基础知识
transformer 八股文
Self-Attention的表达式
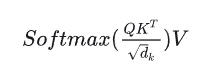
为什么在上面的公式中要对QK进行scaling
sacling后进行softmax操作可以使得输入数据的分布变得很好,防止梯度消失,让模型能够更容易训练。
Self-Attention一定要这样表达吗?
不一定,只要能够表示建模的相关性就可以。
最好能够高速计算(矩阵乘法),并且表达能力强(query可以主动关注到其他的key并在value上进行强化,并且忽略不相关的其他部分),模型容量够(引入了project_q/k/v,att_out,多头)
有其他方法不用除根号d_k吗?
有,只要能缓解梯度消失的问题就可以
d_k是词向量/隐藏层的维度,除以d_k的原因主要由两点:
- 首先要除以一个数,防止输入softmax的值过大,导致偏导数趋近于0
- 选择d_k是因为可以使q*k的结果满足期望为0,方差为1的分布,类似于归一化
为什么transformer用Layer Norm?有什么用?
任何norm的意义都是为了让使用norm的网络的输入的数据分布变得更好,也就是转化为标准正态分布,数值进入敏感度区间,以减缓梯度消失,从而更加容易训练。当然,这也意味着舍弃了除此维度之外的其他维度的信息。
为什么不用BN(batch normalization)
BN广泛应用于CV,针对同一个特征,以夸样本的方式展开归一化,也就是对不同样本的同一channel间的全部像素值进行归一化,不会破坏不同样本同一特征之间的关系。在NLP中:
- 对不同样本的同一特征信息进行归一化没有意义,如(为中华之崛起而读书;我爱中国;母爱最伟大)中,“为”、“我”、“母”归一到同一分布没有意义。
- 舍弃不了BN中舍弃的其他维度的信息,也就是同一样本的不同维度的信息。如“为”、“我”、“母”归一到同一分布后,第一句话中的“为”和“中”就没有可比性了。
Bert为什么要搞一个position embedding?
因为只有之前提到的self-attention无法表达位置信息(对位置信息不敏感),如果不添加position embedding,“1+1=2”和“1+2=1”是一样的,因此需要增强模型针对位置的表达能力。
Bert为什么三个embedding可以相加?
Bert的三个embedding是指token embedding,segment embedding,position embedding。加法不会导致信息损失,因为本质上神经网络中每个神经元收到的信号也是“权重”相加得到的。
transformers为什么要用三个不一样的QKV?
为了增强网络的容量和表达能力。如果直接用输入x本身来做,表征能力过弱。
为什么要多头?举例说明多头相比于单头注意力的优势
进一步增强网络的容量和表达能力,可以类比CV中不同的channel(卷积核)会关注不同的信息,事实上不同的头也会关注不同的信息。
假设我们有一个句子"the cat, which is black, sat on the mat"。在处理"sat"这个词时,一个头(主语头)可能会更关注"cat",因为"cat"是"sat"的主语;另一个头(宾语头)可能会更关注"on the mat",因为这是"sat"的宾语;还有一个头(修饰头)可能会关注"which is black",因为这是对"cat"的修饰。
当然,这只是为了方便你理解,事实上就和卷积核一样,不同头关注的内容是很抽象的。
你当然可以就用一个头同时做这个事,但是还是这个道理,我们的目的就是通过增加参数量来增强网络的容量从而提升网络表达能力。
经过多头之后,我们还需要att_out线性层来做线性变换,以自动决定(通过训练)对每个头的输出赋予多大的权重,从而在最终的输出中强调一些头的信息,而忽视其他头的信息。这是一种自适应的、数据驱动的方式来组合不同头的信息。

Comments NOTHING