
MetaData
- 发表时间 2025.01.08
- 作者:Haoyu Han, Yu Wang, Harry Shomer, Kai Guo, Jiayuan Ding, Yongjia Lei, Mahantesh Halappanavar, Ryan A. Rossi, Subhabrata Mukherjee, Xianfeng Tang, Qi He, Zhigang Hua, Bo Long, Tong Zhao, Neil Shah, Amin Javari, Yinglong Xia, Jiliang Tang
- 项目链接:https://github.com/Graph-RAG/GraphRAG/
摘要
RAG通过从外部资源中检索附加信息,如知识、技能和工具等来增强下有任务的执行。知识图谱有着节点由边连接的特性,编码了大量的实体和关系信息,能够成为RAG应用的宝贵资源。在传统的RAG中,检索器、生成器和外部数据可以在神经嵌入空间中统一设计。而图谱数据结构包含多种格式和特定领域的关联知识,这使得不同领域设计GraphRAG时带来了重大挑战。鉴于GraphRAG的广泛适用性、设计挑战性和应用激增,迫切需要对其关键概念和相关技术进行系统性综述。本着这一动机,我们对GraphRAG进行了最新且全面的综述。综述首先通过定义其关键组件(包括查询处理器query processor、检索器retriever、组织器organizer、生成器generator和数据源data source)提出了一个完整的GraphRAG框架。此外,由于不同领域的图谱表现出不同的关系模式,需要进行定制化设计,论文回顾了针对每个领域量身定制的GraphRAG技术。最后,论文讨论了研究可能面临的挑战。
Introduction
检索增强生成 (RAG) 作为一种通过从外部数据源检索附加信息来改进下游任务的强大技术,已成功应用于各种实际应用。 在RAG框架中,检索器根据用户定义的查询或任务指令搜索附加的知识、技能和工具。然后,检索到的内容由组织器进行细化,并与原始查询或指令无缝集成,然后将其进一步馈送到生成器以生成最终答案。例如,在进行问答(QA)任务时,经典的“先检索后阅读(Retriever-then-Reader)”框架检索外部事实知识以提高答案的准确性,这极大地促进了社会福祉(faithfulness)并减轻了高风险场景(即医疗、法律、金融和教育咨询)中的风险。此外,LLM的最新进展进一步强调了 RAG在增强LLM社会责任方面的作用,例如减轻幻觉(mitigating hallucinations)、增强可解释性和透明度(interpretability and transparency)、实现动态适应性(dynamic adaptability)、降低隐私风险(privacy risks)、确保可靠/稳健(reliability/robust)的回答以及鼓励公平对待(fair treatment)。
基于RAG的成功,并进一步考虑到图在现实世界应用中的普遍性,最近的研究探索了将RAG与图结构数据相集成。与文本或图像数据不同,图结构数据通过其内在的“节点由边连接”的特性编码异构和关系信息。例如,社交网络中通过社交关系连接的个体通常表现出同质性行为,计划中的顺序决策步骤遵循因果依赖性,以及分子内属于同一官能团的原子具有独特的结构特性。 设计利用关系信息的RAG需要调整其核心组件,例如检索器和生成器,以无缝集成图结构数据,从而产生GraphRAG。与主要使用语义/词汇(semantic/lexical)相似性搜索的RAG不同,GraphRAG 通过利用基于图的机器学习(例如,图神经网络(GNN))和图/网络分析技术(例如,图遍历搜索和社区检测)在捕获关系知识方面具有独特的优势。例如,考虑查询“用于治疗类上皮肉瘤并同时影响 EZH2 基因产物的药物有哪些?”,盲目执行仅依赖于语义/词汇相似性的现有 BM25 或基于嵌入的搜索会忽略图结构中编码的关系知识。相反,一些 GraphRAG 方法沿着关系路径“疾病(类上皮肉瘤)->[适应症]->药物->[靶点]->基因/蛋白质(EZH2 基因产物)”遍历图,以检索遵循关系[适应症]的类上皮肉瘤疾病的邻居,遵循关系[靶点]的基因EZH2的邻居,并找到它们相交的药物。此外,某些领域涉及具有极其复杂几何形状的实体。例如,分子图中的3D结构以及产品分类法(例如,亚马逊上的产品分类法)、文档分段(例如,使用Adobe Acrobat时)和社交网络(例如,Snap上的社交网络)中常见的层次树结构,需要精心设计的图编码器(或更准确地说,几何编码器),并具有适当的表达能力来捕捉结构细微之处。简单地将节点文本口语化并将其输入LLM无法表达复杂的几何信息,并且由于邻域层增大而导致文本描述呈指数级增长,这变得不可行。
尽管GraphRAG比RAG具有上述优势,但由于图结构数据的以下差异,设计合适的GraphRAG面临着前所未有的挑战:
- 差异1:统一对(versus)vs多样化格式的信息:在传统的RAG中,语义信息可以统一表示为图像块的二维网格或文本语料库的一维序列。与传统的RAG不同,图结构数据通常包含多种格式,并存储在异构的来源中。例如,文档图将实体嵌入为句子块,知识图将图信息存储为三元组或路径,而分子图由高阶结构(例如,细胞复合体)组成,如图1所示。一些图数据甚至可能是多模态的(例如,文本属性图包含结构和文本属性,场景图结合了结构和视觉)。因此,这种多样性需要不同的RAG设计。对于检索器而言,传统的RAG假设目标信息已编入图像或文本语料库的索引,这些信息可以统一表示为向量嵌入,并支持一刀切(one-size-fits-all)的基于嵌入的检索。但是,GraphRAG的检索器必须考虑所需信息的具体格式和来源,使得一刀切的设计变得不切实际。在处理知识图谱问答时,节点、边或子图的信息通常在基于嵌入匹配的检索之前通过图搜索获取。此获取操作通常通过实体链接、关系匹配和图搜索算法(例如,广度优先搜索、深度优先搜索、蒙特卡洛树搜索和 A* 搜索)来识别相关的节点/边/子图,如果仅通过基于深度学习的嵌入相似性搜索则无法实现。此外,检索器的设计应确保足够的几何表达能力以捕捉结构细微之处。例如,当从计划图中检索API以实现特定目标时,为检索器配备方向感知能力至关重要。足够的方向感知能力能够使检索器以正确的顺序执行具有资源依赖性的API,从而防止冲突,避免无效操作。同样,设计能够区分高阶子图结构(例如,6环苯与4星甲烷,以及3星T形路口与4 方形道路)的表达性检索器对于药物设计疾病治疗和城市规划道路建设至关重要。除了检索器之外,生成器也需要专门的设计。当检索到的内容包含具有文本属性的复杂图结构时,简单地将子图的文本口语化并将其连接到提示中可能会模糊关键的结构信息。在这些情况下,在将其集成到生成之前,使用GNN 等图编码器对图进行编码可以帮助保留结构细微之处。
- 差异2:独立信息与相互依赖信息:在传统的RAG中,信息是独立存储和使用的。例如,文档被分割成块,例如单个句子、段落或固定数量的符元(tokens),这取决于文档上下文和下游任务。然后,每个块都独立地索引并存储在向量数据库中。这种独立性阻止了检索捕获块关系,这阻碍了需要多跳推理(multi-hop reasoning)和长篇规划(long-form planning)的任务的性能。然而,GraphRAG将块存储为相互连接的节点,边表示它们之间的关系,这有利于检索、组织和生成。对于检索,这些边可以实现多跳遍历以捕获与现有检索块具有逻辑连接的其他块。此外,检索到的内容可以根据其语义含义(例如,重新排序)以及它们的结构关系(例如,图剪枝)进行组织。在生成阶段,将相互依赖性(例如,位置编码)压缩到生成器中,会将更多结构信号编码到生成的内容中。
- 差异3:领域不变性(Domain Invariance)与领域特定(Domain-specific)信息:图结构数据中的关系是特定于领域的。与图像和文本不同,图像和文本中不同的领域通常共享可转移的语义,例如图像中的纹理和颗粒,或文本中由分词器定义的词汇表,图结构数据缺乏明确的可转移单元。图像和文本中这种共享的基础为设计具有几何不变性的编码器奠定了基础,并实现了众所周知的数据缩放定律。然而,对于图结构数据,控制生成的图的底层数据生成过程在不同领域之间差异很大。这种可变性使得关系信息高度特定于领域,几乎不可能设计一个适用于不同领域的统一GraphRAG。例如,在预测学术论文主题时,广泛接受的同质性假设建议从论文中检索参考文献来告知其主题预测。然而,这种同质性假设不适用于对航班网络中机场角色进行分类的情况,在该情况下,枢纽通常稀疏地分布在一个国家/地区,没有直接连接。此外,即使来自同一领域的同一图,不同的任务也可能需要不同的GraphRAG设计。例如,在设计自动电子邮件完成系统以优化公司沟通效率时,应同时考虑内容相关性和语气一致性[428]。为了确保生成电子邮件的内容相关性,人们可能会假设紧密的电子邮件(即来自同一对话线程的电子邮件)共享类似的内容,因此应该检索它们作为参考。然而,为了保持语气的一致性,可能会检索来自具有类似角色的员工的电子邮件,即使它们不共享紧密的社会关系(例如,下属和上级之间),而是扮演公司中类似的结构角色(例如,不同团队的经理)。
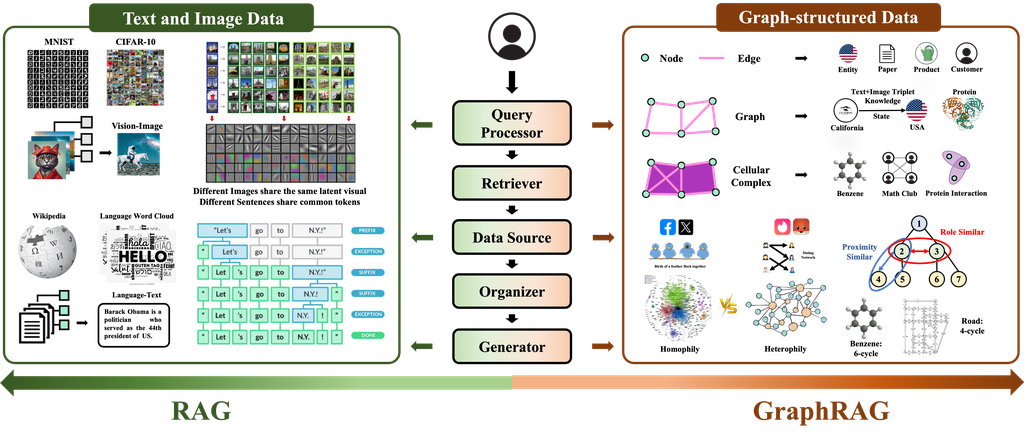
图1 RAG和GraphRAG的区别。RAG处理文本和图像数据,这些数据可以统一格式化为一维序列或二维网格,没有关系信息。 相反,GraphRAG处理图结构数据,它包含多种格式,并包括特定领域的关联信息。
尽管上述差异推动了GraphRAG的大量研究,但该领域的当前研究现状仍然处在碎片化(fragmented),不同研究在概念、技术和数据集方面存在显著差异。此外,当前的GraphRAG研究主要集中在图2中所述的知识图和文档图上,常常忽略了在其他领域(如基础设施图)的更广泛应用。这种不平衡不仅阻碍了GraphRAG的发展,而且还可能造成“泡沫效应(bubble effect)”,限制了未来探索的范围。为了应对这些挑战,我们对GraphRAG进行了全面且最新的综述,旨在从全局角度统一GraphRAG框架,同时从局部角度专门针对每个领域设计其独特的方案。
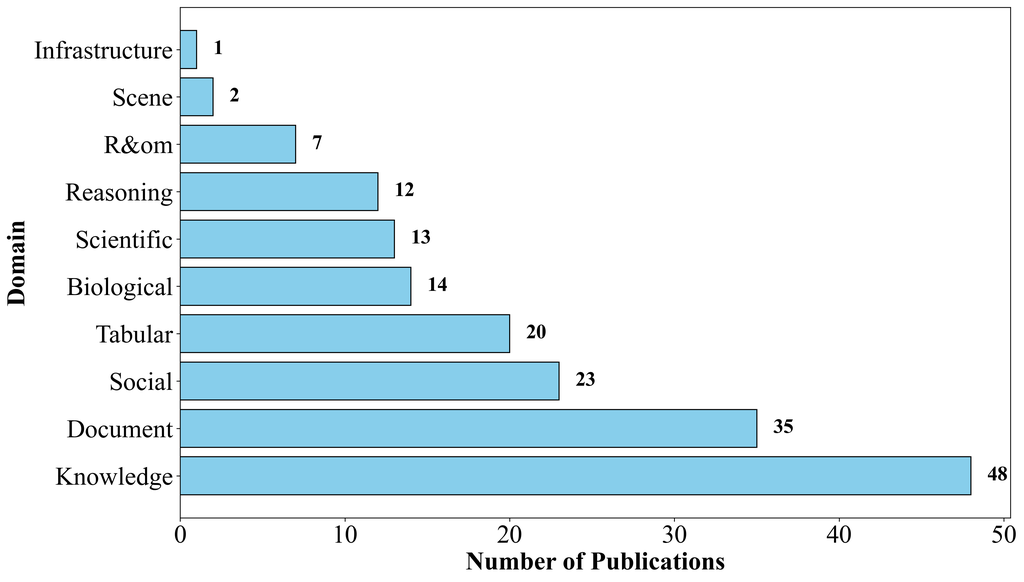
图2 基于本综述中回顾的论文,不同领域GraphRAG的出版物数量
本综述的主要贡献如下:
- GraphRAG的整体框架:论文提出了一个由五个关键组件组成的GraphRAG整体框架:查询处理器、检索器、组织器、生成器和图数据源。在每个组件中,我们回顾了具有代表性的GraphRAG技术。
- 不同领域GraphRAG的专门化:根据其具体应用将GraphRAG设计分为10个不同的领域,对于每个领域,回顾了它们的独特应用和具体的图构建方法。随后,论文总结了所提的整体GraphRAG框架中每个组件的独特设计,并收集了丰富的基准数据集和工具资源。10个领域包括:
- 文档图(document graph)
- 科学图(scientific graph)
- 社会图(social graph)
- 规划和推理图(planning&reasoning graph)
- 表格图(tabular graph)
- 基础设施图(infrastructure graph)
- 生物图(biological graph)
- 场景图(scene graph)
- 随机图(random graph)
- 挑战与未来方向:我们重点介绍了当前图RAG研究的挑战,并指出了将图RAG推进到新前沿的未来机遇。
下面,论文重点介了与现有综述之间的区别。尽管迫切需要对图RAG进行系统的概述,但大多数现有综述都关注独立同分布数据上下文中的通用RAG。在大型语言模型(LLM)出现之前,早期的综述侧重于文本RAG。随着LLM等基础模型最近取得了前所未有的成功,各种综述探讨了由基础模型驱动的不同模态的RAG。Gao等人将现有的RAG方法分为三类(朴素的(naive)、高级的(advanced)和模块化的(Modular)RAG),总结了三种核心技术(检索、生成和增强),并回顾了评估指标。与此同时,Zhao等人根据相应的应用和数据模态回顾了具有代表性的RAG系统。另一篇论文侧重于回顾RAG的可信度问题和技术。然而,它们都没有专门关注图结构数据。据我们所知,只有一项非常近期的研究专门调查了图结构数据上下文中的RAG。然而,这项工作主要侧重于回顾在传统RAG架构下由图引入的技术,而没有专门回顾不同领域中图的多样关系和技术设计。与其整体回顾理念相反,论文认识到图结构数据的内在异质性,并在不同领域专门对图RAG进行综述。具体来说,我们揭示了每个领域的根本任务应用(何时检索)、图构建方法和关系原理(检索什么)以及图RAG技术(如何检索)。通过这种方式,我们的综述为信息检索、数据挖掘和机器学习社区提供了关于图RAG的全面概述,以及促进跨学科研究和产业机遇的领域特定见解。
论文的综述结构如下:第2节介绍了图RAG的整体框架,并介绍了其五个关键组件的代表性技术。从第3节到9节,我们将深入探讨具体的领域,回顾独特的任务应用,总结指导该领域GraphRAG设计的现有图构建方法,突出所提整体框架内五个组件的特定领域技术,并介绍跨不同领域使用的现有GraphRAG资源(例如,基准数据集和工具)。最后,在第10节讨论研究挑战和机遇,并在第11节进行总结。
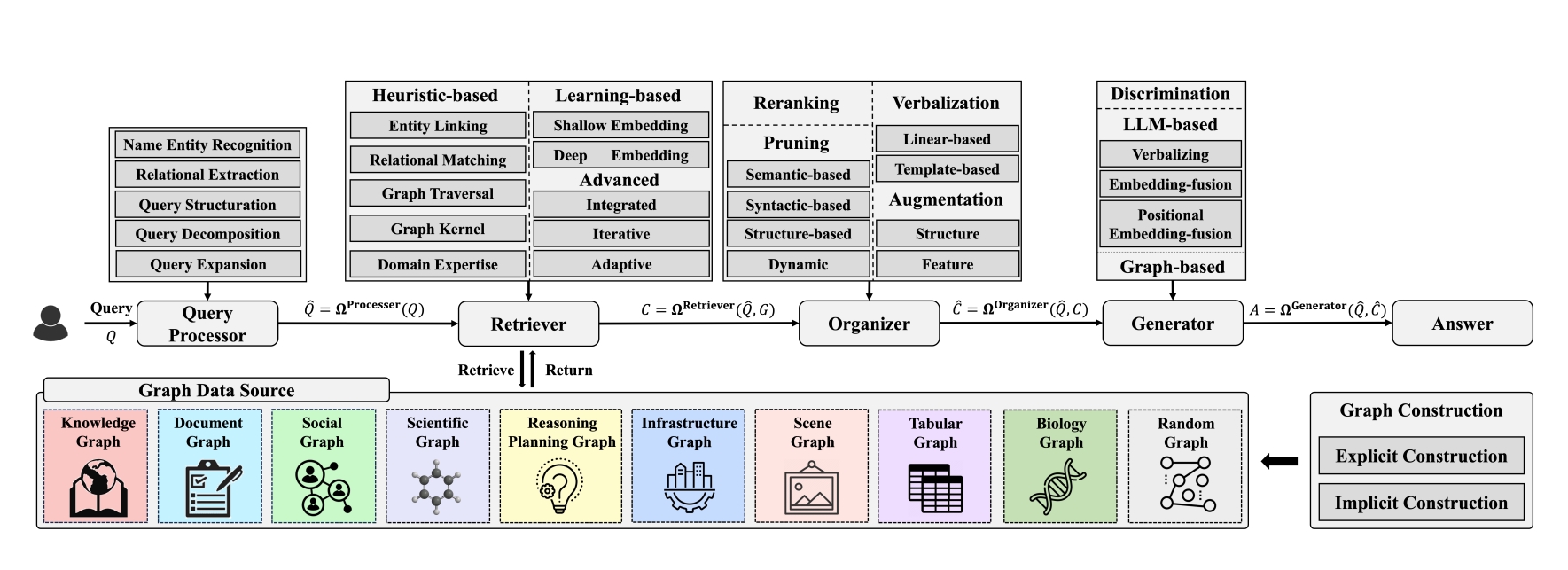
图3 GraphRAG的整体框架及其关键组件的代表性技
GraphRAG的整体框架
基于GraphRAG的现有文献,本文提出了一个GraphRAG的整体框架。接下来,论文将介绍整个框架中使用的基本问题设置和符号。
问题和符号设置
遵循RAG的一般设置,给定一个图结构的数据源G,用户定义的查询Q被进一步发送到查询处理器\Omega^{Processor}以获得预处理的查询\hat{Q}。之后,检索器\Omega^{Retriever}基于\hat{Q}从图数据源G检索内容C。接下来,检索到的内容C由组织器\Omega^{Organizer}细化以形成细化后的内容\hat{C}最后,细化后的内容
\hat{C}触发生成器\Omega^{Generator}生成最终答案A。上述五个组件总结如下:
- 查询处理器\Omega^{Processor}:预处理给定的查询\hat{Q}=\Omega^{Processor}(Q)
- 图数据源G:以图结构格式组织的信息
- 检索器\Omega^{Retriever}:基于查询\hat{Q}从G检索内容C=\Omega^{Retriever}(\hat{Q},G)
- 组织器\Omega^{Organizer}:
排列和细化检索到内容\hat{C}=\Omega^{Organizer}(\hat{Q},C) - 生成器:生成答案A=\Omega^{Generator}(\hat{Q},\hat{C})以回答查询Q
与基于序列的文本数据和网格结构的图像数据不同,图结构数据封装了关系信息。为了有效地利用这种关系信息,GraphRAG以上五个核心组件需要专门的设计来处理图结构的输入/输出并支持基于图的操作。例如,在检索组件中,自然语言处理(NLP)中传统的RAG使用稀疏/密集编码器进行索引搜索。相反,GraphRAG采用图遍历方法(例如,实体链接和 BFS/DFS)和基于图的编码器(例如,图神经网络 (GNN))来生成用于检索的嵌入。这促使论文在下面的整体GraphRAG 框架下,总结GraphRAG中每个上述五个组件的关键创新和代表性设计。
任务应用和示例查询Q
与一般的 RAG 框架类似,其中文本格式的查询Q指定问题上下文或任务指令。 GraphRAG中的查询Q也可以是文本格式的。例如,在基于知识图谱的问答中,查询可以是“中国的首都是什么?”。此外,查询也可以采用其他格式,例如分子图的微笑字符串,甚至可以是多种格式的组合,例如场景图和文本指令。表1总结了每个领域中使用的常见任务应用和示例查询,以及它们的代表性参考文献。
查询处理器\Omega^{Processor}
在传统RAG中,查询和数据源都纯粹是文本格式的,GraphRAG中使用的数据源是图结构的,这给桥接文本格式的查询和图结构的数据源带来了挑战。例如,连接知识图谱和查询“贾斯汀·比伯的兄弟是谁?”的信息不是一段具体的文本,而是实体“贾斯汀·比伯”和关系“兄弟”。许多技术被提出来正确地从查询中提取这些信息,包括实体识别(entity recognition)、关系抽取(relational extraction)、查询结构化(query structuration)、查询分解(query decomposition)和查询扩展(query expansion)。下面,论文首先回顾在更广泛的NLP领域中这五种查询处理技术的每一种,然后重点考察它们在GraphRAG中的独特适应。
命名实体识别 Name Entity Recognition
命名实体识别(NER)旨在识别来自文本中属于预定义类别(例如人、地点或组织)的实体提及,它是许多自然语言应用程序的基础组件。NER技术可以大致分为四种主要方法:
- 基于规则的方法,完全依赖手工规则,不需要标注数据;
- 无监督学习方法,使用无监督算法,无需标记的训练样本;
- 基于特征的监督学习方法,依赖于监督算法和仔细的特征工程;
- 深度学习方法,在(无)监督训练深度学习模型后自动发现所需的表示。
最近的大语言模型(LLM)属于深度学习方法的范畴,并在NER方面取得了前所未有的成功。 关于这些技术及其资源的更多详细信息,请参见Li等人。
特别是在GraphRAG环境中,实体识别主要使用深度学习技术(例如,EntityLinker和基于LLM的提取)来识别由给定图数据源中的节点接地的查询中的实体。此步骤对于基于知识图谱的问答等应用至关重要。例如,给定问题“猜测婴儿眼睛颜色的最佳方法是什么?”,NER提取诸如“婴儿”、“眼睛”和“颜色”之类的实体,这些实体对应于知识图谱中的节点,并被视为随后初始化检索过程的种子节点。对于更新的GraphRAG研究,命名实体识别(NER)已经发展到不仅识别实体名称,还识别其结构。例如,Jin等人利用大型语言模型(LLM)识别图中的节点类型,这进一步指导检索器识别与已识别类型匹配的节点,以进行下一轮探索。例如,给定问题“谁是‘语言模型是无监督的多任务学习器’的作者?”,最初识别的实体不应仅仅基于语义名称“语言模型是无监督的多任务学习器”,还应基于该实体的类型,在本例中是论文节点。精确识别GraphRAG中实体的名称和结构可以减少级联错误,并为后续的检索和生成步骤提供坚实的基础。
关系抽取 Relational Extraction
与命名实体识别类似,关系抽取(RE)是自然语言处理中一项长期存在的技术,用于识别实体之间的关系,并广泛应用于结构化搜索、情感分析、问答、摘要和知识图谱构建。关系抽取的最新进展主要由深度学习技术驱动,可以概括为三个方面:文本表示、上下文编码和三元组预测,更多细节可以在Pawar等人、Nasar等人、Han等人中找到。
对于GraphRAG,关系抽取有两个关键作用:通过抽取三元组构建图结构的数据源(例如,知识图谱),以及匹配查询和图数据源中提到的关系以指导图搜索。例如,给定一个查询“中国的首都是什么?”,关系抽取识别关系“首都是”,并通过知识图谱中的向量相似性搜索对应的边,这指导了邻域选择和图遍历方向。
结构化查询 Query Structuration
查询结构化将查询转换为适合特定数据源和任务的格式。 它通常将自然语言查询转换为结构化格式,如SQL或SPARQL,以与关系数据库交互。最近的进展利用预训练和微调的大型语言模型(LLM)从自然语言输入生成结构化查询来查询数据库。 对于图结构数据,图查询语言(GQL)已经出现,例如Cypher、GraphQL和SPARQL,这使得与属性图数据库进行复杂交互成为可能。此外,Jin等人提出了一种技术,将复杂的查询分解为多个结构化操作,包括节点检索、特征获取、邻居检查和度评估,从而提高了查询的精度和适应性。
查询分解 Query Decomposition
查询分解旨在将输入查询分解成多个不同的子查询,这些子查询首先用于检索子结果,然后将这些子结果聚合在一起以获得最终结果。在大多数现有的RAG和GraphRAG中,分解后的查询通常具有明确的逻辑连接,可以处理需要多步骤推理和规划的复杂任务。例如,像“请生成一张图片,图片中一个女孩正在看书,她的姿势与‘example.jpg’中的男孩相同,然后用你的声音描述这张新图片”这样的查询包含多个子任务,每个子任务都将由一个特定的子查询完成。此外,Park等人通过构建一个问题图来增强查询的分解,其中每个子查询都表示为图中的三元组。这些图结构的子查询有效地指导检索器/生成器进行多步骤提示。
查询扩展 Query Expansion
查询扩展通过添加具有相似意义的有意义的术语来丰富查询,这主要解决了三个挑战:
- 用户提交的查询含糊不清,与多个主题相关;
- 查询可能过于简短,无法完全捕捉用户意图;
- 用户经常不确定他们在寻找什么。通常,它可以分为手动查询扩展、自动查询扩展和交互式查询扩展。 最近,由于生成内容的创造性,基于LLM的查询扩展已成为一个突出的领域。
与大多数专注于文本相似性并忽略关系的现有方法不同,GraphRAG中的查询扩展通过结构化关系增强了LLM扩展。例如,Xia 等人通过利用查询中提到的实体的相邻节点来扩展查询。或者,Wang等人使用预定义的模板将查询转换为几个子查询。
检索器\Omega^{Retriever}
获得处理后的查询\hat{Q}后,检索器\Omega^{Retriever}从外部图源G识别和检索相关内容C,以增强下游任务的执行:
$$C=\Omega^{Retriever}(\hat{Q},G)$$
最近,检索器越来越多地与LLM集成,以减轻幻觉(hallucination)问题,解决隐私问题,并增强可解释性和动态适应性(dynamic adaptability)。虽然有效,但它们主要针对文本和图像设计,并且由于以下两个原因,并不容易转移到GraphRAG的图结构数据。首先,GraphRAG的输入/输出格式与传统的RAG大相径庭。RAG中大多数检索器使用NLP分词器进行编码,并遵循“文本输入,文本输出”的工作流程,而 GraphRAG的工作流程更加多样化,包括“文本输入,文本输出”、“文本输入,图输出”、“图输入,文本输出”和“图输入,图输出”流程。其次,传统RAG中的检索器不会捕获图结构信号。像BM25和TF-IDF这样的方法主要关注词汇(lexical)信号,而基于深度学习的检索器通常捕获语义(semantic)信号,两者都忽略了图结构信号。这促使论文回顾现有的GraphRAG检索器,即基于启发式(heuristic-based)、基于学习和特定领域(domain-specific)的检索器,特别强调它们针对图结构数据而调整的独特技术设计。
基于启发式的检索器 Heuristic-based Retriever
基于启发式的检索器主要使用预定义规则、特定领域的见解和硬编码算法从图数据源中提取相关信息。它们对显式规则的依赖通常使其比深度学习模型更省时/省资源。例如,像BFS或DFS这样的简单图遍历方法可以在线性时间内执行,而无需训练数据。然而,这种对固定启发式的依赖也限制了它们对未见场景的泛化能力。下面,论文回顾GraphRAG中常用的基于启发式的检索器。
实体链接:在基于启发式的检索器中,实体链接涉及将查询中识别的实体映射到图数据源中的相应节点。此映射在查询和图之间建立了初始桥梁,既可以作为检索器本身,也可以作为进一步图遍历的基础,以拓宽检索范围。此方法的有效性取决于查询处理器进行的准确实体识别以及图节点上标记实体的质量。此技术通常应用于知识图谱中,其中基于Top-K节点与其文本与查询的相似性选择作为起点。相似性度量可以使用向量嵌入和词汇特征来计算。最近,LLM已被用作知识上下文增强器,以生成以提及为中心的描述作为附加输入,以增强长尾实体,其中其有限的训练数据通常会导致实体链接模型难以消除歧义。
关系匹配:关系匹配类似于实体链接,是一种基于启发式的检索方法,旨在识别图数据源中与查询中指定的关联一致的边。此方法对于关注识别图中实体之间关系的任务至关重要。 匹配的边通过指示接下来基于在图数据源中遇到的实体和关系来探索哪些边,从而指导遍历过程。与实体链接类似,基于Top-K边与其在图中的每条边的相似性选择。
除了上述两种基于启发式的检索器的效率和简单性之外,另一个关键优势是它们能够克服歧义。例如,虽然基于机器/深度学习的检索器难以区分语义/词汇上相似的实体/关系(例如,Byte与Bit,以及President与Resident),但这些启发式方法可以基于预定义的规则轻松区分它们,即使在语义/词汇差异细微的情况下也是如此。
图遍历:在执行实体链接和关系匹配以识别图数据源中的初始节点和关系后,图遍历算法(例如,BFS、DFS)可以扩展此集合以发现其他与查询相关的的信息。 然而,基于遍历的检索的核心挑战是信息过载的风险,因为呈指数级扩展的邻域通常包含大量无关内容。为了解决这个问题,当前的遍历技术集成了自适应检索和过滤过程,选择性地探索最相关的相邻节点并逐步细化检索到的内容以最大限度地减少噪声。此图遍历主要用于知识图和文档图的GraphRAG中。
图核方法:与上述用于检索节点、边及其组合子图的基于启发式的方法相比,一些早期工作(例如,图提取和图像检索)将文本和图像视为整个图,并使用图级启发式方法(例如图核)来衡量相似度并进行检索。图核通过计算图之间内积来衡量成对相似性,从而对齐查询和检索图的结构和语义方面。 值得注意的例子包括随机游走核和Weisfeiler-Lehman核。随机游走核通过在两个图上同时进行随机游走并计算匹配路径的数量来计算相似性。Weisfeiler-Lehman核迭代地应用Weisfeiler-Lehman算法来生成每次迭代中节点标签的颜色分布,然后根据这些直方图向量的内积计算相似性。例如,Wu等人构建文档和查询的事件图,并使用计算两个图之间游走的乘积图核来衡量查询-文档相似度并对文档进行排序。 Lebrun等人通过引入一种快速高效的图匹配核来进行事件图匹配,用于图像检索。同样,Glavaš和Šnajder将图像转换为代表性属性结构图,该图捕获区域之间的空间关系,并执行基于随机游走的图核来推导出用于图像检索的哈希码。
领域专业知识:传统基于启发式方法的领域无关性限制了其在需要专业知识领域的有效性。例如,在药物发现中,化学家通常通过参考具有理想性质的现有分子来设计药物,而不是从头开始构建分子结构。这些分子的选择基于指导检索具有相似特征的结构的领域知识。遵循这种直觉,许多GraphRAG系统都结合了领域专业知识来增强检索器的设计。Wang等人开发了一种混合检索系统,该系统集成了基于启发式和基于学习的检索,以检索部分满足目标设计标准的示例分子。
基于学习的检索器
基于启发式方法的检索器的一个显著局限性在于其过度依赖预定义规则,这限制了其对不严格遵守这些规则的数据的泛化能力。例如,当遇到具有细微语义或结构差异的实体时,例如“医生”和“内科医生”,基于启发式方法的检索器(如实体链接)可能会由于其不同的词法表示而对其进行不同处理,尽管它们具有相同的潜在含义。为了克服这一局限性,人们提出了基于学习的检索器,以捕获查询和数据源中对象之间更深层、更抽象、更与任务相关的关联,从而避免仅仅依赖于硬编码规则。这些检索器通常通过使用机器学习编码器将各种格式的信息(例如文本和图像)统一压缩为嵌入(embedding),然后通过基于嵌入的相似性搜索来获取相关信息。值得注意的是,一些使用机器学习编码器生成用于匹配的嵌入的实体链接和关系匹配方法也应该被视为基于学习的检索器。
在传统的 RAG 中,假设查询q和包含n实例S的数据源由相应的编码器嵌入为q=\mathcal{F}_{q}(q)\in\mathbb{R}^{d}和S=\mathcal{F}_{S}(S)\in\mathbb{R}^{n×d},我们根据嵌入空间中预定义的相似性函数\phi通过相似性搜索检索前k个实例。
$\mathcal{S}^{*}=\arg_{k}\max\phi(q,S)$
与使用语言和视觉编码器嵌入文本和图像的RAG不同,GraphRAG检索中使用的编码器通过嵌入节点、边和(子)图,扩展到独立同分布 (i.i.d.) 数据之外。根据输入格式,编码器可以是用于查询的文本编码器、用于图结构的基于图的编码器以及用于文本属性图的集成文本和图编码器。论文特别关注基于图的编码器。现有的基于图的编码器可以广泛地分为浅层嵌入方法——例如Node2Vec和DeepWalk和深度嵌入方法,例如图神经网络(GNN)。下面,论文将回顾这两种编码器及其在GraphRAG中的独特作用。
浅层嵌入方法:浅层嵌入方法,如 Node2Vec和 Role2Vec,学习保留原始图基本结构信息的节点、边和图嵌入。基于可以提取的结构信息类型,这些方法通常分为两类:基于邻近度/角色的嵌入。基于邻近度的方法,如 DeepWalk 和Node2Vec,侧重于保留连接节点的邻近度,确保图中靠近的节点在嵌入空间中也保持靠近。基于角色的方法,如Role2Vec和GraphWave,根据节点的结构角色而不是它们的邻近关系生成节点嵌入。一般来说,这些方法用潜在嵌入向量初始化每个节点,并进行无监督训练,将从图结构中提取的结构信号压缩到嵌入中。在GraphRAG中,基于邻近性的浅层嵌入可以有效地检索在空间上彼此靠近的实体,而基于角色的嵌入可以捕获具有相似角色的实体。例如,基于邻近性的嵌入可用于通过提取具有相似研究主题的论文来检索学术论文,或检索与当前产品共同购买的产品评论。同时,基于角色的嵌入可以支持诸如生成公司电子邮件之类的任务,方法是根据共享的角色或语气检索类似的电子邮件。
深度嵌入方法:虽然浅层嵌入方法将结构信号整合到节点、边或整个图的学习嵌入中,但它们难以利用语义特征,例如学术论文检索的词袋表示或分子检索的原子序数。此外,这些方法缺乏归纳性,每当添加新的节点、边或图时都需要重新初始化和重新训练。这限制大大降低了它们在GraphRAG检索任务中的适用性,因为现实世界中的知识会动态演变,其中新信息不断取代过时的内容,例如在引文网络、社交图和知识图中。为了解决这些限制,学界提出了深度嵌入方法,它不仅联合融合特征和图结构以获得用于检索的嵌入,而且还具有内在的归纳特性,因为新出现的节点/边/图与训练阶段的节点/边/图共享公共特征空间。此类别中最具代表性和最强大的方法之一是GNN,它结合了消息传递的强大功能来编码结构信号以及特征转换来提取与任务相关的信。从数学上讲,l^{th}层图卷积可以表示为:
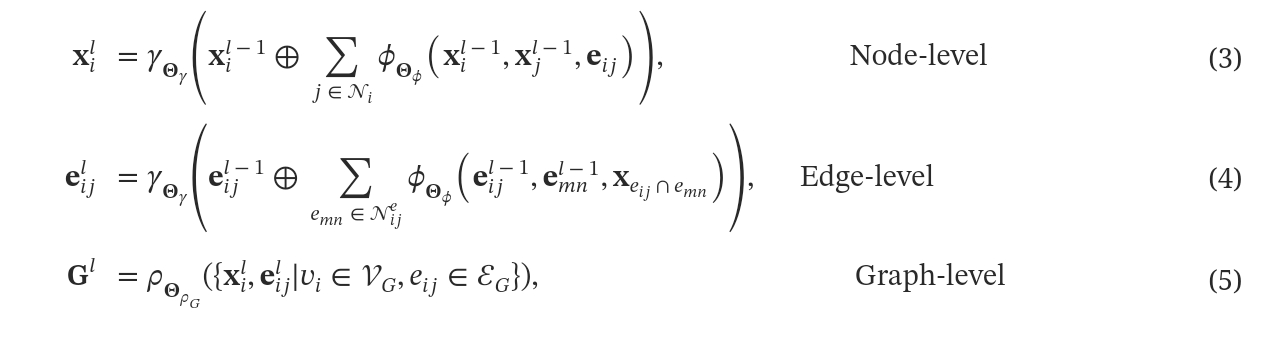
在节点级图卷积中,每个节点v_i自适应地聚合其相邻节点\mathcal{N}_{i}的嵌入,权重基于通过加权函数\phi_{\Theta_{\phi}}的边特征。 然后,使用组合函数\gamma_{\Theta_{\gamma}}将聚合的邻域嵌入与来自前一层x_{i}^{l-1}的节点自身的嵌入相结合,如公式(3)所示。 通过优化来自训练下游任务的损失,可以使加权函数\phi_{\Theta_{\phi}}优先考虑最重要的邻居,并使组合函数\gamma_{\Theta_{\gamma}}能够平衡来自节点邻域和其自身嵌入的贡献。同样,在边级图卷积中,相同的聚合原理适用,但边的邻居是与该边的相同端点关联的边\mathcal{N}_{ij}^{e},如公式(4)所示。图级嵌入可以通过进一步对节点和边嵌入应用池化操作\rho_{\Theta_{\rho}}来获得,如公式(5)所示。 遵循这种基于GNN的嵌入范式,来自不同来源的各种形式的图知识——例如节点、边和(子)图——可以统一嵌入到向量表示中,如图5(c)所示,其中我们推导出节点(𝐗)、边(𝐄)和图(𝐆)的嵌入。
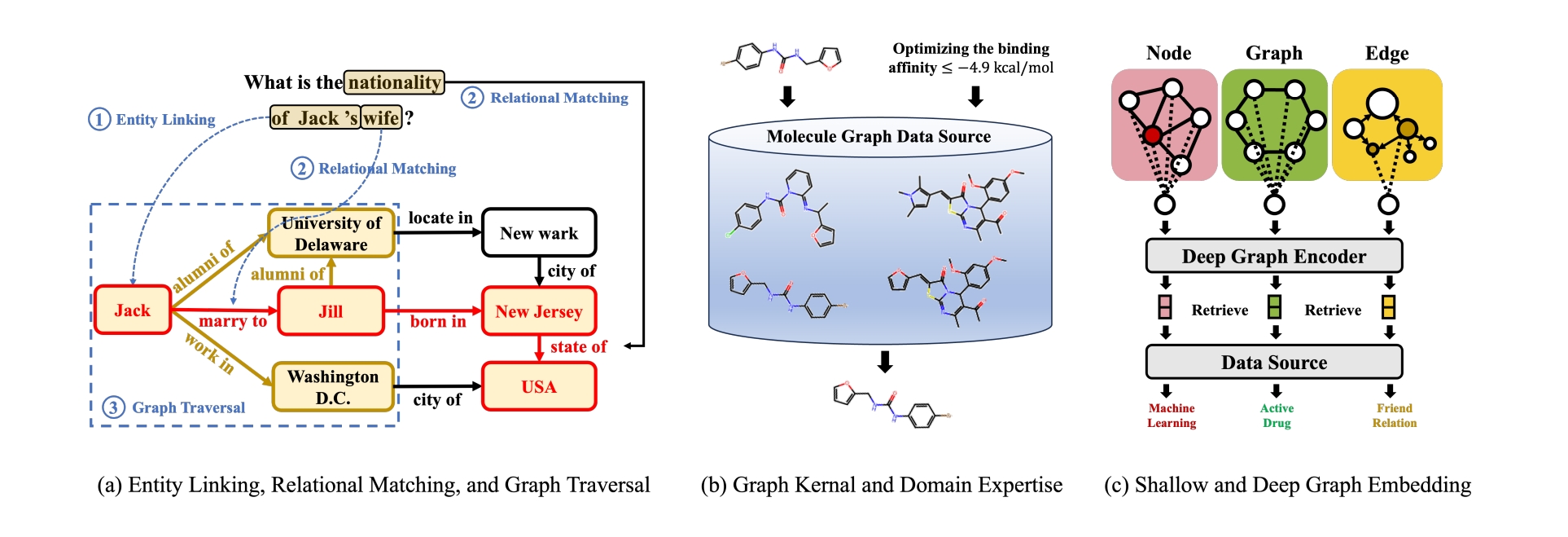
图5 可视化 GraphRAG 中使用的代表性检索器。
获得这些节点/边/图级别的嵌入后,我们可以通过根据每种结构的特定配置组合这些子结构嵌入来创建不同类型结构的嵌入(𝐒)。例如,如果检索到的子图是知识图谱中的路径,我们可以聚合沿该路径的节点和关系的嵌入,以形成一个连贯的路径嵌入。最终,不同结构的生成的嵌入可以在训练阶段用于优化查询对齐,也可以在测试阶段用于启用基于相似性的神经搜索。例如,GNN-RAG使用GNN进行检索,其中对每个查询执行一轮单独的消息传递。查询\hat{Q}通过包含其嵌入在消息计算中,被纳入消息传递中。选择一组“候选”节点,这些节点具有高于某个阈值的关联概率。 从查询节点到每个候选节点的最短路径被检索作为上下文。Liu et al.考虑使用条件GNN,其中只有来自查询的链接实体被初始化为非零表示。候选节点的选择方式与类似。然后为每个候选节点检索一条路径,并通过回溯直到到达查询节点来提取该路径。REANO将查询信息编码到特定于边的注意力权重中,这取决于查询。聚合后,选择与查询最相似的topk个三元组作为上下文。
高级检索策略
真实世界的查询通常很复杂,它们编码多方面的意图,拥有结构模式,并且需要多跳推理,而上述基本检索器难以解决这些问题。例如,回答“位于堪萨斯州劳伦斯市,并在堪萨斯城都会区设有分校的大学的校歌名称是什么?”需要进行多跳推理,以根据位置确定大学并检索其校歌信息。同样,像“数据集的主要主题是什么?”这样的查询需要理解产品社区结构,检索每个社区的主题,并将识别的主题聚合在一起以总结主要主题。此外,当询问“深度学习领域影响力最大的研究学者是谁?”时,答案可能会因多种因素而异,例如引用次数、已发表论文的数量或合著者数量。准确地处理此类查询需要更深入地理解底层数据分布,以辨别查询优先考虑哪个方面。为了处理这些高度复杂的查询,已经提出了先进的检索策略,我们对其进行如下回顾:
集成检索:集成检索结合各种类型的检索器,通过平衡它们的优势和劣势来捕获相关信息。通常,集成检索方法根据组合使用的单个检索器的类型进行分类,值得注意的例子包括神经符号(neural-symbolic)检索和多模态(multimodal)检索。
由于存储在图结构化数据中的知识大多以符号形式存在,因此神经符号检索是GraphRAG中集成检索策略的自然选择。此策略将基于规则的模式用于检索符号知识与基于神经的信号用于检索更抽象和更深层次的知识交织在一起。例如,Luo等人,Wen等人首先基于符号知识图的知识扩展邻居,然后使用神经匹配进行路径检索。相反,Mavromatis和Karypis首先利用GNN检索种子实体(神经检索),然后从种子实体中提取最短路径(符号检索)。同样,Tian等人,Yasunaga等人,Wang等人,Luo等人获取当前问答对和用户生成项会话中提到的实体的k-hop邻域作为答案候选(符号检索),并计算查询和提取的子图之间的注意力以区分候选相关性(神经检索)。
迭代检索:迭代检索是一个多步骤过程,其中连续的检索操作共享共同的依赖关系,例如因果关系、资源和时间依赖关系。这些依赖关系可以通过RAG中的检索顺序隐式地表征,或者在GraphRAG中显式地建模为图结构。因此,迭代检索主要用于GraphRAG以捕获这些依赖关系。例如,KGP在生成问题的下一段证据和选择最有希望的邻居之间交替进行。ToG首先识别初始实体,然后迭代地扩展推理路径,直到收集到足够的信息来回答问题。StructGPT预定义图接口,并提示大语言模型 (LLM) 迭代调用这些接口,直到收集到足够的信息。
自适应检索:虽然检索外部知识具有优势,但也存在风险。如果生成器已经拥有完成任务的足够内部知识,则检索到的外部信息可能是不必要的,甚至可能与内部知识冲突。特别地,当内部知识完全涵盖必要信息时,检索就变得冗余,甚至可能引入矛盾。为了减轻这个问题,在RAG系统中提出了知识检查。此方法允许系统自适应地评估何时以及需要多少外部信息。通过为检索器配备这种自适应性,RAG可以提供更智能、更灵活、更上下文感知的响应,从而促进内部和外部知识源之间更好的协调。
GraphRAG中的一种自适应检索是通过考虑不同查询的不同推理深度来设计的,即,图遍历的跳数太少可能会忽略关键的推理关系,而跳数太多则会引入不必要的噪声。Guo等人,Wu 等人通过训练模型来预测给定查询所需的跳数并相应地检索相关的图内容来解决这个问题。没有现有的工作关注解决 GraphRAG 中的知识冲突,因此,论文将该主题放至未来讨论。
组织者 Organizer
从外部图数据源检索相关内容C后(这些内容可能是实体、关系、三元组、路径或子图的形式),组织者\Omega^{Organizer}会将此内容与处理后的查询\hat{Q}一起处理。目的是对检索到的内容进行后处理和细化,使其更适合生成器的使用,从而进一步提高下游内容生成的质量。正式地,组织者表示如下:

在GraphRAG中,对检索内容进行细粒度组织和细化的需求源于几个关键原因。首先,当检索到的内容是子图时,其在节点/边特征和图结构方面的异构知识格式更容易包含不相关和噪声信息,这给大语言模型(LLM)的理解带来了显著困难,从而影响了生成质量。这就需要采用图剪枝(Graph Pruning)技术来优化检索到的子图并去除与任务无关的知识。其次,LLM已被广泛证明具有对检索上下文内某些相关信息位置的注意力偏差。因此,随着感受野的扩大(即跳数的增加),检索到的子图中呈指数增长邻域也会呈指数增加提示中的上下文长度,并稀释LLM对与任务相关知识的关注。这对基于图的重排序机制提出了新的要求,需要它优先考虑检索图中最重要内容。第三,检索到的内容在语义内容和结构内容方面可能都不完整,这需要进行图增强以进行改进。最后,检索到的内容通常是一个图,它不仅拥有语义内容信息,还拥有其独特的结构。这种复杂的结构内容不容易被通过下一个符元预测以及线性提示训练的LLM所利用,这需要结构感知的表达技术来重新组织。论文将在接下来的章节中正式回顾上述每种组织者技术。
图剪枝
在GraphRAG中,检索到的图可能很大,并且可能包含大量噪声和冗余信息。例如,当在检索中应用图遍历方法时,检索到的子图的大小会随着跳数的增加呈指数增长。子图过大不仅会增加计算成本,还会由于包含噪声信息而降低生成质量。相反,如果跳数太小,则检索到的子图可能太小,缺失任务所需的关键知识。为了在检索子图的大小及其编码的任务相关信息量之间取得更好的平衡,目前已经有各种图剪枝方法,通过去除不相关的节点和边来减小子图的大小,同时保留必要的信息。
- 基于语义的剪枝:基于语义的剪枝专注于通过移除与查询语义无关的节点和边关系来减小图的规模。例如,QA-GNN通过使用大语言模型(LLM)编码查询上下文和节点标签,然后进行线性投影,来剪除具有低相关性分数的无关节点。GraphQA进一步移除与查询相关性最低的节点集群。KnowledgeNavigator基于查询对检索到的图中的关系进行评分,并剪除无关的关系以减小图的规模。此外,Gao等人将检索到的子图划分为更小的子图,然后对它们进行排序,只保留前k个较小的子图用于生成。G-Retriever为每个检索到的节点和边定义语义分数,然后通过解决奖赏收集斯坦纳树问题来构建更紧凑和更相关的子图,从而细化图。
- 基于句法的剪枝:基于句法的剪枝从句法的角度移除无关节点。例如,Su等人利用依存分析生成上下文的句法树,然后根据检索到的节点与句法树的跨度距离过滤这些节点。
- 基于结构的剪枝:基于结构的剪枝方法专注于根据检索图的结构特性进行剪枝。例如,RoK通过计算每条路径的平均PageRank分数来过滤掉子图中的推理路径。其他工作,例如Jiang等人和He等人,也利用PageRank来提取最相关的实体。
- 动态剪枝:与上述方法不同,后者通常只剪枝一次,而动态剪枝在训练过程中动态地移除噪声节点。例如,JointLK使用注意力权重在每一层递归地去除无关节点,只保留固定比例的节点。同样,DHLK在学习过程中动态地过滤掉注意力分数低于一定阈值的节点。
重排序 Reranker
大语言模型(LLM)的性能会受到上下文内相关信息位置的影响,无论它出现在开头、中间还是结尾。此外,LLM的生成还会受到上下文知识提供顺序的影响,后面的文档贡献小于前面的文档。虽然检索到的信息通常在检索过程中按相关性得分排序,但这些得分通常基于对大量候选者进行的粗粒度排序。增强仅在检索到的信息中进行细粒度级别的重新排序(一个被称为重排序的过程)对于实现最佳下游性能至关重要。例如,Li等人使用预训练的交叉编码器对检索到的三元组进行重排序。Jiang等人和Liu等人使用预训练的重排序模型对检索到的路径进行重排序。Yu等人训练了一个图神经网络来对检索到的段落进行重排序。Liao等人按路径出现的时间顺序对路径进行排序,更强调最近的路径。
图增强 Graph Augmentation
图增强旨在丰富检索到的图,以增强内容或提高生成器的鲁棒性。此过程可能涉及向检索到的图添加补充信息,这些信息来自外部数据或嵌入在LLM中的知识。主要有两类方法:
- 图结构增强:图结构增强方法涉及向检索到的图中添加新的节点和边。例如,GraphQA通过合并从上下文中提取的名词短语块节点来增强检索到的子图。此外,Yasunaga等人和Taunk等人将查询视为一个节点,将其集成到检索到的图中,以在查询和相关信息之间创建直接连接。Tang等人基于预训练的扩散模型增强图结构。
- 图特征增强:图特征增强方法侧重于丰富图中节点和边的特征。由于原始特征可能很长或稀疏,因此可以使用数据增强器来总结或提供这些特征的额外细节。例如,Once在推荐系统中使用LLM作为内容摘要器、用户画像器和个性化内容生成器。同样,LLM-Rec和KAR应用各种提示技术来丰富节点特征,使其更利于下游任务。
此外,一些图增强技术只关注检索到的图本身,例如随机删除节点、边或特征以提高模型的鲁棒性。Ding等人对这些数据增强方法进行了系统的综述。
自然语言化 Verbalizing
言语化是指将检索到的三元组、路径或图转换为LLM可以使用的自然语言。 言语化主要有两种方法:线性言语化和基于模型的言语化。
线性言语化方法通常使用预定义的规则将图转换为文本。 线性言语化的主要技术包括:
- 基于元组的方法:这些方法将检索到的不同信息片段放在一个元组中并对其进行排序。例如,在知识图谱上执行检索时,许多方法会检索一组事实。 单个事实在生成提示中被表达为元组(entity1,relation1,entity2)。对于一组事实,我们首先按特定顺序对它们进行排序,然后将它们逐一表达为单个元组。每条信息通常在提示中用换行符分隔。请注意,相同的逻辑可以应用于路径、节点等等。
- 基于模板的方法: 这些方法使用预定义的模板将路径或图表达为更自然的文本。例如,LLaGA提出了一些模板,例如Hop-Field概述模板,用于将图转换为序列。对于知识图谱,有几种方法将单个事实转换为自然文本。例如,Guo等人使用模板“The {relation} of {entity 1} is/are: {entity 2}”将事实(实体1,关系,实体2)转换为文本。
基于模型的表达方法通常使用微调模型或大型语言模型将输入事实转换为连贯自然的语言。 这些方法通常分为两类:
- 图到文本的表达:这些方法专注于将检索到的图转换为自然语言,同时保留所有信息。例如,Koncel-Kedziorski等人和Wang等人利用Graph Transformer从知识图谱生成文本。Ribeiro等人评估了几个预训练语言模型用于图到文本的生成,而Wu等人和Agarwal等人微调大型语言模型以将图转换为句子,确保文本形式忠实地表示图的内容。
- 图摘要:与保留所有细节的图到文本转换不同,图摘要方法旨在根据检索到的图和查询生成简洁的摘要。EFSum提出了两种方法:一种直接提示大语言模型 (LLM) 来总结检索到的事实和查询,另一种则专门针对摘要任务微调大语言模型。另一方面,CoTKR在两种操作之间交替进行:推理,即分解问题,生成推理轨迹,并识别当前步骤所需的特定知识;摘要,即总结基于当前推理轨迹检索到的子图中的相关知识。
生成器
生成器旨在根据查询和检索到的信息为特定任务生成所需的输出。这些任务的范围可以从判别任务(例如,节点/边/图分类)到生成任务(例如,基于知识图谱的问答)和图生成(例如,分子生成)。由于不同任务的独特性,通常需要不同的生成器。我们将生成器分为三大类:基于判别的生成器,它利用GNN和Graph Transformer等模型来执行分类等任务;基于大语言模型的生成器,它利用大语言模型的能力来生成基于文本的任务答案;以及基于图的生成器,它使用扩散模型等生成模型来生成新的图。接下来,我们将详细说明这些生成器。
基于判别的生成器
基于判别(Discrimination-based)的生成器专注于判别和回归(regression)任务,这些任务通常可以建模为图任务,例如节点、边或图的分类和回归。为图数据设计的模型,例如GNN和Graph Transformer,被广泛用作基于判别的生成器。GNN的选择取决于图的类型和任务。例如,GCN、GraphSAGE和GAT通常应用于同构图(homogeneous graphs),而RGCN和HAN等模型用于异构图(heterogeneous graphs,),HGNN和Hyper-Attention适用于超图(hypergraphs)。此外,Graph Transformer因其捕获全局依赖关系的能力而越来越受欢迎。根据任务的具体要求,也采用了不同的训练策略,例如(半)监督学习和图对比学习。
基于大语言模型的生成器
大语言模型(LLM)在理解和生成各种任务的自然语言方面展现出了显著的能力。然而,LLM本身设计用于处理顺序数据,而GraphRAG中检索到的信息通常以图形的形式结构化。虽然各种GraphRAG组织者,例如语言化方法,可以将检索到的图形信息转换为文本,但这些转换可能会导致重要的图形结构信息丢失,这对于某些任务至关重要。为了利用LLM的能力,许多研究工作都致力于将图形信息输入到LLM中,我们将这些方法总结为以下几类:
- 语言化:语言化的目标是将GraphRAG中检索到的信息转换为LLM可以处理的序列。这些方法在第 2.5.4 节中详细介绍。
- 嵌入融合:嵌入融合将图嵌入和文本嵌入集成到LLM中。图嵌入可以使用GNN或Graph Transformer获得。为了使图嵌入与文本嵌入对齐,通常会学习一个领域投影器(domain projector)来将图嵌入映射到文本嵌入空间。 嵌入融合可以发生在LLM的不同层。例如,He等人将投影后的图嵌入通过LLM的自注意力层,而Tian等人将投影后的图嵌入与文本符元预先连接。在LLM的预测层之前融合文本和投影后的图嵌入。此外,LLM可以与领域投影器一起使用LoRA等方法进行微调,或者LLM可以保持不变,只训练图嵌入模型和领域投影器。
- 位置嵌入融合:通过语言化直接将图形转换为序列可能会丢失图形结构信息,这在某些任务中可能至关重要。位置嵌入融合旨在将检索到的图中节点的位置添加到大型语言模型(LLM)中。GIMLET作为一种统一的图文模型,采用广义位置嵌入来编码图结构和文本指令作为统一的符元。LINKGPT利用LPFormer中的成对编码来编码两个节点之间的成对信息。
基于图的生成器
在科学图领域,由于需要精确的结构生成,基于图的RAG生成器往往超越了基于大型语言模型的方法。RetMol尤其通用,因为它可以与各种编码器和解码器架构一起工作,支持多种生成模型和分子表示。例如,生成器可以基于Transformer或利用图变分自编码器(Graph VAE)架构。Huang等人强调了扩散模型的使用,特别是3D分子扩散模型IRDIF。在生成过程中,通过等变图神经网络(EGNN)等架构实现SE(3)等变性,这确保了分子结构的几何特性在每次旋转、平移和反射等空间变换下保持不变。将SE(3)等变性融入扩散模型保证了生成的分子结构在这些变换下保持几何一致性。对于知识图谱 (KG),多项工作使用图神经网络(GNN)来生成答案。这些作品中使用的GNN以查询为条件,从而使最终预测与其相关。
图数据源
论文对GraphRAG中最初四个模型中心组件(即查询处理器、检索器、组织器和生成器)中应用的主要技术进行了全面回顾。然而,即使这些组件具有最佳配置,如果GraphRAG系统的基础图数据源(从中检索外部知识)没有经过仔细整理,系统仍可能达不到最佳性能。这也强调了人工智能研究最近从模型中心转向数据中心的重大转变,其中提高数据质量和相关性对于取得优异成果同样重要,甚至更为重要。采用这种以数据为中心的视角,下一节将从高级角度概述现有的 GraphRAG 在构建图数据源方面的研究,并将对特定领域图构建方法的详细讨论留给随后的特定领域章节。
- 显式构建:显式构建是指基于数据中显式且预定义的关系构建图。此方法广泛应用于各个领域。例如,分子图是根据原子之间的连接构建的;知识图是基于实体之间的显式关系形成的;引用图是通过引用关系链接论文构建的;推荐图则模拟用户和项目之间的交互。
- 隐式构建:当节点之间没有显式关系,而是可以推导出隐式连接时,可以使用隐式构建。例如,文档中的词语共现可以暗示共享的语义信息,而表格数据中的特征交互可以表明特征之间的相关性。图可以显式地模拟这些连接,这可能对下游任务有利。
图构建完成后,还有几种方法可以正式表示图。
- 邻接矩阵:邻接矩阵是表示图最常用的方法之一。 具体来说,邻接矩阵A\in\mathbb{R}^{|v|×|v|}表示v中节点之间的图连接,其中|v|是节点数。
- 边列表:边列表表示图中的每条边,通常以元组或三元组的形式出现,例如(i,j)或(i,r,j),其中i和j是节点,r是节点i和j之间的关系。
- 邻接表:邻接表是一种以节点为中心的表示方法,其中每个节点都与其邻居列表相关联。它通常表示为一个字典{i:\mathcal{N}_i},其中{\mathcal{N}_i}是节点i的邻居列表。
- 节点序列:节点序列以不可逆或可逆的方式将图转换为节点序列。大多数序列化方法是不可逆的,不允许完全恢复原始图结构。例如,也有一些可逆的序列化方法可以恢复整个图结构。例如,Zhao等人提出通过首先对图应用欧拉化来使用欧拉路径序列化图。此外,如果图建立了树状结构,BFS/DFS也可以以可逆的方式序列化图。
- 自然语言:随着LLM在处理基于文本的信息方面越来越流行,已经开发出各种方法来使用自然语言描述图。
请注意,上述数据结构只能表示基本的图,不支持多关系边或边属性等复杂场景。 例如,使用邻接矩阵表示多关系属性图需要扩展结构:A\in\mathbb{R}^{|v|×|v|×|\mathcal{R}|},其中\mathcal{R}表示可能的各种关系的集合。 这里,A_{i,j,r}表示在关系r下连接节点i和节点j的边的权重。
选择合适的图表示对于特定任务的需求至关重要。 例如,Ge等人发现图描述的顺序会显著影响LLM对图结构的理解及其在不同任务中的性能。
知识图谱
知识图谱是一个结构化数据库,它通过定义良好的关系连接实体。它可以包含广泛的通用知识,例如广为人知的谷歌知识图谱,也可以深入研究专业领域,例如用于生物医学推理的BioASQ数据集。知识图谱中包含的各种信息——表示为实体、关系、路径和子图——是增强不同行业各种下游任务的宝贵资源,包括问答、常识推理、事实核查、推荐系统、药物发现、医疗保健和欺诈检测。
应用任务
本节回顾了GraphRAG在知识图谱上的代表性应用。
- 问答:问答(QA)可以专注于单个领域或跨越全局知识。通常,会给出文本格式的查询,例如“预测婴儿眼睛颜色的最佳方法是什么?”或“人类进化时地下是否有化石燃料?”——答案可以是大语言模型(LLM)生成的句子,从相关文档中选择的文本片段,甚至是在多项选择QA场景中的特定选择。 在所有这些情况下,GraphRAG都利用知识图谱检索相关信息,提供生成准确答案所需的上下文或支持事实。
- 事实核查:事实核查是通过与可靠的信息来源交叉引用来验证陈述的真实性。GraphRAG通过查询知识图谱来检索支持或反驳给定声明的相关事实和关系结构,从而增强此任务。GraphRAG通过将陈述映射到知识图谱来识别数据中的差异或确认,从而提供一个彻底且基于证据的验证过程。
- 知识图谱补全:知识图谱补全的任务是预测新的事实以增强图的全面性并推断缺失的事实。GraphRAG通过检索围绕三元组的结构知识进行推理,提供必要的结构知识,并增强LLM推理来解决此任务。
- 网络安全分析与防御:网络安全分析与防御旨在分析和响应漏洞、弱点、攻击模式和威胁策略。随着网络安全数据复杂性和数量的增加,已经提出GraphRAG为网络安全分析提供对潜在攻击向量和缓解策略的更全面见解。
知识图谱构建
我们讨论了知识图谱(KGs)的典型构建方式。对于每种构建技术,我们都提供了常用知识图谱数据库的示例。知识图谱的构建方式非常重要,因为它会影响其在不同下游任务中的效用和功能。 我们在下面描述了主要技术:
- 人工构建:一些知识图谱是通过人工标注手动构建的。维基数据是一个利用众包努力收集各种知识的知识图谱。 每个实体对应于维基百科百科全书中的一个页面。另一个知识图谱,统一医学语言系统(UMLS),包含从众多来源收集的生物医学事实。
- 基于规则的构建:许多传统方法使用基于规则的技术来构建图。这采取自定义解析器和手动定义的规则的形式,用于从原始文本中提取事实。请注意,这些解析器可能因文本来源而异。突出的例子包括ConceptNet,它通过断言将不同的单词连接在一起,以及包含各种一般事实的Freebase。 REANO分别使用传统的实体识别(ER)和关系提取(RE)方法从一组段落中提取实体和关系。这包括用于ER的SpaCy和用于RE的TAGME。为了提取通过关系连接两个实体的事实,他们使用DocuNet。
- 基于大语言模型的构建:最近,一些工作探索了如何使用大语言模型(LLM)从一组文档中构建知识图谱。通过这种方式,大语言模型(LLM)可以自动提取实体和关系,并将它们连接起来,在给定文本中形成事实。需要注意的是,这些方法不存在真实存在的知识图谱(KG)。相反,它们只是使用知识图谱作为组织和表示一组文档的方式。例如,CuriousLLM[485]将文本中的段落视为实体,并根据其编码的文本相似性确定两个实体是否应该连接。另一方面,Cheng 等人使用手动定义的提示将一段文本转换为知识图谱。Graph-RAG首先将每个文档划分为块,然后使用大语言模型(LLM)检测每个块中的所有实体,包括它们的名称、类型和描述。为了识别任何两个实体之间的关系,将两个实体及其关系描述传递给大语言模型(LLM)。然后再次使用大语言模型(LLM)总结每个实体和关系的内容,以得出它们的最终标题。最后,AutoKG使用大语言模型(LLM)嵌入和聚类技术的组合,从一组文本中构建知识图谱。
检索器
知识图谱中的真实世界事实可以为生成模型提供可靠的信息,从而提高模型输出的可靠性。鉴于知识图谱的结构化性质,它们自然非常适合检索。目标是对于给定的问题或查询,检索相关的知识或有助于回答该问题的实体。在检索过程中需要考虑多个因素,包括我们想要检索的事实类型、效率和检索的事实数量。一般来说,知识图谱的检索有两个阶段:识别种子实体和检索事实或实体。我们将在下面描述这两个阶段。
- 识别种子实体:获取给定查询相关事实的第一步是识别一组“种子实体”,我们将其称为V_{seed}。 种子实体是最初选择的与原始查询高度相关的实体。鉴于此,我们期望包含任何这些实体或在图中附近的三元组应该提供有用的上下文。现在已经存在多种识别种子实体的技术。一些工作假设我们为每个查询提供了一组初始实体。大多数工作尝试从查询中提取实体。一种方法是通过实体提取,它使用专门为从给定文本中提取实体而设计的方法。大多数工作只从原始查询中提取实体。另一种常见的方法是从语义上与原始查询相似的实体集中提取实体。HyKGE首先生成一个假设,并从原始查询和假设中提取实体。同样,为了减少幻觉的可能性,Guo等人使用LLM生成两个类似的问题,并检索在原始问题和生成的问题中找到的所有实体。同样,RoK首先使用思维链推理来扩展原始查询,从扩展的查询中提取种子实体。
- 检索方法:上一步的结果为我们提供了一组与查询在某种程度上相关的实体。然后利用这些实体来检索一组可以帮助我们回答查询的事实或实体。我们总结了下面的核心检索方法。
- 基于遍历的检索器:这些方法遍历图并提取路径以帮助回答特定问题。 给定种子实体集V_{seed},Yasunaga等人,Zhang等人提取V_{seed}中实体之间长度不超过二的所有路径,得到最终实体集V。他们进一步通过包含连接V中任意两个实体的所有三元组来扩充V。给定V,论文都只保留根据相关性评分排名前k的实体。 这是通过训练一个单独的模型计算得出的,该模型以查询和实体的文本嵌入作为输入,并输出实体与查询的相关性程度。对于Yasunaga等人,如果|V|>200,他们会随机抽取200个实体。 Sun等人使用一种束搜索的变体来探索知识图谱。 Jiang等人,Feng等人提取种子实体之间长度为k≤2的所有路径。此外,LARK检索所有位于从种子实体开始长度为≤k的路径上的事实。Delile等人首先提取连接所有种子实体的最短路径。他们通过考虑其关联文本的新近性、重要性和与查询的相关性,进一步优先考虑某些实体。OREOLM从种子实体遍历k跳,通过可学习的d维嵌入及其LM编码表示来表达每种关系和实体对路径的重要性。Zhang等人引入了一个可训练的检索器,该检索器从每个种子实体开始遍历图。他们还训练了一个模型来对每个新访问的边进行评分,只保留其中一部分。KG-RAG的工作方式类似,通过密集检索器根据其相关性和与查询的相似性对每条边进行评分。然后,他们使用大型语言模型来决定下一步探索哪些路径。RoG使用指令调优来微调大型语言模型以生成有用的关系路径,这些路径可以从知识图谱中检索。 KnowledgeNavigator首先使用查询来预测在检索阶段所需的预期跳数h_{Q}。然后,它从种子实体开始遍历h_{Q}跳,使用大型语言模型来评分和修剪不相关的节点。Wu等人的方法与此类似;然而,他们选择遍历的路径完全基于关系。此外,在对路径进行评分时,计算分数时会考虑该路径上所有关系。RoK采用了一种不同的方法,使用个性化ageRank(PPR) 分数来识别有用的路径。 他们通过包含种子实体的 1 跳邻居进一步增强这些路径。 PullNet [379] 假设每个实体都有一组相关的文档。 给定单个种子实体,PullNet 遍历 k 跳,其中在每次迭代中它都会提取新观察到的实体的事实。 它还会提取包含在与遍历中发现的实体关联的文档中的任何实体。 此外,对于每个实体,仅使用排名前 N 的事实,这些事实是通过与查询的相似性进行排序的。 KG-R3 [311] 使用 MINERVA [74](一种强化学习方法,用于挖掘实体之间的路径)来检索事实中两个实体之间的一组重要路径。 Wang 等人 [427] 使用大型语言模型 (LLM) 从种子实体开始遍历图。 在遍历的每次迭代中,我们通过提示大型语言模型来选择下一个要访问的节点。 具体来说,鉴于在遍历中已经收集到的信息,LLM 会被提示生成正确回答问题所需的剩余信息。 最符合所需信息的相邻节点将被选为下一个要访问的节点。 他们进一步对大型语言模型进行了指令调优。
- 基于子图的检索器:这些方法提取每个种子实体周围大小为k的子图。包含种子实体之一或附近的事实应该与回答问题高度相关。此外,它们实际上可能包含答案本身。每个都提取每个种子实体周围的一跳或两跳子图。最终的事实集是每个单独子图的并集。Gao等人提出首先使用Sun等人中的方法提取包含种子实体和潜在答案的子图。 然后将其划分为一组较小的子图。然后,他们设计了一个框架来对子图进行排序,保留前k个子图用于生成。对于一个问题-选择对,MVP-Tuning考虑包含最多种子实体和选择实体的三元组。他们通过使用BM25提取数据集中前k个最相似的问题,并提取每个问题的三元组来进一步增强这一点。
- 基于规则的检索器:这些方法使用预定义的规则或模板从图中提取路径。GenTKG考虑了一个时间KG,其中他们首先从KG中提取逻辑规则,并使用前k条规则在给定的时间间隔内提取种子实体的路径。两者都使用SPARQL生成查询,然后用于检索导入路径。KEQING使用通过LoRA微调的LLM将原始查询分解为k个子查询。对于每个子查询,他们找到最相似的预定义问题模板。对于每个模板,他们进一步预定义一组逻辑链,然后用于从KG中提取子查询中种子实体的匹配路径。
- 基于GNN的检索器:GNN-RAG训练一个用于检索任务的GNN。 对于每个查询q,都会进行一轮单独的消息传递,这与关系和实体表示一起被纳入消息计算中。然后,像节点分类任务中那样训练GNN,其中q的正确答案实体的标签为1,否则为0。 在推理过程中,概率高于某个阈值的实体被视为候选答案,并提取从种子实体到候选答案的最短路径。Liu等人使用条件GNN进行检索,其中对于每个查询,只有种子实体(他们假设只有一个)基于LLM编码的查询初始化为非零表示。然后他们运行L轮消息传递,其中在每一层l之后,只保留前K条新边,从而得到一组实体C^{l}_{q}。 这由一个可学习的注意力权重决定,该权重修剪图中的其他边。最终的候选实体集是每一层l,C_{q}=\cup^{L}_{l=1}C^{l}_{q}中候选实体的并集。它的优化方式类似于某论文。对于每个候选实体,他们通过回溯从实体到种子实体来检索证据链,选择具有最高注意力权重的那些边。REANO通过文本中该实体/关系所有提及的平均池化表示(由T5编码)来初始化实体和关系表示。然后他们运行一个GNN,其中包括一个注意力权重,该权重考虑给定三元组与原始问题(也由T5编码)的相关性。运行GNN后,他们检索知识图谱中与问题最相关的top K个三元组,其中相关性通过GNN编码的三元组与问题的点积来定义。
- 基于相似性的检索器:STaRK考虑查询与每个实体的向量相似性。每个实体都同时嵌入文本和关系信息。他们进一步考虑多向量相似性,其中实体使用多个向量进行编码。 这是通过将每个实体的文本和关系信息进行分块来实现的,每个块都被嵌入到它自己的向量中。REALM和EMERGE都提取与查询最相似的实体。EALM仅检索实体本身,而EMERGE进一步检索每个实体周围的1跳子图。
- 基于关系的检索器:Kim等人提出了一种使用LLM在知识图谱上进行推理的通用框架。他们首先使用LLM将原始查询分割成一组i\inI子句,其中每个子句S_i都与一组实体\mathcal{E}_i相关联。对于每个子句,他们进一步使用LLM检索前k个最相关的关系\mathcal{R}_{i,k}。给定k关系集,对于每个子句,他们检索所有包含\mathcal{R}_{i,k}中关系且实体在\cup_{i\inI}S_i中的三元组。GenTKGQA专注于时间知识图谱问答。与某论文一样,它们检索查询的top-k关系。然后,他们检索包含前k个关系之一并满足时间约束的所有事实。
- 基于融合的检索器:这些技术考虑了不同检索技术的组合。Mindmap考虑从种子实体提取一些≤k跳路径以及每个种子的1跳子图,并将这两个提取的组件组合成一个子图。DALK使用与Mindmap类似的过程,其中他们提取路径以及每个种子实体周围的1跳子图。但是,他们认为此过程通常会导致检索到冗余或不必要的信息。为了去除这些事实,他们使用LLM根据原始问题和子图对检索到的事实进行排序,只保留前k个最相关的结果。UniOQA考虑了两个检索分支:第一个是翻译器,它是一个经过微调的大语言模型(LLM),用于生成CQL格式的答案;第二个是搜索器,它检索种子实体周围的1-hop子图。在确定答案时,翻译器的答案优先于搜索器的答案。KG-Rank通过关系与查询的相似性、每个三元组与a=LLM(q)编码输出的相似性以及使用相似度分数的MMR排名来考虑对种子实体的1-hop邻域中的所有三元组进行排名,只保留排名靠前的三元组。GrapeQA通过进一步包含一组“额外节点”来扩展。这些节点是通过基于路径的检索器检索到的实体的公共邻居。他们进一步引入了一种基于聚类的方法来修剪可能与查询无关的实体。SubgraphRAG同时考虑了GNN和文本信息。对于GNN,他们考虑使用独热编码初始化节点表示,以区分种子实体和其他实体。然后运行GNN L层,从而得到节点v的最终表示s_v。为了检索相关的三元组,他们首先考虑连接每个三元组(h,r,t)的最终节点表示,使得z_{\tau}=[s_h,s_t]。然后,选择此三元组的概率由p(h,r,t)=MLP(z_q,z_h,z_r,z_t,z_{\tau})给出,其中z_q,z_h,z_r,z_t分别是查询和三元组(h,r,t)的编码文本表示。 只选择前K 个三元组。
- 基于Agent的检索器:这些技术使用LLM代理从知识图谱(KG)中检索事实。KnowledGPT定义了一组用于在知识图谱上搜索的工具。给定一个查询,他们会生成一段代码来搜索知识图谱,其中考虑了种子实体。然后在知识图谱上执行这段代码以找到正确的答案。KG-Agent专注于微调一个大语言模型(LLM)以生成用于检索正确答案的SQL代码。他们使用一组工具提取包含种子实体的一组路径。KnowAgent首先通过规划模块识别查询的相关操作。然后,他们使用这些操作生成一组用于生成的路径。
- 其他检索器:KICGPT关注知识图谱补全的任务,其中,给定一个部分事实(h,r,*),我们想要预测正确的实体\hat{e}。 KICGPT首先使用传统的KG嵌入评分函数对所有可能的实体进行评分,从而检索这些实体。 也就是说,对于一个评分函数f(·)和一个部分事实(h,r,*),他们计算一组分数{f(h,r,e)∀e\inV}。他们使用RotatE作为函数f(·),这是一种流行的方法。 仅检索得分最高的k个实体。为了补充他们的知识,他们还检索所有具有以下特征的三元组:(a)与查询具有相同的关联;(b)包含查询中实体h的所有三元组。这些分别被称为类似三元组池和补充三元组池。
组织者
本小节描述了如何组织检索到的知识以进行生成。更具体地说,这是在提供给生成器时信息的格式。请注意,并非每种方法都一定有明确的组织者。论文总结以下常用方法:
- 基于元组的组织者:这些方法将每条检索到的信息视为一个有序三元组。例如,它会在生成提示中包含一个三元组,例如“(entity1,relation1,entity2)”。同样,长度为m的路径由“(entity1,relation1,entity2,relation2,⋯,entity m)”给出。实体和关系通常以其名称或ID表示。每个三元组或路径通常单独列在一行。许多工作将检索到的路径附加到原始查询中作为附加上下文。其他检索事实而不是路径的工作以类似的方式运行,其中它们附加三元组。 一些方法仅考虑将检索到的实体作为上下文。给定一组事实,KG-R3首先列出所有实体,然后列出关系,即“(entity1,entity2,⋯,entitym,…,relation1,⋯,relation m-1)”。Delile等人考虑了一个知识图谱,其中每个实体都有一个相关的文本块。每个实体的文本块都被视为要包含在上下文中的不同信息。两者都将每个实体和关系表示为嵌入,它是LLM和GNN嵌入的组合。Liu等人进一步包含了GNN模型给出的每条路径包含正确答案的概率。MVP-Tuning考虑组合具有相同主体和关系的多个事实以去除冗余信息。也就是说,对于一个实体-关系对(subject,relation),他们将k个可能对象的论据表示为“subject relation {object1,⋯,objectk}”。KG-Agent将当前的知识图谱信息和历史推理程序存储在列表中。
- 文本组织器: Wu等人通过将每个三元组传递给大语言模型(LLM)并提示其将其转换为文本表示来对检索到的子图进行描述。MindMap Wen等人对子图使用了类似的过程,其中每个子图在传递给LLM之前都被组织成一条路径。一些方法使用一组预定义的模板来描述三元组或路径。Wang等人尝试通过LLM或预定义的问题模板进行描述,发现基于LLM的描述对于ChatGPT效果更好,而基于模板的描述对于LLaMA效果更好 。KICGPT使用数据预处理和LLM提示的组合将三元组转换为文本。StaRK使用LLM来合成每个实体及其关系和文本信息。注意,他们使用一些取决于特定任务的预定义模板。CoTKR使用LLM来总结然后通过“知识重写器(knowledge rewriter)”重写问题的子图事实。为了训练重写器,使用了偏好对齐(preference alignment),它优化了重写器的输出以匹配我们首选的输出。 首先,k生成检索到的子图的表示,ChatGPT选择最佳和最差的表示作为最优和最劣解。
- 其他组织器:之前分类有一些例外情况。KnowledGPT以Python类的形式表示信息。他们还尝试包含其他信息,例如实体描述和实体方面信息。
- 重新排序:一些方法也会重新排序信息的特定顺序。这是因为信息的顺序会对LLM的性能产生细微的影响。Delile等人根据影响(以父论文的引用次数衡量)和近期性对每个实体的文本块进行排序。Dai等人根据与三元组的相关性评分对三元组进行排序。Choudhary和Reddy尝试以逻辑的方式对路径进行排序,以便对于给定的路径,后续路径在其基础上构建。Yang等人使用特定任务的交叉编码器重新排序检索到的三元组。STaRK考虑使用大语言模型(LLM)重新排序检索到的实体。大语言模型(LLM)被赋予每个实体的关系和文本信息,并被要求给出0到1之间的分数,然后用于重新排序。GenTKG按路径发生的时间顺序对路径进行排序,并进一步包含每个路径的时间信息。KICGPT使用KG嵌入评分函数的分数对所有实体进行排名,只保留前k个实体。KICGPT使用上下文学习重新排序实体,其中他们提示大语言模型(LLM)使用来自类比和补充池的示例作为先验知识,以帮助大语言模型(LLM)如何重新排序实体。其中,他们使用来自类比和补充池的例子作为先验知识来辅助LLM对实体进行重新排序。
生成器
在本节中,我们将描述如何使用检索和组织的数据来生成对查询的最终响应。我们根据用于创建这些响应的方法类型对这些生成器进行分类。
- 基于LLM的生成器:绝大多数论文都使用LLM来生成响应。LLM的输入是原始查询以及检索和组织的上下文,使用特定的模板进行格式化。最常用的LLM包括ChatGPT、Gemini、Mistral、Gemma等。对于权重公开的开源模型,有时会使用微调来修改特定任务的权重。这通常是通过LoRA完成的,它允许进行高效的微调。
- 基于图神经网络的生成器:一些方法使用图神经网络(GNN)来进行生成。Yasunaga等人,Taunk等人,Feng等人提取每个潜在答案(即实体)在查询条件下的语言和GNN嵌入。然后,基于两种嵌入的融合来学习单个实体作为答案的概率。
- 其他生成器:Zhang等人,Yasunaga等人,Hu等人将预测公式化为掩码语言建模(MLM)问题。目标是预测回答查询的掩码符元(即实体)的正确值。为此,他们微调了RoBERTa语言模型。KG-R3通过对查询和每个单独实体的表示进行交叉注意力来对潜在答案实体进行评分。PullNet使用GraftNet来对不同的实体进行评分。Gao等人首先通过计算查询和子图表示之间的余弦相似度来选择正确的子图。对于相似度最高的子图,将其馈送到GraftNet以选择最可能的实体。REANO将编码的三元组及其相关的文本片段传递给T5解码器。该任务被构建为一个分类问题,目标是为具有正确答案的三元组分配最高的概率。
资源和工具
在本节中,我们列出了图RAG系统中常用的工具和知识图谱。 对于每一个,我们都会给出简短的描述和项目链接。
数据资源
- Freebase是一个包含大量一般性和基本事实的百科全书式知识图谱(KG)。
- ConceptNet是一个语义图,其中图中的链接用于描述不同单词或概念的含义。
- WikiData是一个众包知识库,充当维基百科百科全书的结构化类似物。
工具
- Graph RAG是Graph RAG框架的官方开源实现。它可以通过graphrag python包进一步安装。
- LangChain是一个用于将大型语言模型(LLM)与各种组件和应用程序(包括RAG)一起使用的开源框架,其中在KG上使用RAG是有帮助的。
文档图
文档图通常对不同文档或不同粒度的文档之间的连接进行建模。在现实世界中,这种现象很常见,例如连接不同网站的超链接以及将一篇论文链接到另一篇论文的引用。此外,文档图中句子和实体之间的关系可以明确地捕捉语义和句法上下文信息。文档中的结构信息可以作为GraphRAG的宝贵资源,帮助大型语言模型(LLM)完成各种任务。例如,在RAG的检索过程中,包含答案的文档可能与问题之间的联系不太明显,例如在多跳问答中。但是,我们可以通过它们与其他文档(其上下文与问题的上下文高度一致)的连接来识别这些相关文档。在本节中,我们将系统地回顾文档图。
应用任务
文档图谱有利于进行通用的任务。在本小节中,我们将回顾文档图谱可以发挥重要作用的任务。尽管文档图谱尚未完全集成到大型语言模型 (LLM) 中,但它们仍然为增强LLM在各种应用中的能力提供了巨大的潜力。
- 多文档摘要(MDS):多文档摘要旨在将多个文档的内容浓缩成一个连贯的摘要。总结整个语料库可能涉及大量的文本,通常超过LLM的上下文窗口限制。文档图谱可以通过提取关键组件及其关系来帮助压缩语料库,这对于MDS非常有益。 这些图谱还通过分层聚类为摘要提供了不同粒度的信息。
- 文本生成:文本生成专注于生成连贯且有意义的文本。虽然基于文本的检索增强生成模型(RAG)已被广泛用于生成更可靠的文本,但文档图谱可以通过利用图拓扑检索类似文档来进一步增强此过程。例如,在撰写论文摘要时,访问相关工作部分中引用的论文可以显著提高写作效率,因为这些参考文献通常包含相关的知识和上下文。
- 文档检索:文档检索旨在查找与给定查询相关的文档列表,这是信息检索(IR)中的一项关键任务。精确的查询词并不总是同时出现在候选文档中;但是,通过利用文档之间的连接,我们可以通过那些与查询强烈关联的文档来检索相关文档。因此,在检索过程中考虑文档级关系至关重要。一些研究利用具有各种粒度的文档图谱来改进文档检索和排序。图谱不仅可以检索整个文档,还可以用于检索特定段落,例如文本块。
- 文档分类:文档分类是自然语言处理中的一项基本任务。传统方法通常侧重于词语的局部性,限制了其捕获长距离和非连续词语交互的能力。此外,这些方法通常关注单个文档,忽略了它们之间的关系,其中关联文档通常表现出同质性,这意味着它们更有可能共享相似的标签。通过利用单个文档内词语的局部和全局关系,以及利用文档级关系,构建图可以帮助增强文档分类。
- 问答:问答旨在根据文档中的信息提供问题的答案,是RAG的一项基本任务。然而,用于问答的文档可能很长,传统方法通常关注这些文档中的局部结构,而忽略了其全局结构,而全局结构对于长程理解至关重要。此外,一些多跳问题需要跨多个文档进行推理,因此需要使用文档级关系。人们通常会将分散的信息整合到结构化的知识中,以简化推理过程并做出更准确的判断,这与认知负荷理论相符。基于图的方法非常适合这项任务,它可以构建词级文档图,利用文档级关系并利用层次交互。
- 关系抽取:关系抽取旨在提取文本中实体之间的语义关系,这通常需要局部(local)、全局(global)、句法(syntactic)和语义依赖关系(semantic dependencies),尤其是在文档级关系抽取的情况下。事实证明,图对于文档级关系抽取很有帮助,因为它可以更有效地捕获这些依赖关系。
除了上述任务之外,图在其他领域也已被证明是有帮助的,例如假新闻检测、连贯性评估和机器翻译。
文档图构建
不同的任务可能需要不同类型的文档图,例如文档级(document-level)、句子级(sentence-level)或词级(word-level)图。因此,获取文档图的方法起着至关重要的作用。 构建文档图主要有两种方法:显式(explicit)构建和隐式(implicit)构建。
- 显式构建:在现实场景中,许多文档具有显式连接。 例如,通过超链接连接的网页,引用其他作品的学术论文,以及通过转发、评论和互动连接的社交媒体帖子。在这些情况下,连接文档以构建文档图是很自然的,因为连接的文档通常共享语义关系。例如,Asai等人基于维基百科文章之间的超链接构建了一个维基百科图。Li等人也采用同样的方法利用超链接构建图。Yu等人使用外部知识图谱(KG)构建了一个图,其中每个节点代表一个映射到KG中实体的检索到的片段,如果它们的映射实体在KG中链接,则两个片段节点连接。这些连接已被用来预训练大型语言模型(LLM),从而提高其在各种任务中的性能。
- 隐式构建。尽管文档之间存在显式连接,但这些文档中的不同组件也表现出重要的语义和句法关系。这些组件的结构对于自然语言处理中的各种任务非常有益。例如,语义解析图,例如抽象意义表示(AMR)图,可以用来增强信息提取和文本摘要。此外,句法分析树被用来理解语法结构和解决歧义。文档图的隐式构建高度多样化,适应不同任务的具体要求。例如,文档图中的节点可以表示不同的粒度,例如单词、实体、句子、文本片段、段落、文档或主题。此外,文档图通常表现出异质性,其中边连接不同类型的节点。接下来,详细介绍不同类型边的构建:
- 词-词边(Word-word edge):词-词边连接具有语义或句法关系或依赖关系的词。建立这些连接的方法有多种,包括滑动窗口内的单词共现,由NLP解析工具生成依存解析图、抽象意义表示以及基于不同表示的语义图。 其他技术包括共指消解(coreference resolution)、词嵌入相似度以及使用大型语言模型 (LLM) 来提取词语之间的关系。对于实体,构建过程与词语类似,尽管通常需要实体提取方法来首先识别实体。
- 词-句边(Word-Sentence edge):词-句边根据所属关系将词与句连接起来。这些边是通过将词与它们所在的句子连接起来构建的,边权重通常使用词频-逆文档频率 (TF-IDF) 来衡量。此外,Ramesh等人通过超链接和现有的开箱即用实体链接器将实体与段落标题连接起来。
- 句-句边(Sentence-Sentence edge): 句-句边根据语义相似性或关系连接句子。例如,这些边可以通过句子交互、TF-IDF表示之间的相似性、BM25、句子嵌入、词性 (Pos) 特征和N元语法特征来构建。此外,Zheng和Kordjamshidi使用AllenNLP-SRL模型构建了一个语义角色标注(SRL)图。这允许连接长文档内或不同文档中的句子,这对于上下文长度有限的LLM尤其有用。
- 句子-文档边(Sentence-document edge):句子-文档边通过将句子与其所属的特定文档连接起来而构建。
- 文档-文档边(Document-document edge):文档-文档边基于文档的相似性连接文档。当一个文档中的实体被另一个文档引用或共享,通过文档聚类、嵌入相似性、主题相似性或结构相似性时,可以构建这些边。
文档图通常表现出异质性,由多种类型的边组成。此外,已经提出了几种分层图,其中捕获了不同层次的抽象。图结构也可以在学习过程中动态变化或更新。此外,文档图中的节点也可以是大语言模型(LLM)的响应。例如,GoR将LLM的历史响应与文档的响应片段连接起来,用于长文本摘要。
检索器
文档图的检索器通常遵循第2.4节中描述的一般检索器设计。 然而,还有一些特殊的检索方法如下:
- 预检索:如前所述,在许多情况下,构建文档图是必要的。然而,为大量文档构建细粒度的图可能效率低下且不必要。预检索的目标是首先根据查询检索相关文档,然后构建图。例如,Thayaparan等人首先使用预训练的GloVe向量提取相关句子,然后基于检索到的句子构建图谱。Zheng和Kordjamshidi,Yu等人也基于检索到的信息构建图谱。
- 基于图相似性的检索器:图相似性旨在衡量两个图谱之间的相似度。如果查询和检索数据源都是图谱,则计算图相似性对于检索相关信息至关重要。例如,利用最大公共子图 (GMCS) 方法来检索相关的图谱。
- 迭代式检索器:在某些任务中,例如多步问答,包含答案的节点可能与查询并不直接相似。迭代式检索器通过首先检索与查询相关的节点,然后使用检索到的信息迭代地检索后续节点来解决这个问题。例如,Wang等人,Zhang等人将迭代检索方法用于多步问答任务,而Ma等人则基于现有的知识图谱迭代地检索文档。Asai等人训练了一个循环神经网络(RNN)来使用贝叶斯个性化排序(BPR)损失反复检索相关信息。
- 基于拓扑结构的检索器:图中各种拓扑关系可用于衡量不同类型的相似性。例如,基于邻近性的拓扑相似性测量两个节点之间的结构距离,而基于角色的拓扑相似性则评估节点在图谱中所扮演角色的相似性。这些相似性也可以在检索过程中得到利用。
组织者
本节将介绍文档图的组织者。应用于文档图的GraphRAG仍处于早期阶段,许多工作并未包含显式的组织者,如第2.5节所示。我们总结了现有的方法如下:
- 图剪枝:图剪枝细化检索到的子图以减少无关信息并提高计算效率。例如,Hemmati和Ghassem-Sani基于局部聚类系数进行图剪枝,而Zhang等人则采用以路径为中心的剪枝方法来整合路径外的信息。Li等人在解码过程中动态删除无关节点,而Angelova和Weikum则基于相似性阈值剪枝边。此外,Edge等人使用社区检测算法创建不同的社区,然后将其馈送到生成器中。
- 重新排序:重新排序方法旨在重新排序检索到的信息,以方便生成。例如,Yu等人、Zhang等人和Dong等人使用GNN重新排序检索到的段落。Li等人执行列表式重新排序以重新排序通过图结构扩展的段落。
生成器
本节总结了文档图中常用的生成器。根据输入格式的不同,文档图中应用了各种方法。一些方法使用整个图作为输入,在这种情况下,通常采用GNN和Graph Transformer。其他方法将单个句子作为输入,其中RNN或LLM模型适用。此外,一些工作利用图和文本作为输入,需要能够有效处理多模态数据的集成方法。我们将在下文中详细介绍每一类:
- 基于图神经网络(GNN)的生成器:许多工作将任务建模为与图相关的問題,利用GNN作为生成器。常用的GNN,例如GCN、GraphSAGE和GAT,已被广泛应用于各种研究中。 当图包含边关系时,关系图卷积网络(R-GCN)通常用于有效地捕获这些关系。此外,一些工作结合了图对比学习技术来提高性能。
- 基于Graph Transformer 的生成器:Graph Transformer捕获图中的全局信息,用于对各种任务的图结构进行编码。这些模型利用Transformer的自注意力机制来捕获超出局部邻域的依赖关系,使其非常适合需要全局上下文的任务。
- 基于循环神经网络(RNN)的生成器:循环神经网络(RNN),例如LSTM,常用于处理序列。因此,当输入为文本形式时,会采用RNN。
- 基于大语言模型 (LLM) 的生成器:基于LLM的生成器通常先将检索到的子图转换为文本,然后使用大型语言模型(LLM)进行生成。此方法中使用了各种模型。例如,应用 BERT来支持生成任务,而Yu等人和Ju等人利用T5模型,Chen等人使用RoBERTa。
- 集成生成器:一些工作同时利用图数据和文本数据进行生成,使用结合了图模型和文本生成模型的集成生成器。 例如,Xu等人和Wang等人使用RoBERTa和GCN的组合,而Ramesh等人将GNN与T5融合,以利用图结构和语言模型能力的优势。
除了上述生成器之外,一些方法将图直接嵌入到文本生成模型中。例如,Li等人提出用图信息自注意力替换Transformer中的传统自注意力层,使模型能够将图结构直接集成到生成过程中。
资源和工具
Document GraphRAG的数据资源可以包含任何类型的文档,因此,我们在这里不提供详尽的列表。相反,在下文中,我们将介绍一些专门设计或常用用于文档图上 GraphRAG 的工具:
- CoreNLP:斯坦福CoreNLP自然语言处理工具包提供了一套全面的自然语言处理工具,包括符元和句子边界、词性、命名实体、数值和时间值、依存和成分分析、共指消解、情感分析、引用属性和关系。这些工具对于构建文档图非常有价值。
- spaCy:spaCy是一个先进的自然语言处理库,以其速度和神经网络模型而闻名,这些模型针对诸如标注(tagging)、解析(parsing)、命名实体识别(named entity recognition)、文本分类(text classification)、词性标注(part-of-speech tagging)、依存句法分析(dependency parsing)、句子分割(sentence segmentation)、词形还原(lemmatization)、形态分析(morphological analysis)和实体链接(entity linking)等任务进行了优化。
- BLINK:BLINK是一个实体链接Python库,它使用维基百科作为目标知识库。
- OpenIE:开放信息抽取(OpenIE)是一种从文本中提取结构化信息的工具。它对于从非结构化文本生成三元组非常有价值,这些三元组可以用作文档图中的节点和边。
- CogComp NLP:这套工具由认知计算小组开发,其中包括用于命名实体识别、情感分析和共指消解等自然语言处理任务的工具。
- GraphRAG: GraphRAG是一个数据管道和转换套件,旨在利用大语言模型(LLM)的强大功能从非结构化文本中提取有意义的结构化数据。此过程涉及从原始文本中提取知识图谱(extracting a knowledge graph out of raw text),构建社区层次结构(building a community hierarchy),为这些社区生成摘要(generating summaries for these communities),然后在执行基于RAG的任务时利用这些结构。
- LangChain:LangChain是一个用于开发由大型语言模型(LLM)提供支持的应用程序的框架,其用例包括文档分析和摘要、RAG、聊天机器人和代码分析。值得注意的是,LangChain支持Graph Transformer,它可以将文档转换为图结构格式,使其非常适合处理文档图。
- Neo4j: Neo4j是一个图数据库平台,提供用于存储、可视化、管理和查询图数据的全面工具。它包含一个LLM图构建器,可以使用LLM提取图。它还提供GraphRAG演示,以展示如何使用Neo4j实现LLM和RAG系统。
- LlamaIndex:LlamaIndex是一个数据框架,旨在支持基于LLM的应用程序的开发。它允许开发人员将数据源(从各种文件格式到应用程序和数据库)与LLM无缝集成。 LlamaIndex具有高效的数据检索和查询接口,使开发人员能够输入任何LLM提示并接收上下文丰富、知识增强的输出。 值得注意的是,它包括一个属性图索引,可以促进图的构建、建模、存储和查询。
- Haystack:Haystack是一个端到端框架,用于构建由LLM、Transformer模型、向量搜索等驱动的应用程序。 它支持各种用例,包括RAG、文档搜索、问答和答案生成。 Haystack能够将最先进的嵌入模型和LLM编排到自定义管道中,以创建全面的NLP应用程序。此外,它支持Neo4j作为DocumentStore,使其适用于文档图的存储和查询操作。
科学图谱
科学图谱是指在药物发现和生物医学等领域使用的图结构数据,这两者都是GraphRAG常见的应用领域。因此,在本节中,科学图谱特指分子图谱和医学图谱。
近年来,科学人工智能的开发取得了显著进展。机器学习(ML)和深度神经网络技术正日益推动从实验数据中进行科学发现。值得注意的是,大型语言模型(LLM)等生成模型在处理科学图谱数据(包括分子图谱和生物医学图谱)方面取得了显著成功。例如,在分子图谱中,原子充当节点,而化学键代表边,捕捉分子的结构。AI技术可以处理这些图上的预测和生成任务,从而推动药物发现等领域的进步。
尽管像LLM这样的大型生成模型具有令人印象深刻的能力,但仍有一些挑战阻碍了它们在科学领域的应用。最突出的挑战之一是缺乏特定领域的专业知识。在药物发现等领域,分子生成至关重要,但传统的生成模型往往难以生成正确或科学有效的结构。在医学问答(QA)任务中,经常会遇到错误答案、幻觉和可解释性有限等问题。为了应对这些挑战,最近的一些工作提出了利用外部知识库通过GraphRAG来增强生成能力。GraphRAG通过从大量的数据库中检索相关的科学图谱来指导生成或回答过程,从而提高了准确性。通过结合已知的有效图结构,这种方法确保了科学有效性,利用现有知识用于实际应用,并通过缩小搜索空间来加速生成过程。
应用任务
科学图谱对各种任务都很有益。在本小节中,我们将回顾一些科学图谱可以发挥重要作用的代表性任务。
- 分子生成:分子生成是指创建或设计新的分子结构的过程,通常使用生成模型。它在药物发现等领域发挥着至关重要的作用。科学图谱,特别是分子图谱的使用,可以提高分子生成中生成的分子结构的合理性和准确性。通常,会给出一个类似分子的查询来检索最相关的分子结构,以指导分子生成。
- 分子性质预测:分子性质预测是指利用计算方法根据分子的结构来估计其物理、化学或生物性质。它已被证明在加速药物研发过程方面非常有效,同时显著降低了相关成本。使用科学图谱,特别是分子图谱,可以提高预测的准确性。为此,提供一个查询分子,并识别类似的分子作为示例来改进预测。
- 问答:科学领域的问答(QA)指的是利用计算方法为科学问题提供准确且特定于上下文的答案。这涉及从科学文献、数据库或其他资源检索或生成信息,以解决复杂、特定领域的查询,例如“饭后,我感觉有点胃酸反流,我应该服用什么药物?”在 graghRAG中,科学文献通常被转换成知识图谱,为回答问题或丰富查询提供依据。
科学图谱构建
在GraphRAG中,数据源的选择和构建至关重要,通常包括公共和私有数据集。公共数据集通常来自广泛认可的资源,例如 PubChem、ChEMBL和ZINC等分子数据库,以及PubMed和ClinicalTrials等生物医学文献和数据源。这些数据集提供了跨不同领域的广泛信息基础,为模型提供了可靠且权威的参考。另一方面,私有数据集包含用户特定信息,例如医院的医疗记录或机密的临床试验数据。这些数据集高度机密且具有唯一性,使GraphRAG模型能够提供个性化和专有的知识支持。
对于化学而言,分子可以用四种主要形式表示:一维SMILES(简化分子输入行输入系统)、二维分子图、具有坐标的三维分子图和描述分子结构的文本说明。1D SMILES是一种通过分子图上的深度优先搜索(DFS)生成的线性字符串,遵循特定的规则。2D分子图将原子表示为节点,将键表示为边,直观地显示原子的连接方式。3D分子图包含每个原子的空间坐标,反映了分子在三维空间中的结构,这对于分子对接和反应预测等任务至关重要。另一方面,文本描述提供了分子结构的自然语言描述,可用于处理涉及文本数据(从文本中解释化学结构)的任务。科学图通常可以按如下方式构建:
- 基于文本的构建:基于文本的图构建是最常用的方法,它可以将文本化的科学知识转化为知识图谱。Delile等人认为文本描述存在信息冗余和不平衡的问题。通过将文本构建为知识图谱,可以重新平衡可检索信息并减少冗余。构建知识图谱通常涉及两个关键步骤:
- 实体提取:此步骤涉及识别和提取文本中的关键实体,例如特定领域的术语(例如,化合物、基因)。
- 关系提取:识别实体后,下一步是提取这些实体之间的关系,确定它们在给定上下文中的关联方式(例如,“A与B相关”)。此步骤构成了知识图谱的结构主干。
- 基于SMILES的构建:许多化学数据库以SMILES等分析描述符格式存储数据。为了对图进行建模,需要将SMILES表示转换为图结构。基于SMILES的构建利用RDKit等库读取SMILES表示法,创建分子对象,并提取原子和键合信息以构建二维图。分子中的每个原子都被表示为一个节点,每个键都被表示为节点之间的边。原子带有原子类型、度数、电荷和芳香性等特征,而键可以包括键类型(单键、双键等)以及它们是否是环的一部分。
- 三维图构建:Huang等人介绍了IRDIFF,这是一种基于交互的、增强检索的三维分子扩散模型,旨在生成特定目标的分子。对于预训练,利用PMINet捕获具有结合亲和力信号的交互式结构上下文信息,利用PDBbind v2016数据集。此数据集提供了3D蛋白质结构和大量经过实验验证的蛋白质-配体复合物。这些蛋白质结构主要通过X射线晶体学、核磁共振(NMR)或冷冻电子显微镜等技术获得,包含详细的原子坐标、键角和二级结构信息。
检索器
检索器负责根据输入查询找到相关信息。在GraphRAG中,此信息通常由图结构数据组成。检索器大致可以分为基于启发式算法的检索器和基于深度学习的检索器。
- 基于启发式算法的检索器:基于启发式算法的检索器采用预定义的规则、算法和启发式方法来识别和检索来自图结构数据源的相关知识。 基于启发式算法的检索可以分为以下几种类型:
- 基于相似性的检索器:Wang等人使用余弦相似度作为度量标准,根据其与输入分子的相似性检索示例分子。MindMap使用BERT将查询和外部知识图谱中的实体编码成稠密嵌入,然后检索相似度得分最高的实体集。
- 基于匹配的检索器:基于匹配的方法提供了一种替代方法,使大语言模型能够通过利用全面的私有数据生成基于证据的响应。具体来说,Wu等人通过自上而下的匹配过程识别最相关的图。一旦识别出相关内容,大语言模型就会在其辅助下生成中间响应,从而提高结果的透明度和可解释性。
- 基于知识图谱的检索器:基于知识图谱的方法可以有效地识别和检索回答查询所需的信息。Pelletier等人,Li等人使用命名实体识别和关系抽取将用户查询与知识图谱中的相关实体连接起来,从而揭示现有生物医学知识中可解释和可操作的见解。此方法显著增强了预测模型的透明度和实用性。Delile等人将文本片段映射到知识图谱,然后利用图距离来查找与用户问题最相关的片段。此外,这项工作引入了一种评分指标,通过给沿着最短路径映射的每个概念提供平等的机会来平衡数据。此指标根据文本片段的近期性和影响力对其进行优先排序。HyKGE首先查询大语言模型以生成假设输出,并从输出和查询中提取实体。然后,HyKGE检索现有知识图谱(例如CMeKG和CPubMed-KG)中任意两个锚实体之间的推理链,并将推理链与查询一起馈送到大语言模型。KG-Rank识别查询中的实体,并从KG检索相关的三元组或子图以收集事实信息。
- 基于融合的检索器:Soman等人首先基于与查询实体的向量相似度,检索知识图谱中相关的节点。然后,它检索与知识图谱中该节点链接的上下文三元组(主体、谓词、宾语)。
- 基于深度学习的检索器:基于深度学习的检索器可以提取相关的知识来指导生成过程,例如分子或蛋白质的生成。 具体来说,Huang等人使用一个名为PMINet的预训练蛋白质-分子相互作用网络来提取目标蛋白质和参考库中配体之间的交互结构上下文信息,以指导目标感知配体的生成。Jeong等人利用现成的MedCPT检索器,这是一个专门用于检索响应生物医学查询的文档的工具,能够为每个输入检索多达十个相关的证据。DALK通过利用大型语言模型的排序能力,过滤掉噪声并检索最相关的知识。
组织者
基本上,根据检索到的知识的利用方式,组织者有两种类型:基于嵌入的和基于查询的组织者。
- 基于查询的组织者:最简单、最直接的组织者是基于查询的组织者,它将检索到的信息与输入查询相结合以生成响应。具体来说,HyKGE通过将外部知识整合到大型语言模型中来增强推理过程。在这个框架中,检索到的推理链与原始查询一起被送入大型语言模型。这使得模型能够将其响应建立在结构化、上下文相关的基础上,从而提高生成输出的准确性和深度。 Wu等人通过提供检索到的实体名称及其关系的串联形式来提示大型语言模型回答问题。这种方法包括从外部知识源检索相关的实体及其之间的关系,并将这些信息构造为大型语言模型的连贯输入。DALK集成查询并检索知识,然后将其输入到大型语言模型 (LLM) 中进行推理并获得预测答案。同样,KG-Rank 将重新排序的三元组与任务提示结合起来,并将它们输入到大型语言模型(LLM)中以生成答案。与上述方法相反,Soman等人从上下文剪枝开始。具体来说,这种方法通过仅选择对快速回答查询最相关的语义元素来细化检索到的上下文。然后将输入提示与这种上下文感知信息结合起来,生成一个丰富的提示,将其输入到大型语言模型 (LLM) 中进行文本生成。 Delile等人开发了一种数据再平衡机制,以确保与问题相关的每个实体都有平等的机会得到表示,同时突出最近的重要发现。然后将这种再平衡的知识与查询提示结合起来,并作为输入提供给大型语言模型(LLM)。
- 基于嵌入的组织器:基于嵌入的组织器将检索到的信息与输入嵌入集成在一起以生成响应。具体来说,Wang等人使用轻量级、可训练的标准交叉注意力机制来融合输入分子和检索到的示例分子的嵌入。同样,Huang等人使用可训练的交叉注意力机制来融合检索到的示例配体和生成的分子增强的嵌入。
生成器
生成器是GraphRAG模型的核心组件,负责通过将检索到的证据与输入数据集成来生成最终输出。根据生成器使用的模型类型,生成器可以大致分为三类:基于Transformer的生成器、基于扩散模型的生成器和基于大型语言模型的生成器。
- 基于Transformer的生成器:RetMol利用Megatron版本的分子生成模型Chemformer进行药物发现。特别地,Chemformer模型是一个基于Transformer的模型,可以有效地应用于化学领域的各种任务。
- 基于扩散的生成器:Huang等人提出了一种新颖的基于交互的检索增强扩散模型(IRDIFF),用于基于结构的药物设计。特别地,IRDIFF能够通过利用参考蛋白和目标蛋白之间的蛋白-分子相互作用数据来指导扩散模型,从而生成与目标口袋强烈结合的分子。
- 基于LLM的生成器:一些方法利用大型语言模型,例如LLaMA2、LLaMA3、GPT-4和Gemini等。例如MedGraphRAG利用GraphRAG来提高LLaMA2、LLaMA3、Gemini和GPT-4等模型在医学问答方面的回答能力。MolecularGPT利用GraphRAG来提高GPT-3预测分子性质的预测能力。DALK利用GraphRAG来增强GPT-3.5-turbo回答与阿尔茨海默病相关问题的能力。HyKGE利用GraphRAG来增强GPT-3.5和Baichuan13B的医学问答能力。
资源和工具
在本节中,我们将概述科学领域内图RAG系统中常用的数据源和工具,并简要介绍每个项目。
数据资源
公共数据集通常来自著名的资源,例如分子数据库:
- PubChem:PubChem包含广泛的化学数据,包括二维和三维结构、化学和物理性质、生物活性、药理学、毒理学、药物靶点、代谢、安全指南、相关专利和科学文献。其大多数条目都与小分子有关,主要侧重于包含少于100个原子和1000个键的分子。
- ChEMBL: 它是一个公开访问的数据库,包含关于药物、类似药物的小分子及其生物活性的详细信息。这个经过精心整理的资源以其对药物发现过程的全面覆盖而著称,包含超过 220 万种化合物的数据以及超过 1800 万条记录,记录了它们对生物系统的影响。ChEMBL提供了关于小分子与其蛋白质靶标之间相互作用的见解,以及关于这些化合物如何影响细胞和机体功能的数据。它还包括关于ADMET(吸收、分布、代谢、排泄和毒性)特征的信息。该数据库存储二维结构、计算出的分子特性(如 logP、分子量和 Lipinski 五规则参数)以及生物活性数据,如结合亲和力和药理作用。
- ZINC : ZINC数据集是经过精心整理的市售化合物的集合,专门用于虚拟筛选。它提供了超过2.3亿种可购买的3D格式化合物,可用于对接,以及超过7.5亿种可用于类似物搜索的化合物。每个分子都调整到生物学相关的质子化状态,并用分子量、计算LogP和可旋转键等属性进行标注。该库包含供应商和购买详细信息,使其与几种广泛使用的对接软件程序兼容。化合物在某些约束条件下以多种质子化状态和互变异构体形式提供,某些格式甚至每个分子提供多种构象。ZINC数据库可免费下载,并提供多种常用文件格式,包括SMILES、mol2、3D SDF和DOCK flexibase。
此外,还有以下生物医学数据源:
- PubMed:PubMed是一个免费访问的数据库,主要包含MEDLINE集合,其中包含生命科学和生物医学的参考文献和摘要。PubMed由美国国立卫生研究院(NIH)下属的美国国立医学图书馆(NLM)管理,是Entrez检索系统的一部分。截至2023年5月23日,PubMed包含超过3500万条引文和摘要,记录可追溯到1966年,部分可追溯到1865年,甚至少数可追溯到1809年。在此日期,大约2460万条记录包含摘要,2680 万条记录提供全文文章链接,其中约1090万条可免费获得。 在过去十年(截至2019年12月31日),PubMed平均每年新增近百万条新记录。
- ClinicalTrials:ClinicalTrials是一个全球性的注册和数据库,提供由私人和公共资金资助的临床研究信息。该资源由美国国家医学图书馆管理,包含每项研究方案的摘要,并且对于某些研究,结果以表格形式提供。用户可以使用研究状态、疾病或病症、国家/地区和其他关键词等标准搜索研究。该数据库不断更新,目前包含已在美国所有州和全球200多个国家/地区开展的30多万项研究。
- 开源医学知识图谱:CMeKG(临床医学知识图谱)CPubMed-KG(大型中文开放医学知识图谱)和Disease-KG(中文疾病知识图谱)是整合了大量医学文本数据(涵盖疾病、药物、症状和诊断治疗等领域)的开源医学知识图谱。组合后的知识图谱包含1,288,721个实体和3,569,427个关系。
工具
- RDKit:RDKit是一个用于化学信息学的开源工具包。 RDKit具有几个关键特性:它可以通过读取和写入各种文件格式(例如SMILES、InChI和Mol文件)来处理化学结构。它生成多种类型的分子指纹,从而能够进行化学结构比较和相似性搜索。RDKit还提供用于计算分子相似性的算法,并支持化学反应的表示和处理,包括识别反应物和产物。虽然它本身不提供分子对接功能,但RDKit可以与其他对接工具集成。此外,RDKit支持机器学习算法,允许对化学数据进行模式识别并构建预测模型。
- CADRO:常见的阿尔茨海默病及相关痴呆症研究本体(CADRO)用于从医学问答数据集提取阿尔茨海默病(AD)相关样本子集以进行评估。CADRO将术语组织成一个三层分类系统,包含八个主要类别和多个子类别,重点关注AD和相关痴呆症,其中包含该领域常用的术语或关键词。用户可从 CADRO 获取与医学问答数据集最相关的 AD 相关关键词列表。
社交图谱
社交图谱通常由通过其社会关系连接的实体组成,在现实世界应用中无处不在。一个主要的例子是像Twitter和Facebook这样的社交网络,其中实体代表通过社交互动(例如,友谊、关注者/被关注者、点赞和提及)联系的个人。这些社交图谱超越了人际互动,并且不局限于活的实体,例如动物社交网络中共同使用同一个洞穴的乌龟,电子商务推荐系统中同一个客户共同购买的互补产品,甚至是LLM模拟的社交代理。这些社交图谱中丰富的社会关系知识是GraphRAG的宝贵资源,本节将对此进行回顾。
应用任务
- 实体属性预测:实体属性预测侧重于预测社交网络中社交实体的属性和分类类别,其示例包括预测伙伴关系兼容性、评估道德、检测账户暂停、识别有害行为和产品属性预测。
- 文本生成:文本生成旨在生成与社会背景和规范一致的文本。通常,结构信息和文本信息之间的相互作用,例如基于邻近度的网络同质性和基于角色的相似性,构成了文本生成的基石。例如,Wang等人检索邻近/角色相似节点的文本,以增强目标节点的文本生成。Kim等人,Xie等人通过检索客户/产品的历史评论来生成个性化的推荐解释。此外,一些其他工作也利用语义相似性来检索参考/属性/观点,并增强下游评论生成。
- 推荐:推荐任务旨在找到最相关的项目以满足用户的需求。由于客户/项目交互缺失和稀疏(例如,冷启动问题),GraphRAG可以自然地应用于通过检索额外的元知识来增强客户/项目的稀疏交互。根据具体的推荐场景,GraphRAG已被用于基于图的推荐、下一个项目推荐和对话式推荐。
- 问答:问答任务不仅出现在知识和文档图领域,也出现在社交图中。例如,用户可能会问:“洛斯加托斯周边有哪些适合家庭聚会的最佳公园?”并期望得到个性化的查询答案。此外,此类问题可能明确需要图结构推理。例如,Wu等人构建了一个半结构化知识库,有些查询可能会问:“你能列出耐克生产的产品吗?”回答这个问题不仅需要深入理解查询,还需要熟悉数据的结构信息。
- 假新闻检测:检测假新闻需要同时考虑语义内容(例如,新闻内容)和结构交互(例如,新闻之间的交互)。例如,Ram等人根据通过与相同评论者共同交互检索到的其他Reddit帖子的可信度来评估Reddit帖子的可信度。
社交图构建
GraphRAG利用从社交图中获取额外信息的关联关系可以主要概括为三个基本原理:基于邻近性、基于角色和基于个性化的基本原理。基于邻近性的基本原理源于“物以类聚”的谚语,表明社交网络中彼此靠近的节点通常具有相似的属性。例如,亲密的朋友往往拥有相似的爱好。基于角色的基本原理侧重于具有相似局部子图结构的节点共享相似的特征或标签分布。例如,公司内同一层级的管理人员通常拥有相似的职称和职责,枢纽机场也表现出相似的运营特征和战略重要性。最后,基于个性化的基本原理指的是个体在特征和交互方面的独特性。例如,在推荐系统中,用户以各种方式与项目交互,例如点击、查看、添加到购物车、购买和评论,每次交互都提供GraphRAG可以用来个性化生成内容的有价值的知识。基于上述社交图中的三个关系基本原理,社交图构建方法可以总结如下:
- 用户-用户-交互:这种类型的社交图表示在Twitter、Reddit和Facebook等社交网络上常见的用户与用户之间的交互。例如,Twitter上的关注者-被关注者关系、Facebook上的朋友关系以及Reddit上用户对其他用户帖子的评论。请注意,与文档或知识图谱相比,这种用户与用户之间的交互在现实世界中自然存在,无需人工审核或修改。
- 用户-项目-交互:此类社会图谱代表了在亚马逊和eBay等电子商务平台上常见的用户与项目之间的交互。这些交互,包括购买、添加到购物车和查看,可以建模为二部图,其中每种交互类型都反映了独特的用户意图。
- 项目-项目-交互:此社会图谱捕捉项目之间的交互,通常由来自同一客户或用户的共享交互来识别。例如,两个产品之间的“共同查看”交互表明它们被同一客户查看,而“查看-添加到购物车”交互表明一个产品首先被查看,然后同一客户将另一个产品添加到购物车。在电子商务网络中,这两种项目之间的共同交互可以大致分为互补关系和替代关系。
- 元数据-交互:项目和用户通常拥有元数据。例如,亚马逊等平台上的产品可能包含品牌、制造商和颜色属性。此元数据可以表示为附加的节点类型以及指示产品和属性之间关系(例如所有权或关联)的相应边。
- 智能体-智能体交互:随着大型语言模型(LLM)智能的提高,最近的文献探讨了使用LLM驱动的智能体来模拟社会行为(例如协作、辩论和反思)的潜力。这些智能体-智能体交互也可以用于GraphRAG。
请注意,在上文中提到的五种交互类型中,用户-用户、用户-项目和元数据关系是自然形成的,无需人工审核。相反,项目-项目交互是通过手动提取生成的,而智能体-智能体交互需要模拟。
检索器
根据上述方法构建的社会图谱的关系可以利用在GraphRAG中,通过检索附加信息来增强下游任务。例如,检索历史元数据和客户交互可以改进推荐。接下来,我们回顾GraphRAG中用于社交图的代表性检索方法。
- 基于ID的检索器:类似于实体链接,基于ID的检索器通过检索用户/项目特地生成的内容来工作,例如检索特定客户的历史项目交互、特定产品的评论以及特定用户的元数据信息。
- 基于过滤的检索器:基于ID检索器,基于过滤的检索器基于协同过滤检索附加内容。对于用户过滤,通过比较其历史项目交互与需要推荐的目标用户的历史项目交互的相似性,识别出Top K用户。为了增强目标用户的上下文,它从这Top K用户中检索最受欢迎的项目。相反,对于项目过滤,它通过比较其用户交互历史,识别出与当前项目最相似的Top K项目。其中,将获取最受欢迎的项目以增强当前的项目推荐。
- 社交关系检索器:与基于ID的检索器类似,社交关系检索器专注于从与手头的目标实体共享某些关系的实体中检索知识。例如,Du等人从中心节点分层检索几个跳数的相邻文本,以增强目标用户/项目的语义信息。同时,Wang等人分别检索与共享基于邻近性和基于角色的相似性的节点相对应的文本。
- 集成神经符号检索器:这种方法利用符号和神经检索器来提高检索效率。符号检索器通过遵循明确定义的规则来检索信息,例如基于标识符、结构化关系或交互模式进行检索,确保检索到的数据严格符合特定标准。同时,神经检索器通过使用基于嵌入的相似性来补充这一点,捕获规则中可能无法直接编码的细微模式和上下文关系。将它们集成在一起可以在基于规则的精度和基于神经网络的自适应性和泛化能力之间提供更好的权衡。例如,Wang等人、Huang等人、Qiu等人首先从用户会话中的产品知识图(符号检索器)检索K跳相邻产品,然后进一步利用基于神经网络的自适应过滤来聚合与当前序列最相关的项目(即神经检索器)。类似地,Zeng等人通过结合基于ID的检索(基于一方的用户ID检索电影)和基于文本的检索器(实现各方之间的电影检索)来解决数据稀疏性和异构性问题。
组织者
为了进一步增强检索到的内容,社交图谱的组织者采用了超越其他图谱领域常用重排序和过滤技术的专业技术。对于社交图谱,GraphRAG的组织者通常使用关键词提取、个人资料摘要和分层图聚合来整理检索到的内容:
- 关键词提取:关键词提取识别从检索到的内容中提取最相关和信息最丰富的关键词。这些提取的关键词指导下游生成器优先关注并降低了使用过多的上下文信息压垮大语言模型(LLM)的风险。例如,Xie等人使用嵌入估计器来精确定位与个性化潜在查询对齐的关键词,然后将其用于生成解释。
- 个人资料摘要:个人资料摘要创建丰富且详细的用户个人资料,这些资料捕获诸如年龄、性别、喜欢的和不喜欢的类型、最喜欢的导演、国家和语言等属性,这些属性源自用户的过去互动和项目元数据。通过使用改写的个人资料,这些丰富的用户数据增加了检索内容的信息量,同时保护了隐私。此外,在通过用户/项目过滤检索相关电影后,Wang和Lim应用三步提示策略来提取适合用户的特征,并通过直接指示大语言模型(LLM)来选择具有代表性的电影。这些提取的特征和具有代表性的电影进一步用作用户个人资料,以指导最终推荐的生成。Guo等人利用大语言模型(LLM)根据来自外部数据的关键词/短语生成关于实体个人资料的更多详细信息,以辅助文本生成。
- 分层图聚合和摘要:在检索邻域文本信息时,较高邻域层中呈指数级扩展的感受野往往会导致聚合内容超过可管理的限制,这可能会降低大语言模型(LLM)的有效性。此挑战突出了对分层图聚合和摘要的需求。主要思想是首先对在每一层检索到的邻域信息进行摘要,然后再将其传播到下一层。这种方法使每个节点接收的文本量保持在一致的范围内。例如,Du 等人递归地聚合来自较高层相邻节点的信息,并在与较低层中的相关节点共享之前,利用大语言模型(LLM)来改写和压缩内容。因此,这种策略在优化下游生成任务的计算预算的同时,扩展了感受野。
生成器
一旦相关内容被检索并适当地组织起来,它就会被下游生成器进一步处理以生成最终内容。根据所需的输出,用于社交图的现有生成器可以分为基于大语言模型(LLM)的文本生成器和基于预测的生成器。这两种方法的选择取决于所需输出的格式和社交图应用的要求。
- 基于大语言模型的文本生成:当下游应用需要文本输出时,通常使用这种生成器,例如基于名称的项目推荐、推荐解释和评论生成。由于下一个符元预测的概率性,生成的文本可能并不总是与所需的输出精确对齐 为了解决这种幻觉问题,通常使用真实文本作为生成的文本的依据,例如将生成的项目与平台上的真实项目进行匹配。
- 基于预测的生成:该生成器直接预测输出,主要用于非文本任务,例如项目推荐和社交预测。例如,图神经网络已成为基于图的推荐的流行选择,并且Transformer用于项目推荐任务。此外,在社交属性预测中,生成器可以只是一个用于分类(例如,党派分类)或回归(例如,道德回归)的多层感知器。
资源和工具
本节列出了在社交图上使用 GraphRAG 的常用资源和工具。 摘要和链接如下所示:
数据资源
- STARK-Amazon:STARK-Amazon是一个大型半结构化检索基准数据集,用于亚马逊平台上的产品搜索,它整合了文本和关系知识库。数据集中的节点代表产品、颜色、品牌和类别,而边则捕获诸如 also_bought、also_viewed、has_brand、has_category 和 has_color 之类的关系。包括产品描述、客户评论和实体名称在内的丰富的文本信息,为检索任务提供了宝贵的上下文。查询是通过采样关系模板并将其与特定实体关联,然后利用大语言模型 (LLM) 来合成相关的文本和关系信息生成的。此过程产生的查询能够捕捉客户兴趣,解释专业描述,并推断查询中涉及多个实体的关系。
- Amazon-Review:Amazon-Review数据集包含带有评分、文本和有用性投票的评论,以及产品元数据,例如描述、类别、价格、品牌和图像特征。此外,它还通过“也浏览”和“也购买”图提供链接信息。此数据集有两个版本:初始版本记录了1996年到2014年之间的评论数据,而较新的版本记录了2014年的持续数据。最新版本还添加了新的元数据,包括详细的产品信息、项目符号和道德细节表。社交图谱中广泛的GraphRAG工作已利用此数据集构建用于推荐研究的RAG框架。
- MovieLens:MovieLens数据集描述了人们对电影表达的偏好。这些偏好采用元组的形式,每个元组都导致一个人在特定时间表达对电影的偏好(0-5 星评分)。这些偏好是通过MovieLens网站输入的——这是一个推荐系统,它要求用户给出电影评分以接收个性化的电影推荐。辅助信息包括以文本格式显示的电影标题、年份和类型。进一步抓取了可从此处访问的电影海报的视觉内容。请注意,Movielen-100k经常被使用,并为用户提供人口统计信息,例如用户 ID、年龄、性别、职业和邮政编码。
- Netflix:此数据集旨在支持Netflix奖的参与者。 电影评分文件包含来自48万名随机选择的匿名Netflix用户的超过1亿条评分,这些评分涵盖了1.7万部电影。数据收集时间为1998年10月至2005年12月,反映了在此期间收到的所有评分的分布情况。还提供了每个评分的日期、电影标题以及每部电影ID的上映年份。多模式侧信息是通过网络爬取收集的,并进一步存储在此。
- Yelp:Yelp数据集是学术研究的丰富资源,尤其是在数据科学、自然语言处理(NLP)和机器学习等领域。此综合数据集包含超过690万条评论、150346家商户和200100张照片,涵盖11个大都市区。研究人员和学生可以探索真实的商业和用户数据,其中包含有关商户的详细信息,例如位置、类别、属性(如营业时间、停车位和环境)以及汇总的签到信息。评论包括全文内容、用户评分和元数据,而用户资料则提供了对社交互动和行为的见解,包括朋友、赞扬和评论历史。 此外,该数据集还包含908915条提示,提供了快速的建议和见解,以及120万条商户属性,提供了关于服务产品的详细信息。
- 微博:微博数据集提供了新浪微博平台上用户互动、行为和社交联系的丰富快照,捕捉了社交网络的静态和动态方面。从100个随机选择的种子用户开始,该数据集扩展到包含170万用户和约4亿个关注关系,平均每个用户有200个关注者。每个用户都以社交个人资料详细信息为特征,包括姓名、性别、验证状态以及关注者/被关注者数量。推文内容以原始中文和索引格式提供,支持对社交网络分析、内容传播和用户互动动态的深入研究,使其成为RAG研究的宝贵资源。
- 英国脱欧:此数据集包含X(Twitter)网络的一部分,特别是2016年英国就退出欧盟进行公投之前的留欧与脱欧论述。它包含一个拥有7589个用户、532459个定向关注关系和19963条推文的网络,每条推文都与二元立场相关联。根据对数据集进行预处理,为每个用户分配一个介于0和1之间的标量值,称为观点,代表用户转发推文的平均立场。每条推文的立场要么是 0(“留欧”),要么是 1(“脱欧”)。
- Diginetica:此数据集包含来自电子商务搜索引擎的用户会话日志。数据跨越六个月,并捕获用户交互,包括点击、产品浏览和购买。每个用户会话(由一小时的非活动时间定义)包含匿名用户 ID、哈希查询、产品描述、元数据(价格、哈希产品名称、图像标识符和产品类别)以及对数缩放价格。
- Yoochoose:Yoochoose数据集包含来自欧洲在线零售商的会话数据。每个会话记录用户的点击事件,有些会话还包括购买事件。数据收集于2014年的几个月,捕获用户与零售商网站的交互。产品元数据包括类别。
工具
- X-开发者平台:X开发者平台为开发者提供了强大的工具和资源,使他们能够将X的实时、历史和全球数据集成到他们自己的应用程序中。该平台拥有三个主要产品——X API、X 广告API和适用于网站的 X——支持广泛的用例,从检索和分析推文到管理广告活动以及将X内容直接嵌入网站。X API提供用于管理对话、探索趋势和与用户互动的端点,而X 广告API使企业能够使用自定义定位和分析来管理广告。适用于网站的X允许无缝嵌入实时内容以增强网站参与度。通过全面的文档、库和社区支持,X开发者平台使开发者能够使用X的数据和参与工具创建创新的解决方案。
- Reddit-API:Reddit是一个新闻聚合和讨论平台,其中的帖子被组织成“subreddit”,即由社区管理的用户创建的版块。Reddit API为开发者提供了访问网站大量帖子和评论的权限。此免费API促进了审核工具、第三方应用程序以及用于ChatGPT、Google和Gemini等大型语言模型(LLM)的训练数据集的开发。通过使用此API,我们可以查询海量的用户交互(例如,评论和帖子)及其对应的文本内容(例如,子reddit主题),这些内容是GraphRAG的宝贵资源。
- Rec-Bole:RecBole是一个开源的、统一的、全面的库,旨在开发和测试推荐算法。RecBole使用Python和PyTorch构建,为研究人员提供了一个简化、高效的框架,用于实验超过100种推荐算法,这些算法涵盖四种主要类型:通用、顺序、上下文感知和基于知识的推荐。该平台通过提供43个基准数据集的预处理副本简化了数据处理,使用户可以轻松地进行模型测试和开发。提供的用户-产品交互以及文本格式的用户/产品元数据也可以用于GraphRAG。
规划和推理图
规划或推理图描述了不同实体之间固有的逻辑流程,其中实体通常代表具体的规划或推理子步骤,边表示它们的逻辑关系。对于规划图,一个常见的例子是一组用于实现特定目标的API工具,其中节点表示动作,边表示它们之间的关系依赖。对于推理图,一个值得注意的例子是最近提出的思维链/树/图技术,其中每个节点代表一个由推理流程连接的决策思维步骤。规划/推理图中的依赖约束和推理流程可以自然地表示为关系知识,这构成了GraphRAG完成规划/推理任务的基础。本节回顾了针对规划和推理图的GraphRAG。
应用任务
在规划和推理图上进行的代表性任务总结如下:
- 顺序计划检索:作为最常见的任务之一,计划检索旨在以子图的形式检索步骤或工具的计划以完成用户查询。 例如,给定用户查询“请生成一张图片,图片中一个女孩正在看书,她的姿势与“example.jpg”中的男孩相同,然后请用你的声音描述新图片”,从全局计划图中检索到的最终计划将是“姿势检测”→“姿势到图像”→“图像到文本”→“文本到语音”。
- 自然异步规划:与仅考虑计划之间依赖约束的计划检索相比,结合时间约束带来了更大的挑战。自然异步规划旨在利用时间求和、时间比较和约束推理,生成满足依赖关系要求并优化任务完成效率的计划。例如,用户可能会请求:“制作卡尔佐尼需要以下步骤和时间;请计算最佳完成计划。”一个高效的计划将按顺序执行“擀面团”、“添加馅料”和“填充面团”,同时并行执行“预热烤箱”,然后以“烘烤”结束。
- 结构化常识推理: 给定一个信念和一个论证,结构化常识推理旨在推断立场并生成/检索相应的常识解释图,以解释推断出的立场。
- 可驳斥推理:可驳斥推理是一种推理模式,其中,给定一个前提,假设可能会根据新的证据而被削弱或推翻。一种突出的方法是通过构建推理图来通过论证支持可驳斥推理。
- 工具使用: 指示大型语言模型 (LLM) 使用外部工具来解决复杂的现实世界问题越来越重要。 最近的研究探索了先进的规划策略,以增强大型语言模型的工具使用智能。值得注意的是,两种方法都采用了A*搜索和蒙特卡洛树搜索,两者都利用图结构推理根据大型语言模型的内部评估和环境反馈自适应地检索下一个工具。这些方法能够实现动态工具检索,从而提高模型解决问题的精度和灵活性。
- 具身规划: 具身人工智能中的具身规划任务涉及指导智能体根据自然语言指令和模拟或现实世界环境中的视觉线索执行一系列动作。这些任务,例如组织或清洁,由于指令不明确、特定任务知识有限、反馈稀疏以及复杂多变的动作空间而对智能体提出了挑战。
推理和规划图构建
大多数现有的构建推理和规划图的方法都是首先分析关系依赖性,然后根据这些硬编码规则添加边。因此,我们并没有将重点限制在仅审查这种基于规则的构建方法上,而是审查了用于添加边的各种依赖关系类别。
- 资源依赖:此依赖关系定义为不同动作/决策之间共享的资源。例如,如果一个工具的输出与另一个工具的输入匹配,则这两个工具就被连接起来,从而实现从一个过程到另一个过程的无缝过渡。在现有的图构建方法中,添加边的决策是通过检查一个节点的输入是否与另一个节点的输出匹配来做出的(例如,计划、工具或其他一些抽象过程)。
- 时间依赖性:这种关系确保事件序列遵循规划和推理过程中的特定顺序。例如,一些收集到的数据集中,连接表示日常生活中两个API之间的连续顺序。
- 包含依赖性:所描述的依赖性表明两个连接的节点属于同一类别或环境。例如,鹅卵石和鸟屋都属于花园装饰的范畴。超图可以有效地捕捉这种从属关系,其中一个实体属于多个环境。此外,这些依赖关系通常形成层次结构,“祖先”实体包含“父”实体,而“父”实体又包含它们的“子”实体。随着层次结构深度的增加,可能的依赖关系空间呈指数级增长,这带来重大的计算挑战。为了解决这个问题,许多以前的工作都提出了在双曲空间中编码这种层次结构。据我们所知,以前的研究尚未探索RAG系统中的包含依赖性。
- 因果依赖性:这种依赖性表示图中的因果逻辑,其中一个动作/决策导致另一个动作/决策的触发。一个长期存在的例子是因果图,用于编码关于数据生成过程的假设。
- 类比依赖性:这种依赖性强调类比推理,其中关系的形式为“A之于B如同C之于D”。通过识别和利用这种依赖性,人类在现有知识的基础上,在不同领域之间建立新的见解。 一个强有力的历史例子是库仑定律的发现,其灵感来自于影响天体的万有引力和带电粒子之间的电力之间的类比。
虽然资源依赖和因果关系都涉及顺序结构的关系(前一步/工具/决策导致后一步/工具/决策),但它们本质上是不同的。 例如,如果工具A生成PDF格式的报告,而工具B旨在从PDF文件中提取数据,则工具A和B共享资源依赖性,因为工具A的输出(PDF)与工具B的输入匹配。然而,这种联系并不意味着这两种工具之间存在直接的因果关系,即使用工具A并不一定会导致我们使用工具B。
检索器
用于处理推理和规划图任务的检索器通常被建模为图遍历器。查询或任务指令定位初始种子节点以初始化图遍历;然后遍历扩展图的范围,直到预设预算耗尽或满足特定条件。整个过程中的核心步骤是从所有潜在候选中选择最相关的邻居。基于邻域选择的标准,检索器分为两大类:基于嵌入的方法,它根据嵌入相似性优先考虑邻居;以及基于启发式的方法,它使用局部和全局奖励函数来确定邻居的重要性。
- 基于嵌入的:Wu等人分解查询,随后在连接的子查询与当前检索到的任务API以及每个现有API之间执行嵌入相似性匹配,然后从现有的相邻API中选择最佳的一个。它探讨了训练和不训练的策略。
- 基于启发式的:与依赖于专用训练数据进行映射的基于嵌入的方法相比,基于启发式的方法定义了规则来有效地指导图检索器。Zhuang等人将工具规划建模为树搜索算法,结合A*搜索,根据累积和预期成本自适应地检索最有效的工具以供后续使用。这两个成本函数都是启发式设计的,借鉴了以前的文献和实践经验。
- 思想传播检索:给定一个输入问题,思想传播检索提示大型语言模型(LLM)提出一组类似的问题,然后应用已建立的提示技术,例如思维链(Chain-of-Thought, CoT),来推导出解决方案。聚合模块随后整合这些类似问题的解决方案,增强了对原始输入的解决问题过程。
组织者
当前关于规划和推理图的GraphRAG文献通常忽略组织者机制,因为仅检索过程就达到了足够的精度,无需重新排序。与通常应用一次性基于嵌入的相似性检索来选择前K个相关内容的文档或知识图不同,规划和推理图使用与推理步骤集成的多轮嵌入相似性过程,从而提高了计划的保真度。此外,基于奖励的检索涉及一种复杂的搜索,进一步提高了准确性。这些高质量的策略共同减少了对细粒度重新排序或过滤的需求。
生成器
大多数现有的用于推理和规划任务的GraphRAG方法要么直接输出检索到的计划,要么将其集成到LLM中以进行下游解决方案生成。例如,Wu等人将检索到的图结构化计划作为最终结果输出,而Shen等人则编译来自专家工具的执行结果以生成响应。类似地,在构建工具调用图之后,Shen等人直接提示LLM生成参数,而Lin等人则利用LLM根据任务依赖性、时间和图约束生成异步计划。值得注意的是,这些工作大多集中在融合文本信息上,主要使用以文本形式呈现的不同图结构格式(例如,邻接矩阵、邻接表、边列表、CSR)。
资源和工具
我们总结了用于规划和推理图的GraphRAG的有用资源和工具。
数据资源
- Hugging Face:Hugging Face 提供了广泛的 AI 模型,涵盖语言、视觉、音频、视频等多模态任务。每个任务对应一个处理特定输入和输出的工具节点。如果工具A和B连接,则A的输出类型必须与B的输入类型匹配。因此,Hugging Face计划图中的边表示资源依赖关系。首先收集工具库,并构建一个包含一系列工具及其依赖关系的工具图。然后,为了生成每个问题,他们从工具图中以三种基本格式(节点、链和有向无环图(DAG))采样一个子图,每种格式都体现了工具调用的特定模式。之后,采样的子图被发送到大型语言模型(LLM)以合成用户指令并填充工具子图的参数。最后,基于大型语言模型 (LLM) 和基于规则的自批判机制用于检查和过滤生成的指令以保证质量。
- 多媒体:与Hugging Face专注于人工智能的工具不同,多媒体工具服务于更广泛的以用户为中心的任务,例如文件下载和视频编辑。边缘与Hugging Face领域保持一致,工具连接表示类似于Hugging Face的资源依赖关系。多媒体的构建与Hugging Face类似。
- 日常生活API:日常生活服务,包括网络搜索和购物,也可以被视为特定任务的工具。这些API之间的依赖关系主要是时间上的,这意味着如果两个日常生活API在序列中一个接一个地出现,则它们之间存在连接。日常生活API的构建与Hugging Face大多相似,只是由于公开可用API的稀缺性,边缘是手动构建的。
- RestBench:一个包含多个API的数据集,用于解决两种场景中复杂的现实世界用户指令:TMDB电影数据库和Spotify音乐播放器。TMDB电影数据库提供RESTful API,包含有关电影、电视、演员和图像的信息。Spotify音乐播放器提供API端点,用于检索内容元数据、接收推荐、创建和管理播放列表以及控制播放。对于RestBench,聘请NLP专家为不同API组合集思广益指令,并相应地为每个指令标注黄金API解决方案路径。进一步聘请了两位额外的专家来彻底验证每个指令的可解性及其对应解决方案路径的正确性。为了将RestBench改编成一个图结构的数据集,将每个API视为一个独特的任务节点,通过两个关键维度建模它们之间的关系:(1)类别关联和(2)资源依赖性。例如,提供与电影相关的功能的API(例如检索电影详细信息或推荐电影)被归入“电影”类别,而专注于与人物相关的任务的API(例如搜索演员)则被归入“人物”类别。此外,如果两个API共享一个公共参数(例如,movie-id),则建立一个链接来表示资源依赖性。 为了进一步增强语义区分,GPT-4被提示为每个API分配一个唯一的名称和详细的功能描述。
- AsyncHow:一个包含1.6K个数据点的异步规划精选数据集。每个数据点包含一个用户指令,该指令指定任务及其基本执行约束,用有向无环图 (DAG) 表示。在这些DAG中,节点表示动作,边表示顺序约束。每条边都带有权重,表示完成前一个动作并转换到下一个动作所需的时间。此外,边还表示因果关系,这意味着只有在完成所有先前链接的动作后才能执行一个动作。为了构建此数据集,我们首先从WikiHow收集规划任务。然后使用大型语言模型(LLM)进行预处理、时间标注和步骤依赖性标注。具体来说,过滤掉了包含可选步骤、无关任务或缺乏可量化持续时间的计划。使用GPT-3.5估计每个步骤的时间持续时间,并使用GPT-4使用DOT语言标注步骤依赖关系。为了生成带有执行约束的自然语言问题,使用了十个微不足道但合理的模板将图结构的点语言释义为人类可理解的文本。通过确定工作流程DAG表示中的最长路径来计算计划的最佳时间持续时间。
- EXPLAGRAPHS:给定最初收集的三元组(包括信念、论点和立场),通过一个通用的创建-验证-细化迭代框架构建常识解释图。首先,标注者构建一个常识增强的解释图,明确解释立场。每个图包含3-8个事实,每个事实都是一个三元组,其中两个概念作为实体通过它们的关系连接起来。图形表示允许我们自动执行浏览器内结构约束检查,从而保证图的结构正确性。为进一步确保构建图的语义正确性,标注者会推理该图,仅基于信念和解释图来推断立场。最后,对于错误的图,另一位标注者会通过添加新事实、删除现有事实或替换现有事实来对其进行细化。
- GSM8K:GSM8K数据集包含8.5K个高质量、语言多样化的数学文字题,旨在评估用于问答的多步推理能力。这些小学水平的问题,一个聪明的中学生就能解答,需要2到8个步骤,主要使用基本的算术运算(+,−,×,÷),不需要超出初等代数的概念。解决方案以自然语言呈现,以促进通用适用性,从而深入了解大型语言模型的推理过程。此格式突出了模型如何处理针对现实世界数学问题的结构化、逐步推理。
- PrOntoQA:PrOntoQA是一个问答数据集,它提供包含思维链的示例,以概述正确答案所需的推理过程。这些句子句法简单,非常适合语义解析,这使得它对于对来自大型语言模型(如GPT-3)的预测推理链进行形式化分析非常有价值。
工具
- ToolBench:最近关于使用LLM进行软件工具操作的研究主要依赖于封闭模型API(例如,OpenAI),因为这些专有模型与可用的开源LLM之间仍然存在显著的性能差距。为了调查这种差异的根本原因,并提高开源LLM的能力——尤其是在工具操作方面——已经开发了一个名为ToolBench的基准测试。 ToolBench包含一系列为现实世界任务设计的各种软件工具,并提供了一个易于访问的基础设施,用于直接评估每个模型的执行成功率。
表格图
表格数据是另一种在现实世界应用中广泛使用的结构化数据类型,通常存储在关系数据库中。表格数据可能包含一个包含样本及其属性的单个表,或者多个共享主键和外键的表。人们已经探索使用LLM来处理和解决涉及表格数据的任务,主要方法是通过序列化将表格数据转换为文本。然而,这种序列化可能会导致一些问题:(1)对于单个表格,特征列应该表现出置换不变性,但序列化表格数据可能会破坏这种不变性;(2)对于多个表格,一个表格可能通过主键/外键与另一个表格连接,利用这些关系对于各种任务至关重要。因此,图结构可以作为表格数据的合适表示。此外,当表格包含过多行而无法放入大语言模型(LLM)的上下文窗口中时,图可以促进高效的检索。
应用任务
表格广泛用于现实场景中,用于存储数据特征及其之间的关系。理解表格数据的结构至关重要。因此,许多任务都可以从使用表格图中受益,下面我们列举了一些具有代表性的任务。
- 节点级任务:节点级任务包括节点分类和节点回归,应用于细胞类型预测、欺诈检测、异常值检测和点击率(CTR)预测等任务。
- 链路级任务:链路级任务包括链路预测、边分类和边回归。许多表格数据任务可以建模为链路级任务,例如数据插补和推荐。
- 图级任务:图级任务旨在预测整个图的属性,例如表格类型分类和表格相似度预测。
- 表格问答:表格问答(Table QA)涉及通过理解和推理表格数据来生成答案。这项任务需要理解表格中的内容及其关系,因此图结构适合于编码此类信息。例如,Zhang,Zhang等人利用图来增强表格问答。
- 表格检索:表格检索专注于根据自然语言查询检索语义相关的表格。
表格图构建
在表格数据学习中,图用于建模高阶特征交互、高阶实例关系以及跨多个表格的实例之间的关系。节点通常分为两种类型:实例节点,代表表格的每一行;特征节点,代表单个特征。 通常,构建以下类型的图:
- 实例图:实例图连接表格的行(实例),建模实例之间的关系。它对于在表格数据中检索相关实例特别有用。构建实例图主要有两种方法:
- 基于规则的方法:根据预定义的规则连接实例。例如,可以利用从专家知识中得出的启发式方法来连接共享某些特征的实例。可以利用专家知识来构建图。另一种常见的方法是基于相似性的方法,例如通过K近邻(KNN)连接实例,或者基于超过阈值的相似性。
- 可学习的方法:在这种方法中,通常使用规则或启发式方法初始化实例图。然后在学习过程中调整边权重,允许模型随着时间的推移动态地细化图结构。
- 特征图:特征图连接特征,边代表成对特征之间的相关性。 通常,特征关系以可学习的方式建模。有些工作通过利用特征相似性来构建特征图,而另一些工作则使用基于专家知识的启发式方法来建立连接。此外,某些方法如果特征属于同一个实例,则会将这些特征关联起来。
- 实例-特征图:实例-特征图是一种异构图,它将实例与其对应的特征连接起来。
- 单元图:单元图将表格中的每个单元格视为一个节点。Xue等人构建了一个单元图,其中每个单元节点都包含空间和逻辑位置属性,而邻接矩阵表示两个单元格之间的邻居关系或同一行和同一列的关系。
- 表格超图:超图是图的推广,其中一条边(称为超边)可以连接多个节点。由于表格通常对任意行和列的排列不变,因此超图是建模表格数据的合适结构。具体来说,Chen等人将表格中的每一行和每一列建模为一个超边,用于预训练。此外,Du等人从表格数据构建了一个超图,以有效地捕获实例之间的关系。
Comments NOTHING