
摘要
大语言模型的出现改变了生成式Agent,其中最近,大型语言模型(llm)的出现彻底改变了生成代理。其中,角色扮演会话代理(Role-Playing Conversational Agents, RPCAs)因其能够与用户进行情感互动而备受关注。然而,缺乏一个全面的基准阻碍了这一领域的进展。为了弥补这一差距,我们引入了CharacterEval,这是一个全面评估RPCA的中国基准,并辅以量身定制的高质量数据集。
数据集包括1785个多轮角色扮演对话,其中共有11376个例,和77个来自中文小说和剧本中的角色。
使用GPT-4提取最初对话,然后进行严格的人工审核,并通过百度百科提供的人物资料进行增强。。CharacterEval采用多方面的评估方法,包括四个维度上的13个目标指标。为了便于在CharacterEval中方便地评估这些主观指标,我们进一步开发了基于人类注释的角色扮演奖励模型CharacterRM,与GPT-4相比,该模型与人类判断的相关性更高。性格评价的综合实验表明,汉语llm在汉语角色扮演会话中表现出比GPT-4更有前景的能力。源代码,数据源和奖励模型被公开在:https://github.com/morecry/CharacterEval
引言
目前已有的RPCA benchmark,主要的问题是数据集的构建。虽然已有部分数据集,但是这些数据集的质量令人担忧,它们要不然是由llm产生的,要么是由于提取方法而受到显著的噪声影响。这些限制使得评估结果对于RPCA的实际能力是不可靠的。因此,作者构建了一个中文角色扮演会话数据集,包含1785个多轮角色扮演会话,11376个会话示例和77个主要角色,这些数据来自不同的中文小说和剧本。然后,使用GPT-4提取这些来源的对话场景、话语和主角的行为。在基本的预处理和删除较少回合的对话之后,我们邀请注释者来评估对话的质量。他们的任务是确定和保留高质量的对话,同时丢弃低质量的对话。此外,我们还从百度百科中抓取了详细的人物档案,组成了一个用于RPCA评估的综合数据集。数据集中的示例如图1所示。

另外,角色扮演对话是一项复杂的任务,不仅需要模仿角色的行为和话语,还需要保持角色的知识,以及出色的多轮对话能力。因此,本文提出了一个多方面的评估方法,包括四个维度的13个具体指标。评估方法考虑了对话能力、性格一致性、角色扮演吸引力,并利用人格回溯方法来评估角色扮演的角色性格准确性。
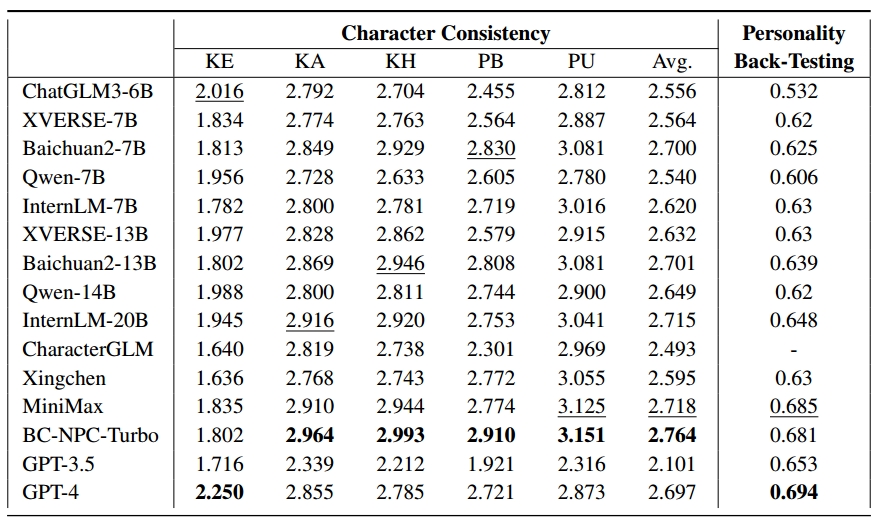
为了评估对话能力,从句子和会话两个层面评价会话的流畅性、连贯性和一致性。在角色扮演的对话中,角色一致性是最重要的。因此,我们评估知识和角色的一致性来衡量RPCA如何模拟角色。这具体包括知识的露出(knowledge exposure,KE)、知识的准确性(knowledge accuracy)和知识幻觉(knowledge hallucination),以及评估行为一致性(behavior consistency)和表达一致性(utterance consistency)。
考虑到角色扮演的娱乐性,角色扮演的吸引力也是一个重要因素。我们通过人类的相似性(human-likeness)、沟通技巧(human-likeness)、表达多样性(human-likeness)和同理心(empathy)来评估这一点。最后,我们引入了人格反测。以收集的Myers- briggs类型指标(MBTI)人格类型为参考,我们让RPCAs进行MBTI评估并计算MBTI准确性(人格回测)。
为了方便重新实现,我们邀请了12个注释者为我们的评估系统中的主观指标的不同模型生成的响应打分。基于人类的判断,我们开发了一个角色扮演奖励模型- CharacterRM,其与人类的相关性可以超过最先进的LLM GPT-4。在CharacterEval方面,我们对现有的llm进行了全面的评估,包括开源和闭源模型。实验结果表明,我们提出的中文LLM前景广阔,而gpt系列模型在中文角色扮演会话中并不占主导地位。
问题描述
角色扮演会话代理(RPCA)的设计目的是通过模拟特定的角色与用户进行对话。这些角色是由他们的知识、行为和回应风格来定义的。为了实现这一目标,RPCA需要使用一个角色模板P、上下文对话C_n=[q_1,r_1,q_2,r_2,...,q_n]。q_i和r_i分别对应对话中的第i个问题和回答。RPCA的目标是生成与角色预设相同的回答r_n,公式为:
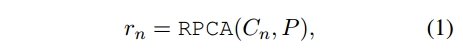
其中回答r_n由两个元素组成:行为和话语。行为包含在括号中,提供了关于角色动作、表情和语气的详细描述。这种分离允许对RPCA的能力进行细粒度的评估,不仅可以生成适当的话语,还可以生成独特的行为特征。
数据收集
数据收集原则
- 忠实于原著(Fidelity to Source Material):所有对话都要与原著保持一致,确保任务真实性;
- 分布多样性(Diversity in Distribution):数据集必须包含广泛的场景,用于彻底评估角色扮演能力;
- 多轮对话特征(Multi-Turn Feature):数据集应该主要由多回合对话组成,而不是局限于单回合对话;
- 人类在环(Human-in-the-Loop):为了保证质量、人类参与是必要的,因为仅仅依赖LLMs是不充分的。
数据收集流程
- 情节划分(Plot Division):小说和剧本等叙事文本的情节非常复杂,很难将文本划分为有意义的块,使用句子标记工具而不考虑语义可能导致对话中断。因此,使用GPT-4识别情节转折,即表示连续情节结束的句子。然后是由这些情节转折将文本分割成块,每一块中包含一个完整情节。
- 对话抽取(Dialogue Extraction):使用GPT4从情节块中抽取角色扮演对话。为GPT设计提示词来进行信息提取,从而保留人物的话语(utterances)、行为(behaviors)和情节场景( scenes)。
- 质量过滤(Quality Filtering):小说和剧本中的对话通常涉及两个以上的人物。如果简单的保留两个角色的对话而忽略其他角色会扭曲对话结构。因此,按照ABAB模型保留对话,直到出现第三个人物的加入。此外,只保留超过五轮(6条)对话,过滤短对话。
- 人类注释(Human Annotation):尽管llm具有抽取任务的基本能力,但是回复随机性会影响数据质量。因此,需要人工标注来评估对话的一致性和质量,删除任何有问题的对话。
评价指标
如图2所示,我们设计了一个四维评价体系,包括会话能力(conversational ability)、角色一致性(character consistency)、角色扮演吸引力( role-playing attractiveness)和个性回溯测试(personality back-testing),共13个指标:

会话能力
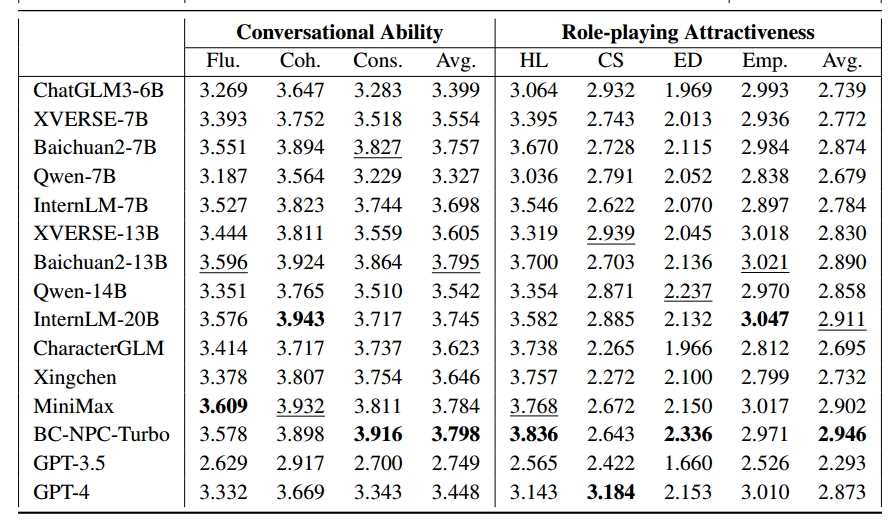
在角色扮演会话中,基本的会话能力是首先要考虑的。文章专注于生成答案的三个关键目标:流畅性、连贯性和一致性。
- Fluency (Flu.):衡量回复的语法正确性,表明回复是否可读且没有明显的语法错误;
- Coherency (Coh.) :评估回答和上下文之间的主题相关性。当用户询问特定主题时,RPCA应该根据问题进行回答,而不是提供不相关的答案;
- Consistency (Cons.) :在会话期间评估RPCA的稳定性。RPCA的回答不应该与之前回合的回答相矛盾。
角色一致性
角色一致性是评价角色扮演角色的重要指标。当角色角色一致性变化时,会给用户带来最直观的体验。具体来说,从知识一致性和人物一致性两个层面来评估角色一致性。前者评估RPCA是否能够根据角色的知识做出反应,包括知识暴露、准确性和幻觉指标。后者评估RPCA的反映是否符合角色的个性,包括行为和话语指标。
- Knowledge-Exposure (KE):为了评估回答的信息量,RPCA在回答中反映知识是至关重要的,这只吃了其对知识表达能力的评估。
- Knowledge-Accuracy (KA):一旦RPCA展示了使用特定知识生成回答的能力,评估这些回答是否与角色一致。RPCA的目标是根据来自角色的概要知识生成准确的回答。
- Knowledge-Hallucination (KH):将知识幻觉纳入角色扮演对话的评估。为了增强用户体验,RPCA应该保持与角色身份的一致性,并避免回答未知知识的问题。
- Persona-Behavior (PB):角色的行为(通常在括号内描述)通过描绘细粒度的动作、表情和语气来改善用户的感受。一致的行为是有效RPCA的标志
- Persona-Utterance (PU):除了行为举止,角色的说话风格也很重要。每个角色都有独特的表达习惯。因此,RPCA的话语应该与这些习惯保持一致,以熟练地模仿角色。
角色扮演吸引力
RPCA是需要对用户的情绪敏感。因此,引入角色吸引力维度来评估RPCA在对话中的吸引力。从用户的角度来看,考虑四个关键维度:鱼人相似、沟通技巧、表达多样性和同理心。
- Human-Likeness (HL):大多数大模型是为了信息搜索而设计的,往往灰提供机械的、没有感情的答案。然而,在角色扮演任务中,RPCA需要展现出防护一个更像人类的角色形象。
- Communication Skills (CS):在人类社会中,巧妙沟通的能力,通常被称为情商(EQ),对一个人的受欢迎程度有重要影响。因此,用户更有可能与情商较高的RPCA互动,这反映了在日常生活中具有强大沟通技巧的个人的受欢迎程度。
- Expression Diversity (ED):《CharacterEval》中的对话来源于现有的小说、剧本和各种文学作品,人物在行为和话语上都具有丰富多样的表达能力。因此,RPCA应该努力在对话中表达这种多样性,为用户提供更具沉浸感的体验。
- Empathy (Emp.):虽然RPCA的主要角色不是情感咨询师,但表达同理心可以显著影响对用户的好感度、在角色扮演任务中评估同理心可以让RPCA成为一个更热情、更友好的对话伙伴。
个性回溯测试
通过人格回溯测试评估RPCA在人格维度背景下的角色扮演能力,采用MBTI进行人格分类。为了获得必要的标签,从网站中收集人物角色的MBTI信息。
人物角色MBTI数据:https://www.personality-database.com/
MBTI性格测试网站:https://www.16personalities.com/
案例分析
数据描述
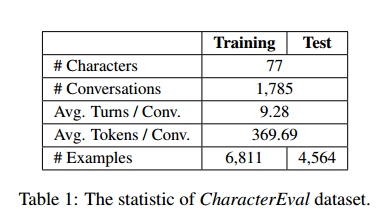
将数据集按照示例拆分为训练集和测试集,示例有元组组成(人物、上下文、回答),数据集的统计信息如下所示:
实验设置
CharacterEval采用一套全面的细粒度主观指标(会话能力、角色一致性和角色扮演吸引力维度中的12个指标)来评估角色扮演对话代理(RPCA)的多维能力。然而, 单个示例是不能够充分代表RPCAs的全部维度的。因此,我们使用人工建立稀疏性能评估矩阵,即利用人工对CharacterEval的一个子集进行主观指标评价,使得评价结果更有差异性。
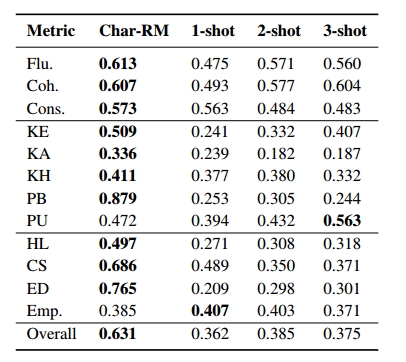
然后,基于这些为每个例子选择的指标,招募12个注释者,以五分制对不同模型的回答进行评分。人类的标注结果被用来训练一个以Baichuan2-13B为基模型的角色扮演奖励模型(characterRM)。实验结果表明,CharacterRM比GPT-4与人类判断结果的相关性更好,如下图所示。虽然GPT4的性能会随着演示次数的增加而提高,但是高昂的token使得其成本评估难以评价。因此,使用CharacterRM对主观指标进行后续评估。在MBTI测试中,手机了54个角色的mbti,使用训练的RPCA回答MBTI问卷,然后计算准确性。
评估LLMs
在这项工作中评估了10个具有不同参数的大语言模型Baseline,包括开源和闭源模型。对于开源模型,评估它的聊天版本,对于闭源模型,利用官方API进行心梗评估。使用GPT-3.5-turbo-1106版本作为GPT-3.5。在被评估的模型中,CharacterGLM、MiniMax、Xingchen和BC-NPC-Turbo是为角色扮演量身地址的大模型,其余模型是为一般聊天应用而设计的。值得注意的是,GPT-4和GPT3.5是唯一两个在主要由英语语料库组成的数据集上训练的模型。我们始终为每个模型使用相同的提示符,仅对闭源模型进行了微小的调整。
性能概述
各个模型在四个维度的评价结果如下图所示。BC-NPC-Turbo在前三个维度表现出色,而GPT-4在MBTI测试中表现突出。专门为角色扮演对话设计的大模型,如Xingchen、MinMax和BC-NPC-Turbo经过针对性训练,显示出更好的结果。在开源模型中,InternLM-20B和Baichuan2-13B的潜力较高。
尽管缺乏针对角色扮演对话的专门定制,大部分模型在评估维度上都呈现出值得称道的结果。相比之下,GPT-4在中文角色扮演对话的有效性有所下降。其在英语语料库中的主要训练限制了其在复杂角色扮演场景中的适应性和对中国文化的深刻理解。
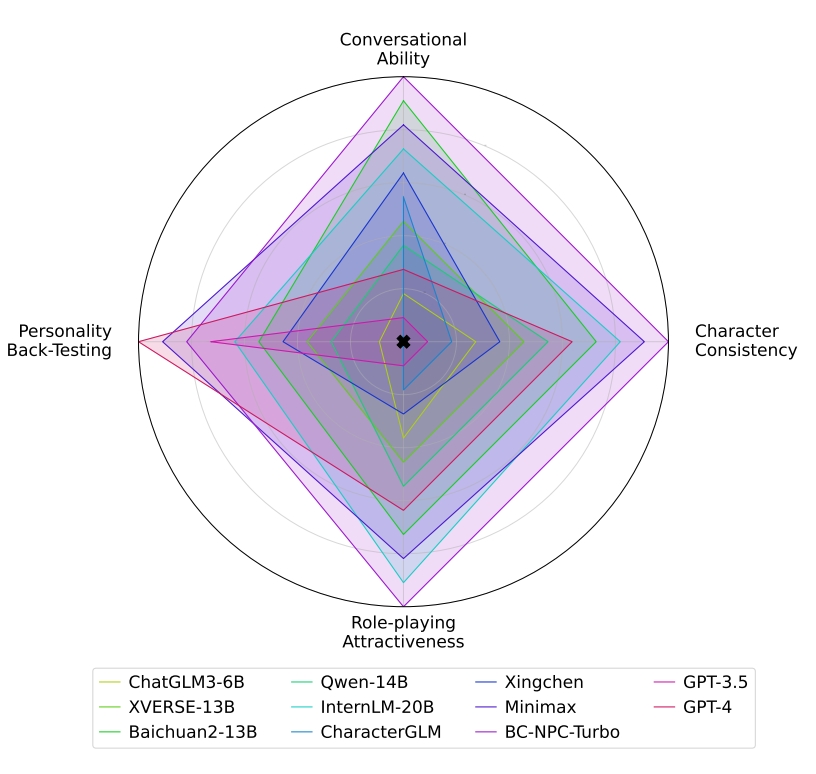
GPT-3.5在CharacterEval的表现最差。他倾向于产生过于安全的回答,比如:“我只是一个人工智能助手,不能进行角色扮演”,这凸显了它在角色扮演应用程序中的局限性。这个问题源于RLHF的过度对齐,使其不适合动态角色扮演交互。
结果明细
下表给出了跨13个指标的详细性能。在会话能力方面,BC-NPC-Turbo表现出了优异的表现,会话的一致性以及相对的流畅性和连贯性都证明了这一点。在对比开源和闭源模型时,很难在这个维度中宣布最终的赢家。
在进行同类模型的比较时,参数数量增加可以增强会话能力。在小于10B的模型中,Baichuan2-7B和InternLM-7B表现相当。此外,假设复杂的角色扮演对话和中文场景可能会挑战GPT系列,潜在地导致他们的表现下降。
结论
在这项工作中,我们致力于建立一个全面的基准来评估最近的角色扮演会话代理(RPCAs)。我们引入GPT-4从现有的小说和剧本中提取对话,并进行严格的人工过滤。经过一系列的处理,我们发布了一个高质量的多回合角色扮演数据集。在此基础上,构建了一个综合评价体系,对rpca的多维能力进行评价。我们还收集人类注释来训练一个基于字符的奖励模型来衡量主观指标,以便以后方便地重新实施。大量的实验结果表明,中文llm在中文角色扮演会话中比GPT-4具有更大的潜力。
Comments NOTHING