
Meta Data
- 发表时间 2025.09.29
- 作者:Pengfei Wang, Baolin Sun1, Xuemei Dong etc.
- 论文链接:arxiv.org/pdf/2509.24403.pdf
- 项目链接:https://github.com/antgroup/Agentar-Scale-SQL
Abstract
在 BIRD 等具有挑战性的基准测试中,最先进 (SOTA) 的文本到 SQL 方法仍然远远落后于人类专家。 当前探索测试时间扩展的方法缺乏精心策划的策略,并且忽略了模型的内部推理过程。 为了弥补这一差距,我们引入了 Agentar-Scale-SQL,这是一种利用可扩展计算来提高性能的新颖框架。 Agentar-Scale-SQL 实现了精心策划的测试时间扩展策略,该策略协同结合了三个不同的视角:i) 通过 RL 增强的内在推理进行内部扩展,ii) 通过迭代细化进行顺序扩展,以及 iii) 使用多样化综合和锦标赛选择进行并行扩展。 Agentar-Scale-SQL 是一个通用框架,旨在轻松适应新数据库和更强大的语言模型。 大量实验表明,Agentar-Scale-SQL在BIRD基准上实现了SOTA性能,在测试集上达到了81.67%的执行准确率,在官方排行榜上排名第一,展示了一条通往人类水平性能的有效途径。
Introduction
通过使用户能够用自己的自然语言查询结构化数据库来实现数据分析的民主化是人机交互的长期目标。这是Text-to-SQL的核心目标,是关键研究领域,专注于将自然语言问题转化为可执行的SQL查询。通过弥合人类语言和结构化数据之间的差距,文本到SQL使非技术用户能够有效地与复杂数据库交互,引起了自然语言处理(NLP)和数据库社区的极大兴趣。
文本到SQL的最终愿景是开发能够匹配并最终超越人类专家性能的系统。然而,这一雄心与当前的最新技术之间仍然存在巨大差距。在具有挑战性的BIRD基准上,人类专家的执行准确率(EX)达到92.96%,而即使是表现最好的方法也有相当大的滞后,前5种方法在测试集上的准确率约为75%。弥合巨大的人机性能鸿沟迫切需要创新。
最近的Text-to-SQL研究分为三个主要类别。第一种是基于提示的方法(例如OpenSearch-SQL和DAIL-SQL)。第二类是基于微调的方法,代表作品有Arctic-Text2SQL-R1-32B。第三类包括XiYan-SQL、CHASE-SQL+Gemini和Contextual-SQL等混合方法。这些方法主要从不同的角度探索测试时间扩展:Contextual-SQL采用集成策略,而XiYan-SQL和CHASE-SQL研究集成策略和顺序细化。然而,这些研究都有一个共同的局限性,因为它们忽视了模型推理过程的内部视角和精心策划的缩放组合。
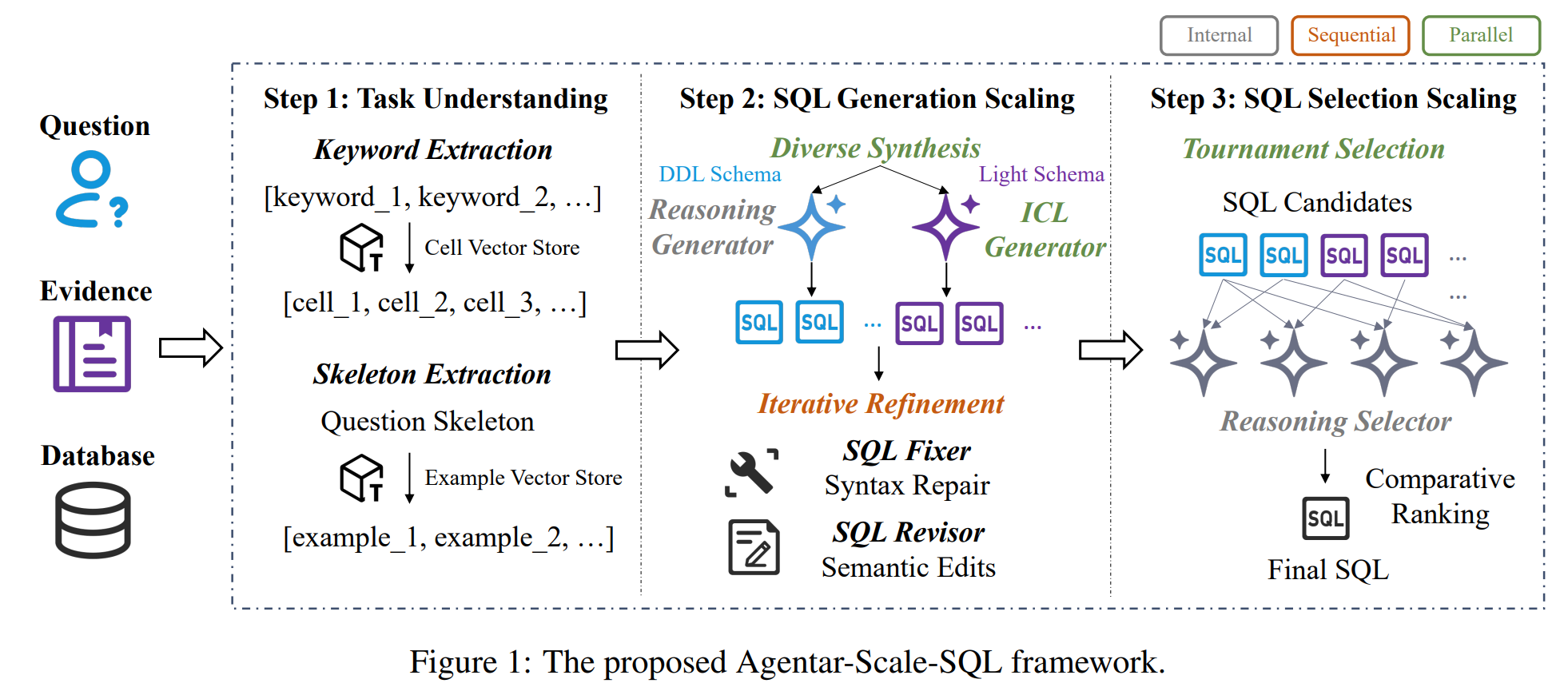
为了进一步提高Text-to-SQL的性能,这项工作认为最有希望的前进道路在于完全接受"痛苦的教训"的原则:利用可扩展计算的通用方法最终战胜了基于复杂的、人类指定的知识的方法。秉承这一理念,我们专注于测试时扩展,并且没有为模式链接设计复杂的策略,因为我们相信仅扩展就足以提高性能。为此,我们引入了Agentar-Scale-SQL,这是一个精心安排的测试时间扩展框架,它证明了实现人类水平性能的途径不在于制定更智能的启发式方法,而在于构建有效利用测试时间扩展的通用框架。Agentar-Scale-SQL采用跨三个不同视角的精心策划的扩展策略:i)内部扩展Internal Scaling(通过RL增强的内在推理),ii)顺序扩展Sequential Scaling(通过迭代细化),以及iii)并行扩展Parallel Scaling(通过多样化综合和锦标赛选择)。该策略在三阶段框架内实现,如图1所示。步骤1(任务理解)的目标是建立对输入及其上下文的全面理解,这对于后续步骤中的扩展操作至关重要。然后,第2步(SQL Generation Scaling)进行多样化的综合和迭代细化,以获得高质量和多样化的SQL候选。具体来说,多样化综合采用两个不同的生成器(即内在推理生成器和ICL生成器)以及特定于生成器的模式格式。最后,第3步(SQL选择缩放)采用锦标赛选择并微调内在推理选择器以确保高精度。我们的贡献总结如下:
- 精心安排的测试时间扩展。我们引入了一个精心设计的测试时间扩展框架,该框架通过跨三个不同的视角进行扩展,将额外的推理计算转换为准确性增益:i)内部扩展(RL增强的内在推理),ii)顺序扩展(迭代细化),以及iii)并行扩展(多样化综合和锦标赛选择)。
- 通用性和可扩展性。整个框架完全通用、即插即用,并且可以轻松适应任何数据库。随着未来的LLM变得更加强大并且计算继续变得更便宜,Agentar-Scale-SQL的性能上限将自行提升;我们可以简单地将更多的计算分配给生成和选择阶段,以实现更高的准确性。
- 透明且可行的见解。我们提出了一个结构化的三阶段文本到SQL框架,描述了每个阶段的具体角色和目标。至关重要的是,我们的工作是第一个扩展SQL生成和选择阶段的工作。这些贡献共同建立了透明且可操作的见解,以指导文本到SQL领域的未来研究和开发。
- 广泛的实验。大量实验证实了Agentar-Scale-SQL的SOTA性能。具体来说,Agentar-Scale-SQL在BIRD开发集上的EX为74.90%,在测试集上的EX为81.67%,R-VES为77.00%。有了这些结果,Agentar-Scale-SQL在BIRD排行榜上排名第一。我们的研究结果表明,扩展是在文本到SQL中实现SOTA性能的关键因素。
相关工作
Text-to-SQL:虽然LLM在文本到SQL方面取得了显着进步,但其直接应用对于复杂查询仍然具有挑战性。最近的方法通过基于提示的方法,微调,或采用测试时间缩放的混合策略。与我们的工作最相关的是这些缩放方法,它们使用并行合成和顺序细化等技术来提高生成质量。然而,这些方法有一个共同的局限性,即它们缺乏不同缩放维度的精心组合。
Test-time Scaling:测试时间扩展(TTS)通过策略性地扩展计算而不是改变模型权重来增强LLM在推理过程中的性能。TTS的现有研究大致可分为三个范式。并行扩展(Parallel scaling)侧重于同时生成多个候选解决方案并将它们聚合以提高找到正确答案的可能性,自洽(self-consistency)就是一个突出的例子。相比之下,顺序扩展(sequential scaling)通过一系列步骤迭代构建或细化解决方案,从而模拟深思熟虑的"系统2"推理过程,例如思想链(CoT)和迭代细化iterative refinement。最近,出现了内部扩展,其中模型经过训练可以自主分配自己的计算预算并确定推理深度,而无需外部编排。我们的工作Agentar-Scale-SQL建立在这些基本概念的基础上,引入了一种新颖的编排框架,该框架协同地结合了这三种范式,专门为推进文本到SQL领域的SOTA而定制。
方法论
概述
给定问题Q_u、证据E_u和目标数据库D,我们的框架分为三个阶段,如图1所示。离线预处理阶段先于在线框架的运行。
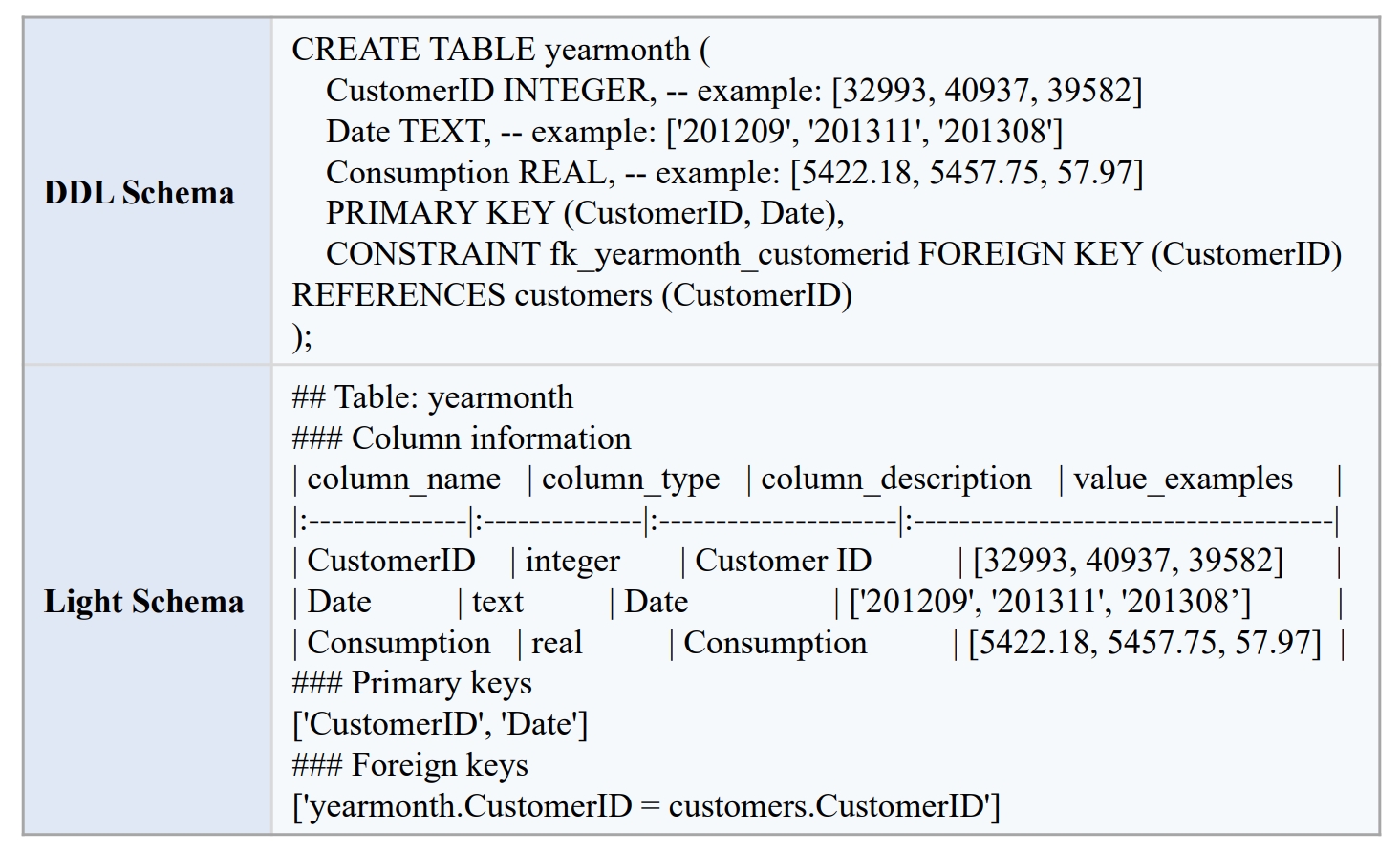
离线预处理(Offline Preprocessing):我们的方法在在线推理之前涉及三个离线预处理步骤。首先,为了增加生成的多样性,我们用两种格式表示数据库元数据(见图2)。我们创建了一个基于Markdown的轻模式,旨在通过通用LLM进行有效的上下文学习(ICL),并使用标准DDL模式来微调代码专用模型,该模型利用其训练背景来实现更快的收敛。其次,我们将数据库中的所有文本单元格值索引到向量存储V_{D_{cell}}中。最后,我们还将训练集作为示例索引到向量存储V_{D_{example}}中,这允许我们通过嵌入骨架提取的用户问题并执行相似性搜索来在推理过程中检索相关的小样本示例。
在线框架(Online Framework):Agentar-Scale-SQL是一个精心策划的测试时间扩展框架,通过在三个不同角度采用精心策划的扩展策略,将额外的推理计算转化为准确性增益:i)内部扩展(通过RL增强的内在推理),ii)顺序扩展(通过迭代细化),以及iii)并行扩展(通过多样化综合和锦标赛选择)。总体而言,Agentar-Scale-SQL包含三个阶段:步骤1(任务理解)、步骤2(SQL生成扩展)和步骤3(SQL选择扩展)。
- 第1步(任务理解):侧重于全面理解用户的意图并检索相关上下文。
- 第2步(SQL生成扩展):开发多样化的综合和迭代细化,以获得高质量和多样化的SQL候选。特别是,多样化的综合组件利用了两个在特定模式格式上运行的不同生成器:具有DDL模式的推理生成器和具有轻模式的ICL生成器。
- 第3步(SQL选择缩放):利用锦标赛选择方法,通过内在推理选择器增强,以实现高选择准确性。
以下各节将深入研究每个组件的详细信息。
任务理解
数据库单元(Database cells)至关重要,因为它们提供了WHERE和HAVING等SQL子句所需的特定值。同样,精心挑选的小样本示例可以显着提高上下文学习(ICL)的性能。因此,任务理解步骤的主要目标是识别和检索上下文的这两种关键形式:相关的数据库单元和有效的演示示例。这是通过两个并行子过程实现的:i)关键字提取,从问题Q_u和证据E_u中提取关键字,以使用来自V_{D_{cell}}的基于嵌入的相似性检索相关单元格,ii)从Q_u中提取骨架,以使用来自V_{D_{example}}的基于嵌入的相似性检索相关示例。
SQL生成扩展
此阶段采用两个互补的生成器,在双模式视图上运行,以生成高质量和多样化的候选者。第一个生成器M_{reasoning}是通过强化学习(RL)训练的内在推理器。第二个M_{ICL}是由大型专有LLM驱动的情境学习(ICL)模型。然后,进行语法修复和语义编辑的迭代细化循环。结果,生成了一组n SQL候选,表示为C={c_1,c_2,\ldots,c_n}。以下部分详细介绍了每个组件。
内在推理SQL生成器
受Arctic-Text2SQL-R1的启发,我们通过一个简单的、基于执行的RL框架追求强大的内在推理文本到SQL生成。
强化学习管道概述(Overview of RL Pipeline):我们采用GRPO,因为它在结构化推理任务上的效率和有效性得到了验证。与Arctic-Text2SQL-R1不同,我们专门使用BIRD数据集的训练数据,没有任何额外的数据。正式地,让\pi_\theta表示由\theta参数化的策略模型。对于任何给定的输入问题Q_u及其关联的证据和模式,模型会生成一组N候选SQL查询(即,推出){o_{Q,1},\ldots,o_{Q,N}}。然后评估每个候选者以产生明确的奖励信号,如下所述。这种按输入批量推出可以计算相对优势,从而稳定学习并促进稳健的策略更新。
每个样本i的裁剪代理目标定义为:
L(\theta) = \frac{1}{N}\sum_{i=1}^{N}\min\left(r_i A_i, \text{clip}(r_i, 1-\epsilon, 1+\epsilon)A_i\right)
GRPO的完整目标:
\mathcal{J}{\text{GRPO}}(\theta) = \mathbb{E}[L(\theta)] - \beta D{\text{KL}}(\pi_\theta \parallel \pi_{\text{ref}})
其中,r_i是似然比\frac{\pi_\theta(o_i|Q)}{\pi_\theta^{\text{old}}(o_i|Q)},A_i是优势,D_{\text{KL}}是KL散度惩罚,使策略保持接近参考(监督微调)模型。参数\epsilon和\beta在实践中进行调整,以平衡探索和稳定性。
奖励设计:我们按照Arctic-Text2SQL-R1仅根据最终执行正确性和基本语法有效性定义奖励函数R_G:
R_G = \begin{cases} 1, & \text{if results match the ground truth;} \ 0.1, & \text{if the SQL is executable;} \ 0, & \text{otherwise.} \end{cases}
多样化合成
多样化的综合策略旨在生成高质量且多样化的SQL候选池。该策略涉及两个并行且互补的生成器:一个微调推理生成器和一个ICL生成器。我们创建了一个基于Markdown的轻模式,专为通用LLM的有效ICL而设计,并使用标准定义语言(DDL)模式来微调代码专用模型,该模型利用其训练背景来实现更快的收敛。
推理生成器。该生成器利用DDL模式进行深入、逐步的推理。一方面,在我们的内部扩展原则的指导下,它被设计为构建复杂的查询,其主要目标是实现高精度。另一方面,可以对其进行微调,以符合目标基准的具体特征和要求。
ICL发生器。同时,ICL生成器利用基于Markdown的轻模式(参见图2)和在任务理解阶段检索的少数样本示例。为了增强ICL生成器的多样性,我们采用了多方面的策略:改变输入提示、随机化上下文示例的顺序、利用一系列LLM以及调整温度设置。通常,不同的提示分为三种不同的风格:直接提示(没有明确的推理)、思想链(CoT)提示和问题分解。该生成器擅长利用所提供的上下文示例中的模式识别来快速生成各种合理的查询。
通过将推理生成器的深度分析方法与ICL生成器的示例驱动方法相结合,我们最大限度地提高了候选池的多样性。这种协同作用显着增加了在选择阶段之前出现至少一个正确或接近正确的查询的概率。
迭代细化
为了进一步提高候选SQL的质量,我们引入了迭代细化模块来细化错误。SQL查询可能同时包含语法和语义错误。我们采用双管齐下的方法来修正错误。对于语法错误(前者),我们使用SQL修复程序,这是一个基于LLM的组件,可以有条件地激活以修复无效语法。对于语义错误(后者),我们使用SQLrevisor,这是一种LLM代理,旨在识别和完善查询中的逻辑缺陷。为了简化修订过程,我们首先按执行结果对查询进行分组。随后,我们从每组中随机选择一个查询进行细化。
SQL选择缩放
多数投票的主要限制在于其基本假设,即最常见的答案也是正确的答案,但这一前提并不总是成立。 相反,我们采用锦标赛选择过程,其中推理选择器通过强化学习(RL)增强,通过成对比较来评估候选者。 此过程中排名靠前的 SQL 查询被选择作为最终 SQL。 我们将在以下部分详细介绍这些模块。
比赛选择
我们通过两阶段过程选择最佳SQL查询。首先,我们根据数据库D上相同的执行结果对查询进行分组,从而合并初始查询池。从每个组中选出一个代表来形成候选集C'={c_1,\ldots,c_m}。其次,这些候选人参加两两循环赛。对于每对katex[/katex],推理选择器\mathcal{M}{selection}根据问题、轻模式和执行结果确定获胜者,并增加获胜者的分数W_i。最终查询是得分最高的查询:c{final}=\arg\max_{c_i \in C'} W_i。
内在推理SQL选择器
我们将强化学习(RL)应用于SQL选择器\mathcal{M}_{selection},这种方法类似于SQL生成器中使用的内在推理。
强化学习管道概述:遵循3.3.1节中描述的方法,我们应用GRPO来增强SQL选择的推理能力。基于训练集,我们构建了8.5k个样本进行强化学习。
奖励设计:SQL选择的目标是从一组候选查询中识别出正确的查询。为了实现这一目标,我们引入了一个面向结果的奖励函数R_S,旨在评估选择的正确性:
R_S = \begin{cases} 1, & \text{if the selection is correct;} \ 0, & \text{otherwise.} \end{cases}
实验
在本节中,我们在大规模数据集上对所提出的Agentar-Scale-SQL进行实验评估。我们的目标是回答以下研究问题:
- RQ1:与最先进的方法相比,Agentar-Scale-SQL的性能如何?
- RQ2:每个模块如何影响Agentar-Scale-SQL的整体性能?
- RQ3:ICL和Reasoning生成器各自的作用和互补作用是什么?
- RQ4:性能如何随着不同复杂程度的候选者数量而变化?
实验设置
数据集:我们在BIRD基准上评估我们的方法。它包含跨95个大型数据库的超过12,751个问题SQL对,通过跨超过37个专业领域的杂乱数据和复杂模式来模拟现实世界的复杂性。
基线:我们比较了总体排行榜和单模型排行榜中的几种顶级基线方法。前者由15个基线组成,包括AskData+GPT-4o、LongData-SQL、CHASE-SQL+Gemini、JoyDataAgent-SQL、XiYan-SQL等。后者包括Gemini-SQL、DatabricksRLVR32B、Sophon-Text2SQL-32B、Arctic-Text2SQL-R1-32B等八种领先方法。
指标:继之前的工作之后,我们使用执行准确度(EX)(各个排行榜的官方指标)作为比较方法的主要评估指标。此外,我们采用官方的基于奖励的有效效率分数(Reward-based Valid Efficiency Score,R-VES)来评估生成的SQL的效率。
实施细节:我们实施Agentar-Scale-SQL,通过LangChain/LangGraph和all-MiniLM-L6-v25 embeddings提供支持。任务理解通过Gemini-2.5-Flash提供支持。ICLSQL生成器利用具有两种温度设置(0.5和1.8)的Gemini-2.5-Pro(缩写为pro)和GPT-5(最少推理效率)。ReasoningSQLGenerator基于Omni-SQL-32B进行了微调。默认情况下,候选SQL包括来自ICLSQL生成器的9个和来自ReasoningSQL生成器的8个。SQLFixer和SQLReviser都使用Gemini-2.5-Pro。ReasoningSQLSelector的基础模型是Qwen2.5-Coder-32B-Instruct。强化学习框架在32个NVIDIA A100 80GB GPU上利用verl实现。
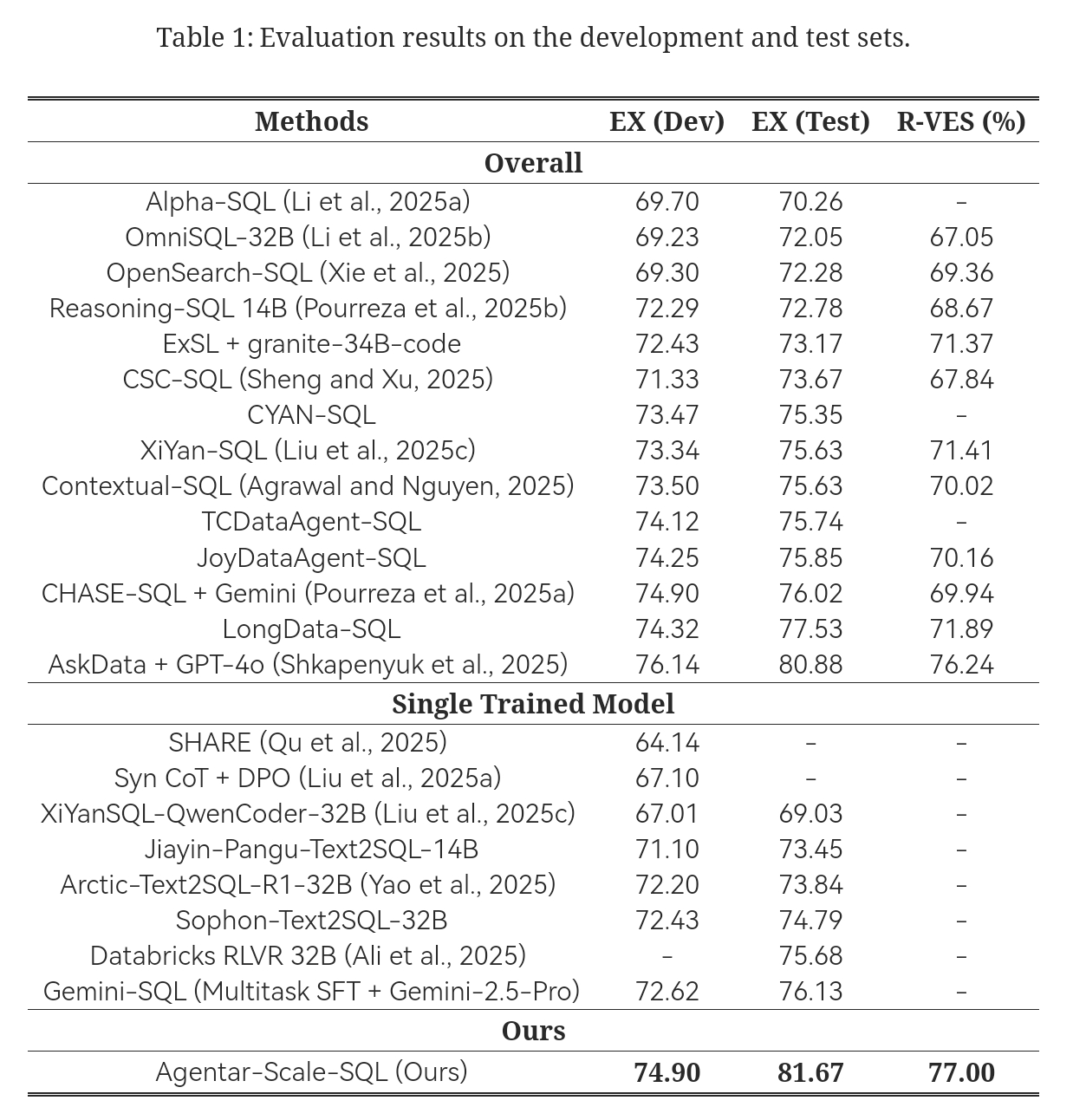
主要结果 (RQ1)
如表1所示,我们的Agentar-Scale-SQL框架在BIRD基准上建立了新的SOTA,在测试集上实现了81.67%的执行准确率(EX)和77.00%的R-VES。在测试EX中,该结果比之前的SOTA(AskData+GPT-4o)提高了0.79%。值得注意的是,这些方法采用了强大的模型,例如Gemini2.5Pro和Claude4。
值得注意的是,与单一训练模型相比,性能提升更为明显;Agentar-Scale-SQL在测试EX中比最强的单一模型(Gemini-SQL)性能高出5.54%。这些结果从经验上验证了我们精心策划的扩展策略的有效性。
消融研究 (RQ2)
接下来,我们通过比较Agentar-Scale-SQL与其不带关键模块的变体来研究Agentar-Scale-SQL中每个模块的有效性。结果列于表2中。
Agentar-Scale-SQL不带任务理解:在此变体中,总体EX下降了0.45,这表明任务理解模块解决了SQL子句所需的值和问题本身的措辞中的歧义。
Agentar-Scale-SQL不带推理SQL生成器:删除推理SQL生成器会导致性能下降最严重,总准确度下降4.89个点。这一结果有力地证明了内在缩放方法的有效性。它对于生成准确的SQL逻辑并与目标数据的偏好保持一致至关重要,这是解决复杂问题不可或缺的资产。
Agentar-Scale-SQL不带ICL-SQL生成器:当排除ICL-SQL生成器时,总准确度下降了3.78个点,这是观察到的第二大下降。值得注意的是,在具有挑战性的问题上的性能从64.14下降到55.86。这突显了我们两个生成器的互补性质。ICL生成器擅长利用上下文示例来构建复杂的查询,为获得正确的解决方案提供了有效的替代途径。使用两个互补生成器的并行扩展确保了多样化且高质量的候选SQL查询池,这对于实现高性能至关重要。
Agentar-Scale-SQL不带迭代改进:我们还通过消融研究分析了迭代改进模块的贡献。移除该模块导致性能下降0.52个百分点,我们将其归因于该模块能够优化SQL并纠正语法和语义错误。
Agentar-Scale-SQL不带SQL选择扩展:Agentar-Scale-SQLw/oSQL选择扩展表示我们采用自一致性(即基于执行结果的多数投票)来选择最佳SQL。我们可以观察到,在EX指标上,我们的方法比自一致性基线降低1.82个百分点。这是因为执行频率最高的结果不一定就是正确的。我们的选择策略,可能比简单的频率统计包含了更多的信号,被证明是识别正确查询更有效、更鲁棒的方法。
生成器组件分析 (RQ3)
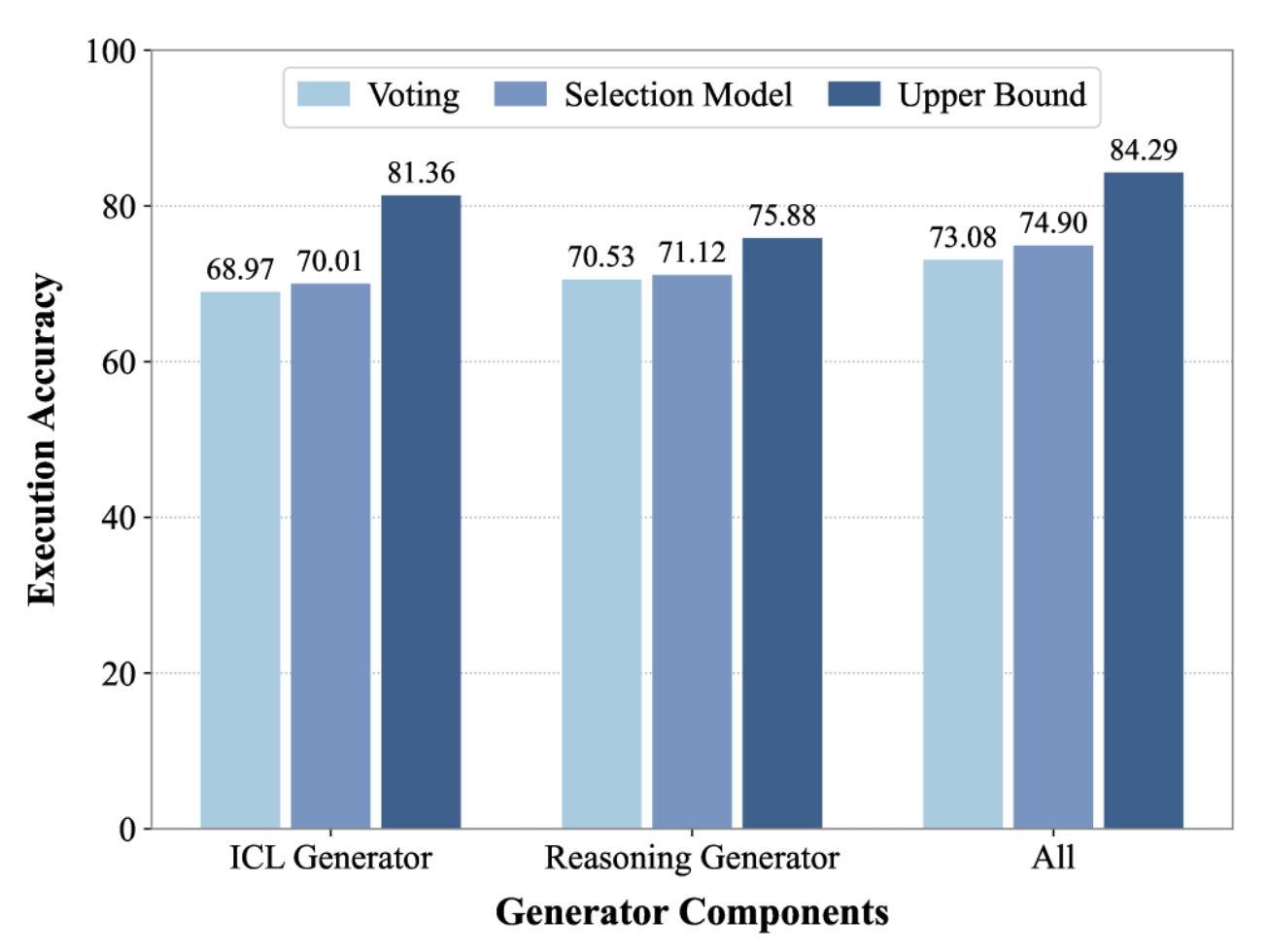
如图3所示,ICL生成器实现了比推理生成器(75.88%)明显更高的上限准确率(81.36%),表明其在生成正确查询方面具有巨大潜力。然而,结合它们的输出来看(All),实现了最高的总体上限84.29%。如图4所示,这种协同增益可以由它们的互补性质来解释。虽然他们共享大量正确的解决方案,但他们还分别独特地解决了47个和12个样本。这种扩大的覆盖范围适用于所有难度级别(图5)。按难度细分表明,推理生成器在简单和中等任务上具有优势,而ICL生成器在挑战性问题上更有效。
最终,这个更丰富、更多样化的候选库使我们的最终选择策略达到了74.90%的峰值准确率,证明了双生成器方法的关键作用。
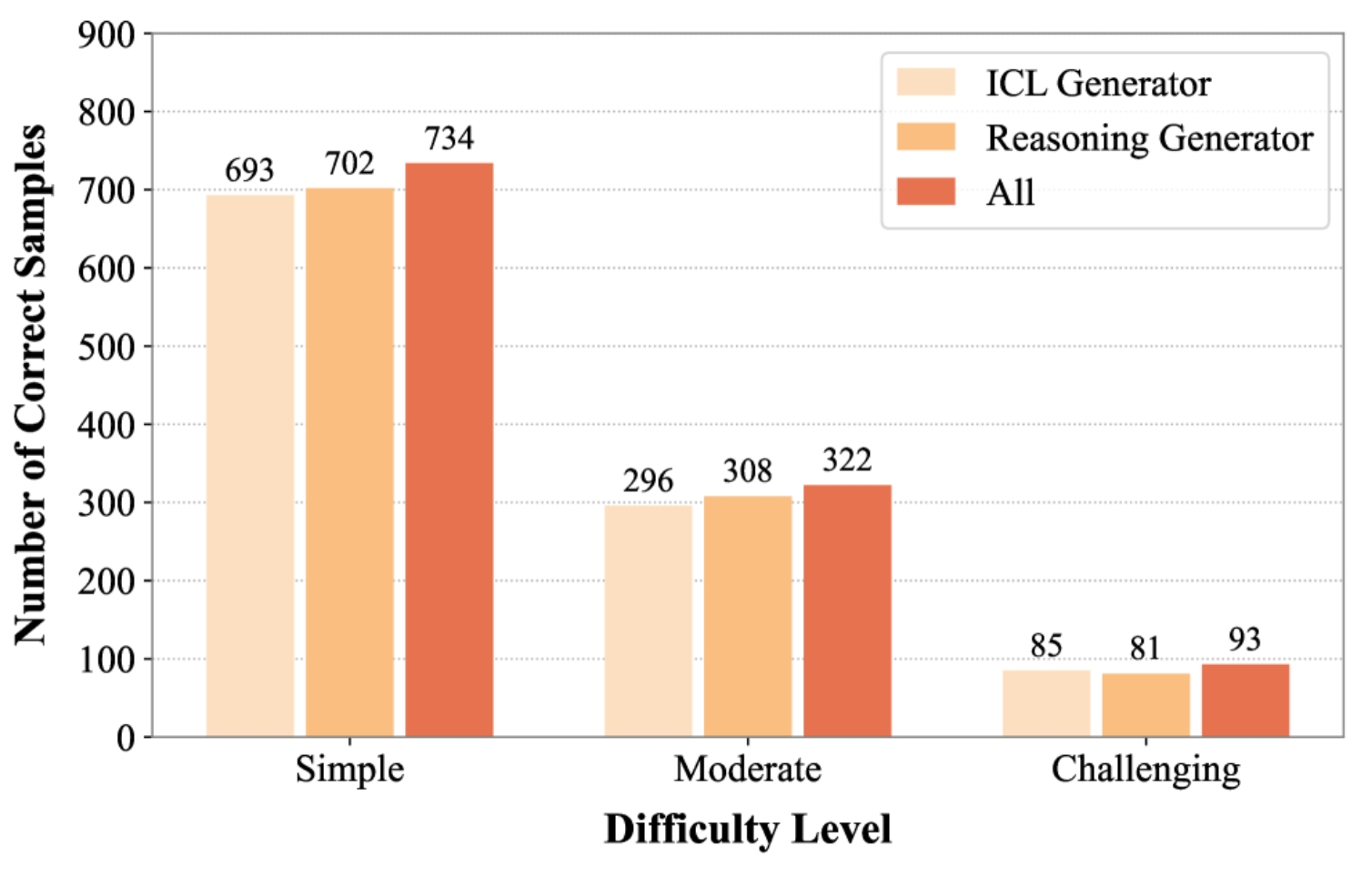
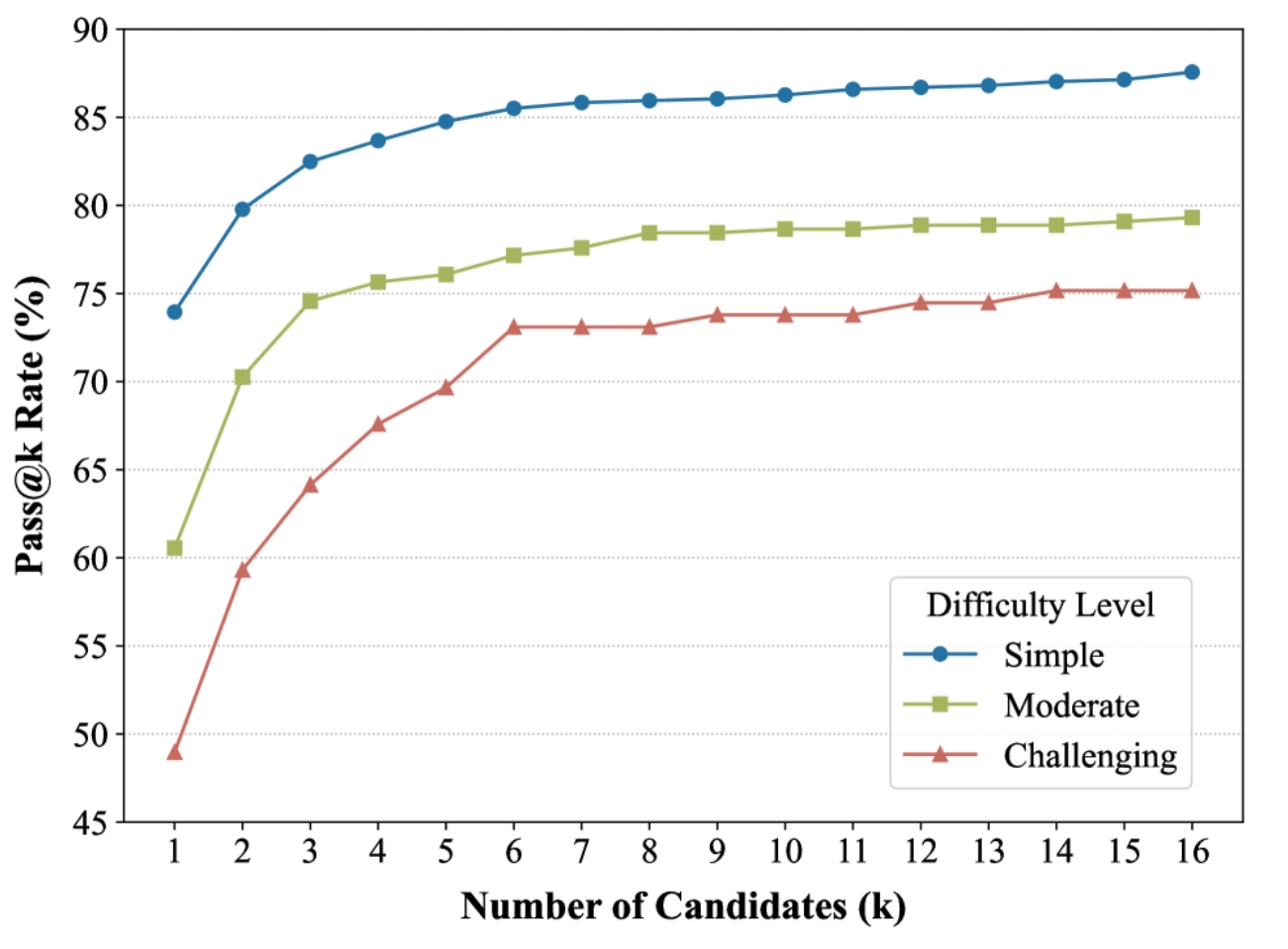
候选人数量的影响(RQ4)
最后,我们通过将候选数从1更改为16来研究其影响。结果如图6所示,表明增加后选人数量可以持续提高所有难度级别的Pass@k率。对于具有挑战性的查询,这种改进最为显着,并且当将候选项增加到8个时,这种改进最为显着,之后增益就会减小。这验证了我们并行扩展策略的有效性。
结论
我们引入了 Agentar-Scale-SQL,这是一种新颖的框架,它通过协同组合内部、顺序和并行扩展策略来显着提高Text-to-SQL 的性能。 我们的方法在具有挑战性的 BIRD 基准上取得了 SOTA 结果,展示了实现人类水平准确性的有效途径。 我们发布代码和模型来支持该领域的未来研究。
在通过测试时间缩放成功提高智能性的基础上,我们正在开拓我们的下一个方案:训练时扩展。 我们将赋予新一代Agent通过行动学习并从经验中发展的能力。
局限性
尽管Agentar-Scale-SQL非常有效,但它对精心策划的测试时间扩展的依赖带来了一些关键限制。该框架的主要缺点是由于多次LLM调用生成、细化和选择而导致大量计算开销和高延迟,使其不太适合实时应用程序。在我们的商业实践(开发B2BChatBI产品)中,我们观察到企业客户将准确性放在首位。在决策场景中,幻觉的SQL查询是不可接受的,而对于复杂的分析生成来说,几秒的延迟通常是可以容忍的。Agentar-Scale-SQL专为弥补这些生产要求的"最后一英里"准确性而设计。此外,它的性能从根本上受到底层基础LLM的能力的限制,并且它很容易受到级联错误的影响,其中早期阶段的失败(例如任务理解)可能会损害整个过程。
Comments NOTHING