于此时不知道图的整体结构,只能从起点开始顺着边搜索,直到到达指定顶点(终点)。再次过程中,每经过一个顶点,都需要判断它是否为终点。值得注意的是,宽度优先搜索会优先从离起点近的顶点开始搜索。
图解算法
本节以绘图的方式展示宽度优先搜索的工作原理,相关图片来自CSDN:
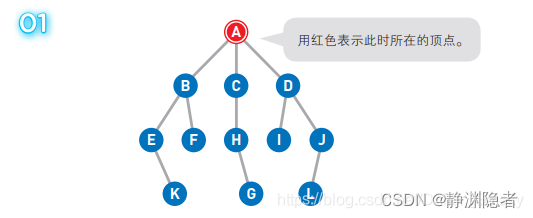
假设A为起点,G为终点。最初我们位于A点,此时不知道G点在哪。

由于B、C、D点与A点直接相连,故将其设为下一步的后补顶点。

从候补顶点中选出一个顶点前进。优先选择最早成为后补的那个顶点(在Dijkstra算法中,选择距离最短的顶点),如果多个顶点同时称为后补,那么可以随机选择其中一个(优先选择最早称为候补的顶点,符合队列“先进先出”的思想)
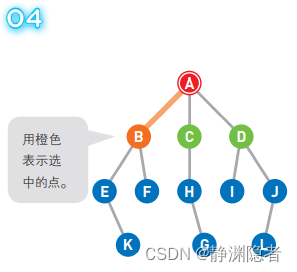
依据这一选择思想,选择最左边的顶点B,从A点移动到B上。
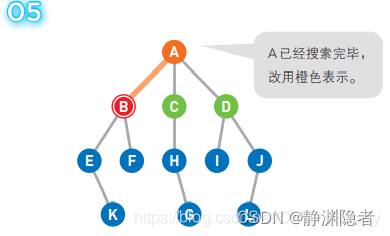
将B点变为红色,已经搜索过的顶点变为橙色。
此时,候补顶点用“先入先出”(FIFO)的方式来管理,因此使用“队列”这个数据结构进行管理。
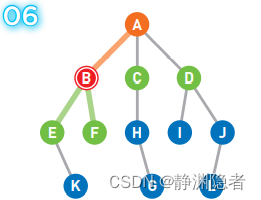
将从B点直达的两个顶点E和F设为候补顶点:
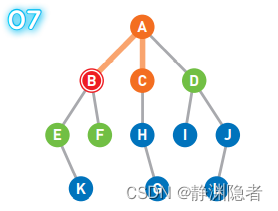
此时,最早成为候补顶点的是C和D,选择最先成为候补顶点的C点
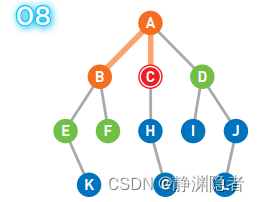
移动到C点继续进行计算
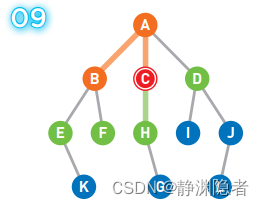
将可以从C点直达的顶点H设为候补顶点。
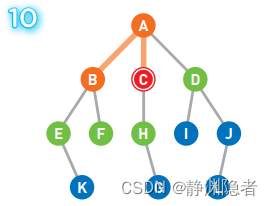
重复上述操作直到到达终点G,或者所有顶点都被遍历为止。
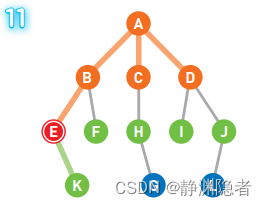
这个示例中的搜索顺序中为A、B、C、D、E、F、H、I、J、K、G
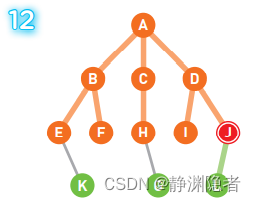
完成从A到I的搜索,现在在顶点J处
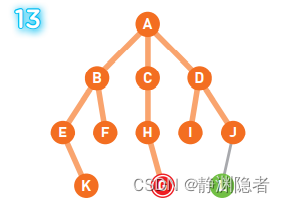
到达终点G,结束搜索。
由该计算流程可以看出,宽度优先搜索的特征为从起点开始,由近及远进行广泛的搜索。因此,目标顶点距离起点越近,搜索结束的就越快。
代码模板
from collections import deque
def bfs(graph,start,target):
"""
广度优先搜索算法
:param graph: 图的邻接表表示
:param start: 起始节点
:param target: 目标节点
:return: 是否找到目标节点
"""
queue=deque() #创建队列
queue.append(start) # 将起始节点入队
visited=set() # 创建集合用于存储已访问的节点
while queue:
node=popleft() # 从队列中取出一个节点
if node==target:
return True # 找到目标节点
visited.add(node) # 标记节点为已访问
for neighbor in graph[node]:
if neighbor not in visited:
queue.append(neighbor) # 将未访问的相邻节点入队
return False # 未找到目标节点
Comments NOTHING