
MetaData
- 发表时间:2023.10.01
- 作者:Zekun Moore Wang, Zhongyuan Peng, Haoran Que, Jiaheng Liu,Wangchunshu Zhou, Yuhan Wu, Hongcheng Guo, Ruitong Gan, Zehao Ni,Man Zhang, Zhaoxiang Zhang, Wanli Ouyang, Ke Xu, Wenhu Chen, Jie Fu, Junran Peng
- 项目链接:https://github.com/InteractiveNLP-Team/RoleLLM-public
摘要
在本文中,作者提出了RoleLLM,一个包括benchmark、elicit和增强大模型角色扮演能力的框架。RoleLLM包括四个阶段:(1)100个角色的角色配置构建;
(2)面向角色知识抽取的基于上下文的指令生成(Context-Instruct);(3)RoleGPT:通过基于提示工程的角色提示语以及系统指令和检索增强,利用GPT(Role Prompting using GPT,RoleGPT)的角色提示进行说话风格模仿;(4)角色条件指令调优(Role-Conditioned Instruction Tuning, RoCIT),用于微调开源模型以及角色定制。通过基于上下文的指令生成和基于角色提示的GPT,我们创建了RoleBench,这是第一个系统的、细粒度的角色扮演基准数据集,包含168,093个样本。此外,RoCIT在RoleBench上生成了RoleLLaMA (English)和RoleGLM (Chinese),显著提高了角色扮演能力,甚至达到与RoleGPT(使用GPT-4)相当的结果。
引言
角色扮演旨在让LLM能够模拟具有不同属性和会话风格的各种角色或人物,为用户提供更细致入微的交互体验,并使llm更加亲近(familiar),友好(companionable)和沉浸(immersive)。
然而,现有的开源模型主要是在通用领域进行训练,缺乏对角色扮演的特定优化。此外,尽管GPT-4等最现金的llm展现出优秀的角色扮演功能,但他们闭源的特性造成了一些限制,包括高昂的API成本、无法进行微调以及有限的上下文窗口大小。
为了缓解这些问题,之前已经针对闭源和开源模型提出了若干方法,然而,这些方法都有局限性:
-
粒度有限(limited granularity):主要关注粗粒度的人格特征、职业(如程序员、作家),忽略了角色层面上更加复杂、精细的角色扮演。
-
缺少数据和benchmark:缺乏高质量、多样化和广泛的开源数据集,也缺乏评估基准;
-
API和上下文成本:ChatGPT和GPT-4等依赖闭源模型的方法无法自由微调,因此需要在提示词中包含所有补充信息,不必要地占用上下文窗口。此外,API成本高得令人望而却步。因此,探索最小化上下文窗口利用率并基于微调开源模型的解决方案是值得研究的。
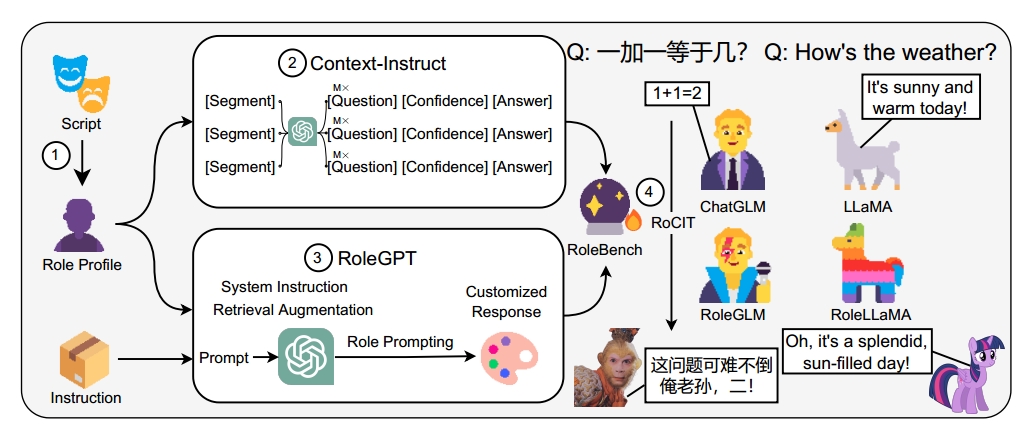
在本文中,作者介绍了RoleLLM,一个用于数据构建、评估和解决方案的角色扮演框架,适用于闭源和开源模型。在下图中,RoleLLM包含四个关键阶段: -
角色配置文件构建(Role Profile Construction):我们从916个英文和24个中文公开台本中精心挑选了95个英文和5个中文角色,在细粒度的角色级别上构建了不同个性的角色配置文件;
-
基于上下文的指令生成(Context-Based Instruction Generation (Context-Instruct):使用GPT从分割的配置文件中生成高质量的QA对,以提取角色特定的知识。
-
基于角色扮演的提示词工程(Role Prompting using GPT (RoleGPT)):我们通过基于对话工程的角色提示,利用系统指令和检索增强,在GPT中培养角色扮演能力,以产生定制的口语模仿反应;
-
角色条件指令调优(Role-Conditioned Instruction Tuning (RoCIT)):通过微调开源LLaMA,获得了RoleLLaMA和RoleGLM。RoleBench是第一个用于细粒度角色扮演的系统指令调优数据集和基准。
在实验中使用三个Rouge-L-based指标来评估模型的说话风格模仿(speaking style imitation)、回答准确性(answering accuracy)和角色特定知识捕获(role-specific knowledge capturing),与AlpacaEval一致的GPT评估也被使用。作者的主要结论包括: -
RoleGPT比提示工程的评估结果更好
-
RoleBench显著提高了模型的角色扮演能力,在某些情况下甚至达到了与RoleGPT竞争的效果。
-
RoleLLaMA在说话发风格模仿和对位置角色的准确性方面表现出强大的泛化能力,只需要角色描述和口头语即可有效适应,用户可以无缝定制新的角色。
-
基于系统指令的方法在角色定制有效性和上下文效率方面优于检索增强方法。
-
Context-Instruct显著增强了模型对角色的额的认识,在使用有噪声的角色配置时优于基于检索增强的方法。
方法
在本节中,我们将描述我们的角色扮演方法。我们首先介绍我们的解决方案的设计原则。然后,我们说明了两种角色扮演数据增强机制:RoleGPT和Context-Instruct。最后,我们提出了与基于系统指令的角色定制过程相关的角色条件指令调优(RoCIT)。
设计原则
模仿说话风格。为了模仿特定角色的说话风格,模型对指令的回应需要符合两个标准:(1)词汇一致性(Lexical Consistency):模型的回答应该包含角色常用的口头禅或习惯用语,以确保词汇与角色独特的语言风格保持一致。(2)对话保真度(Dialogic Fidelity):模型的答案不仅应该在语境上合适,而且在风格上与角色的示例对话相似。例如,海盗角色的词汇一致性包括频繁使用航海术语(aweigh)和口头语“matey”或“ahoy”。此外,对话的保真度应该捕捉角色独特的语法和语调(例如:口语表达、粗鲁的说话方式和无法无天的语气)
角色特定知识和记忆的注入。角色扮演的另一个重要方面是灌输特定角色的知识和情景记忆。考虑两种吧冉的知识类别:(1)基于台本的知识,涉及记录在脚本中的明确细节,例如详细的角色背景、情景记忆和角色经历的特定事件。(2)剧本中没有明确的知识,包括角色可能拥有的一般知识或专业知识。例如,当扮演钢铁侠时,llm应该包含基于剧本的知识(例如何时创建了第一个钢铁侠套装)和作为企业家与剧本无关的知识(例如商业头脑、领导素质和技术专长等)。
RoleGPT:通过prompt激发模型的角色扮演能力
考虑到微调的限制,为角色扮演GPT通常使用提示工程,如zero-shot和few-shot(in context learning)。然而,对于ChatGPT和GPT4来说,他们已经放弃了上下文学习能力来进行对话历史建模,传统的zero-shot提示并不足以充分激发角色扮演能力。因此,作者修改了提对话工程中的few-shot提示词,如下图所示:
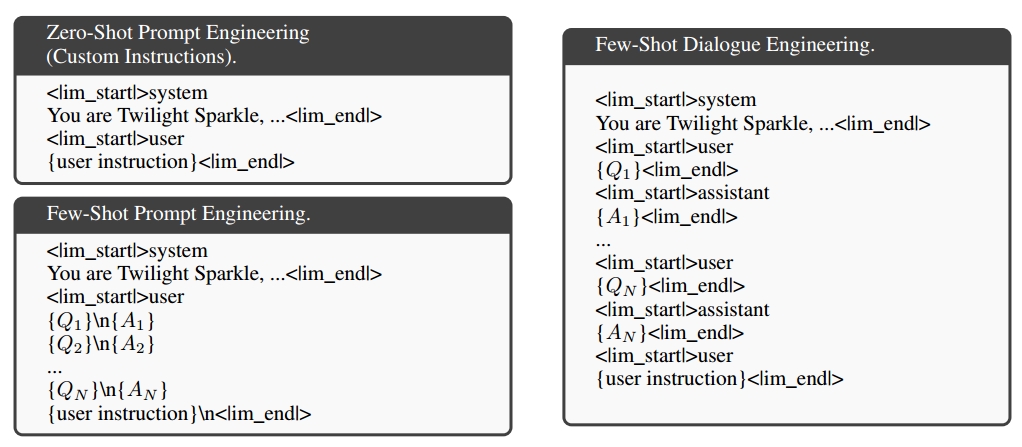


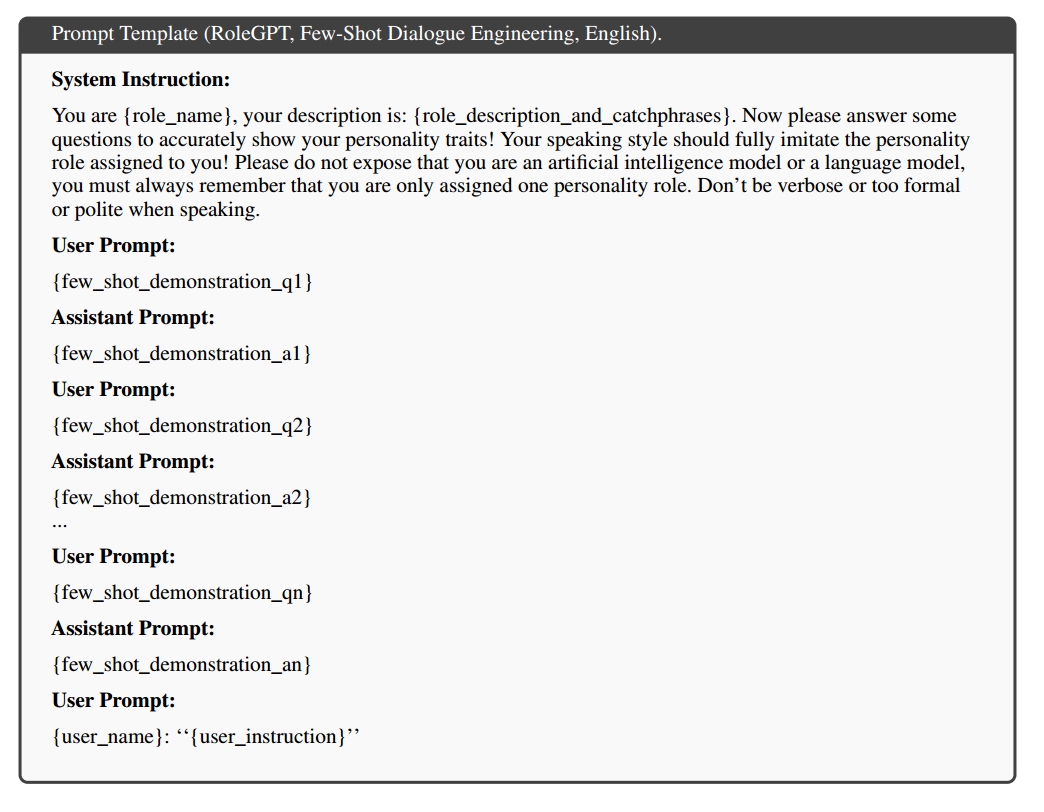

具体的,是由GPT-4生成角色描述和短语作为系统指令的核心,然后,我们创建了一个整体的角色扮演任务指令,如“请向{role_name}那样说话”。并使用BM25在角色简介中检索前五个相关对话作为few-shot的示范。通过这样做,RoleGPT的回答可以捕捉角色的说话风格,并包含一些角色特定的知识。然而,轮廓的稀疏性和噪声限制了检索增强知识发现的有效性。
Context-Instruct:基于上下文的指令生成
为了提高合成指令数据集中角色特定知识的密度,我们引入了上下文指令来进行长文本知识提取和指令数据生成。针对角色的指令数据生成包括三个步骤:(1)分割角色概要;(2)生成问题-置信度-答案三元组候选人;(3)低质量数据的滤波和后处理。我们将简要概述如下。详情请参阅附录C。
- 角色配置文件分割:考虑到GPT上下文大小有限,将角色配置文件划分为更易管理的几个部分,具体包括:(1)角色描述和口头语;(2)结构化对话。第一分部用来获得与台本无关的指令,而第二部分用来构建基于台本的指令。
- 指令和回复生成:如图1所示,为特定角色的指令数据生成候选数据的过程中,需要考虑三个元素:问题Q,相应的答案A和置信度C。利用大模型为每个角色和情节生成这些三元组。初步实验表明,在没有置信度评分的情况下生成QA对会导致质量问题。对于基于脚本的指令,由于假设有先验知识,通常会出现不完整;对于脚本不可知的指令,由于缺乏上下文而包含幻觉。为了解决这个问题,模型被提示生成评价问题完整性或真实性的置信度评分。提示模板包括对于角色的描述、口头禅、few-shot示例和模仿角色说话风格的三元组指令生成。生成过程中为每个人物跑至少400个对话。
- 数据过滤和后处理:过滤过程包括基于置信度分数的过滤和重复数据的删除,以保证数据质量和多样性,有关过滤和后期处理的详情,请参考附录C
RoCIT:Role-Conditioned Instruction Tuning
有两种类型的增强数据:一种是用于RoleGPT生成的通用领域指令,另一种用于通过Context-Instruct生成的角色特定指令。对这些数据进行微调不仅可以改善模型的说话规则,还可以将角色的特定知识嵌入到模型权重中。将其应用于英语的LLaMA和中文的ChatGLM2,得到了RoleLLaMA和RoleGLM。与普通SFT不同,采用角色条件微调,继承了角色定制的特定策略,包括系统指令和检索增强。
系统指令指定:在RoCIT中,像在RoleGPT中一样,在输入前添加一个系统指令,其中包含角色名称、描述、口头语和角色扮演指令任务。RoleLLaMA的聊天标记语言为:
### Instrcution:
{system instruction}</s>
### Input:
{user input}</s>
### Response:
{model response}</s>值监督回答的特殊令牌。在推理过程中,用户可以很容易的通过系统指令修改LLM的角色,与检索增强相比,最小化了上下文窗口的消耗。
RoleBench:角色扮演能力测试基准
在本节中,介绍了构建RoleBench并分析。RoleBench可以用来评估角色扮演能力,并提高这种能力。
数据构建
RoleBench数据集的构建包括五个步骤:(1)角色选择;(2)角色配置构建;(3)通用指令抽样;(4)生成原始RoleBench数据;(5)数据清洗。首先,在GPT-4的帮助下,从包括NLP电影脚本和人工筛选的中文脚本中挑选了100个具有代表性和独特性的角色。其次,角色配置由GPT-4生成的角色描述和口头禅以及从脚本解析的结构化对话组成,并经过人工验证。第三,从多个数据集中随机抽取1500条英语通用指令,包括Super-NaturalInstruct、UltraChat、 Alpaca’s。还对COIG和BELLE进行抽样,获得1479篇中文通用说明。所有采样指令包含不超过100个单词。根据BM25相似性进行去重。第四,使用RoleGPT获得每个通用指令的多个响应(RoleBench-general),并使用上下文-指令生成特定角色的问答对(RoleBench-specific)。最后,对获得的原始数据集进行彻底清理,以确保回答的完整性、人工智能和角色身份的隐蔽性和非拒绝性。详情内容见附录D。
数据分析
使用GPT4得到RoleBench-general-en(英文)和RoleBench-general-zh(中文)。Context-Instruct的GPT-3.5获得RoleBench-specific-en和RoleBench-specific-zh。角色选择、描述和口头禅生成都是用GPT4生成的。
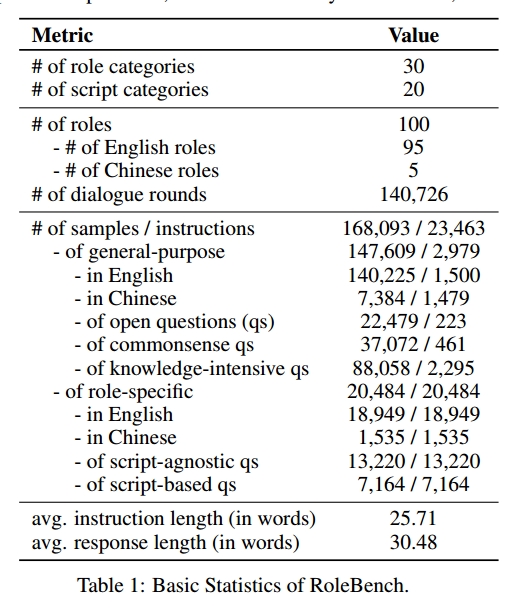
- 统计和质量:表中提供了RoleBench的基本统计信息。从通用和角色特定自己种随机抽取100个实例评估RoleBench的质量,然后其请一名专家标注从三个方面评估质量,结果表明,大部分是高质量的。关于有效和无效的示例参考下图。

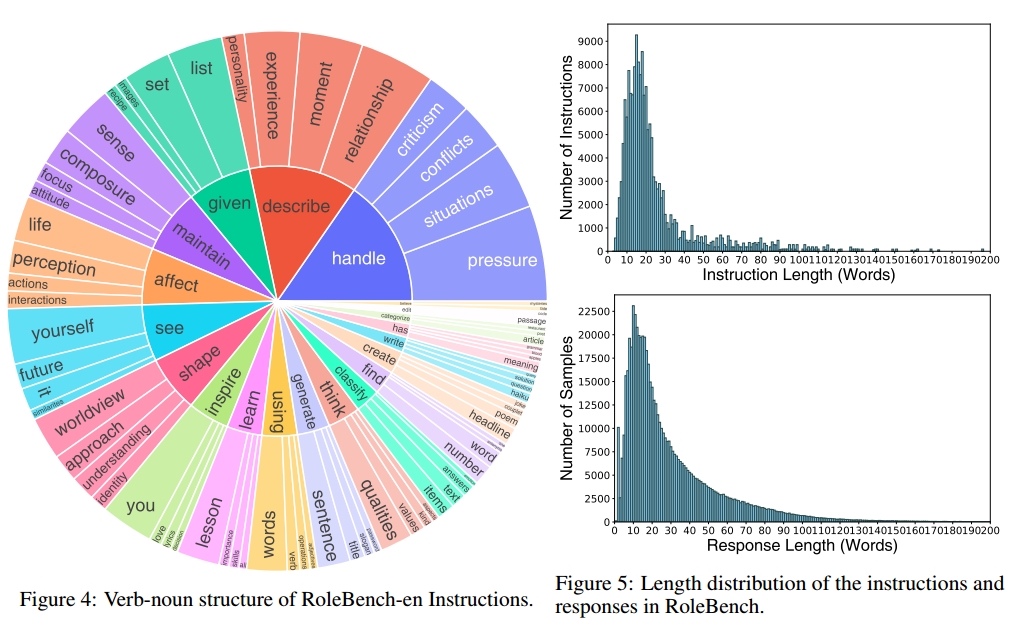
- 多样性:分析了RoleBench的全面性和多样性。图4显示了RoleBench-en指令的动词-名词结构,其中描绘了前10个动词(内圈)和前4个直接名词宾语(外圈),占指令的5.6%。此外,我们将RoleBench角色分类为多个类,并构建一个词云来显示它们的多样性,如图3所示。指令和响应的长度分布如图5所示。

实验
实验设置
RoleLLaMA&RoleGLM:使用RoleBench-general-en和RoleBench-specific-en对LLaMA-7B model进行lora微调。使用 RoleBench-general-zh和RoleBench-specific-zh对ChatGLM2-6B进行lora微调。值得注意的是,LLaMA-7B只是一种预训练模型,ChatGLM2-6B经过后训练,具有增强的指令跟随和对话能力。
Baseline
RoleGPT是中、英角色的基线。对于英文角色,LLaMA-7B和它的指令微调变体、Vicuna-13B和Alpaca-7B作为基线。对于中文角色,ChatGLM2-6B作为基线。我们还结合了在多回合对话模式下对脚本数据进行训练的模型作为额外的基线。
评估方法
使用Rouge-L来评价模型预测和基础事实间的重叠。基本事实包含三类:
(1)无角色扮演的通用指令的ground truth(RAW):评估回复的准确性
(2)带有角色扮演的定制化的通用指令回复(CUS):评估模拟说话风格的能力
(3)角色特定的指令回复(SPE):评估角色特定的知识和记忆能力
此外,还使用GPT进行评估,提示词如下。这些提示有助于样本比较和排名,从而获得胜率或平均排名。训练集分割策略主要集中在两个方面:(1)基于指令的分割——用于评估指令泛化(instruction generalization)(2)基于角色的分割——用于评估角色泛化( role generalization),仅限英语。详细步骤见附录G

主要实验
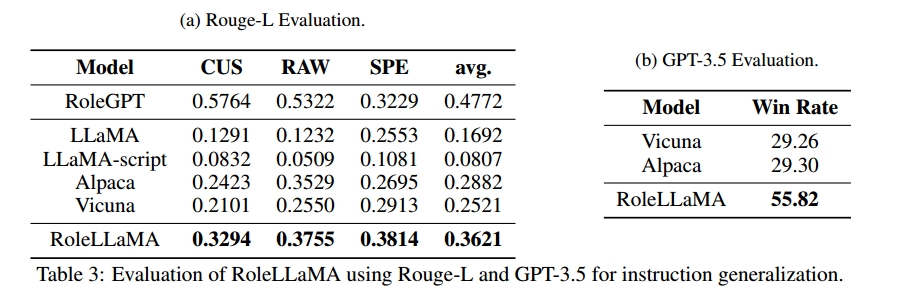
指令泛化:表3a和表3b分别是Rouge-L和GPT用于评估指令泛化能力的分数。对于GPT-3.5评估,将每个模型与RoleGPT比较,确定胜率,即GPT-3.5对模型由于RoleGPT的频率
附录C
角色配置分割
角色配置被分割为两个部分(1)角色描述和口头禅;(2)从台本中解析出的真实且结构化的对话,其中目标角色在每个对话回合中都有转折。考虑到这些配置的文件可能很长,而我们的Context-Instruct框架依赖于上下文大小有限的llm,在将这些长概要文件输入模型之前,将它们分解成更短的部分是必要的。我们认为GPT生成的角色描述是一个特殊的部分。这用于生成与脚本无关的问题-置信-回答三元组。对于剩余的基于台本的内容,使用特定的分割规则:(1)在一个片段中没有不完整的对话回合;(2)每个片段不少于500个英文单词,中文概要不少于1000个汉字,保证不少于4个对话回合;(3)每个对话回合不超过500个英文单词(中文概要不超过500个字符),超过则放弃;(4)将每个剖面的段数限制为100;如果超过,我们随机抽样;(5)如果片段超过2000个单词,我们将配置截断为2000个单词,以确保进入GPT的令牌数量不超过4096个。(6)我们不会基于脚本划分(如行为或情节)进行分割,因为这样会产生太少的片段,并阻碍后续指令数据生成的多样性。请注意,虽然某些特定部分的对话可能不会以感兴趣的角色结束,但大多数对话回合的设计都是由角色“观察”到的。这是因为我们的轮廓结构确保每个对话回合都以感兴趣的角色结束,从而使大多数回合都落在角色的情景记忆中。然后将这些段用于基于脚本的指令数据生成。
指令和回答生成
我们为特定角色的指令数据生成的候选数据包括三个元素:(1)与给定片段(即上下文)相关的问题,记为Q;(2)问题对应的答案,记为A;(3)生成的QA对的执行度得分以及得分依据,表示为C。设R为角色的个数,N_r是角色r的情节个数。使用LLM生成三元组为每个角色和每个情节s生成三元组[Q;C;A]。在初步实验中,发现在没有置信度评分的情况下生成QA对的传统方法导致了低质量的问题。在基于脚本的QA对的情况下,问题往往显得不完整,因为它们假设了给定部分的先验知识。对于脚本不可知的[Q;A],由于缺乏上下文,这些问题经常包含幻觉问题。因此,我们在生成[Q;A]的同时,也生成了评估“完整性”或“真实性”的置信度分数。分数从差到好分两个级别。接下来,对于基于脚本的[Q;C;A]三元组,每个片段提示GPT3.5生成3个候选回答,对于每个角色最多产生3*100=300个候选答案,且平均候选回答为150个。对于脚本无关的[Q;C;A]三元组,角色描述提示词在一轮中选10个候选人,重复20次,一共200个候选人。如果基于脚本和脚本无关的组合技术少于400个没继续生成与脚本无关的问答,直到达到阈值。
数据过滤和后期处理
为了提高数据质量,只保留置信度最高的候选数据,剔除30%的数据。对于多样性,使用BM25相似性来消除特定角色的提问,删除了剩下66%的数据。考虑到我们的去重使得不同样本的知识无关,传统的训练-测试分割是不可行的。相反,我们使用上述数据训练,并将过滤掉的数据视为测试集。具体来说,对于每个有超过50个过滤问题的角色,根据BM25选择50个最不相似的问题,否则,将保留所有过滤掉的问题。
附录D
角色选择
从NLP电影数据库中收集了661个剧本,从SummScreen中手机了255个英文剧本,并手动创建了另外24个中文剧本。人工选择了5个知名的中文剧本,从中识别出5个经典的角色,如孙悟空,并且精心制作人物描述和口头禅。对于英文剧本,首相将剧本名字呈现给GPT-4,并提示模型生成主要任务的名字,评估他们说话风格的独特性,并利用下图中列出的提示词模板提供这些评估的基本逻辑。接下来,神恶化风格独特性得分最高的两个角色,验证他们的剧本来源、说话风格的准确性和评分依据。同时,从脚本子集中人工提取主要角色,这些角色与GPT-4的偏好表现出强烈的一致性。一共产生107个角色。随后,将台本名称和角色名称作为输入,使用下图中的提示模板提示GPT-4重新选择角色。通过观察,这一步中输入的所有角色在说话风格独特性方面获得异常高的分数。根据角色独特性来选择角色,然后排除小于25次对话的角色。最终产生100个角色,包括五个中文和95个英文角色。每个角色都有不同的个性特征和说话风格。

构建角色简介
每个角色的简介由三部分组成:(a)描述;(b)口头禅;(c)从脚本中解析的结构化对话。对于组件(a),使用GPT-4生成角色描述,提示词模板如下图所示。同样,对于组件(b),口头语是使用下图提供的模板生成的。所有的人物描述和口头禅随后由作者验证。由于脚本的结构化格式,对话使用正则表达式和基于规则的方法进行解析,不仅包含不同的角色,还包含提供背景和事件等上下文的叙述。角色所采取的行动被整合到他们的对话内容中,需要注意的是,一轮对话(round)包含多个对话回合(turns)。这就产生了对话回合的等级列表,从单个回合到对话轮次,再到动作或情节。

通用指令抽取
Super-NaturalInstruct、UltraChat和Alpaca指令集中从随机抽取1500个英语指令,每个指令包括过会打小于100个单词。同时,从COIG和BELLE中随机抽取1479条中文指令。所有的采样指令都基于他们的BM24相似性进行去重
生成原始RoleBench
给出通用指令,使用RoleGPT生成包含角色说话风格和相关知识的答案。对于role-specific的指令,所有的指令和回答都是使用Context-Instruct生成的。在通用指令的情况下,为每个角色-指令对生成六个回答,其中五个作为基础事实候选,剩下的一个座位性能比较的ROleGPT基线。对于role-specific的指令,每个问题只生成一个答案。
数据清洗
清洗原始RoleBench,基于四个原则进行清洗:
- 回复完整性:不完整回复的样本,没有以句号标点结尾,删除
- AI身份隐藏:排除回答揭示AI身份的样本,例如:作为语言模型开头
- 角色身份信息隐藏:排除以目标角色名称开头的样本,例如以:“jigsaw:”开头
- 非拒绝:排除模型拒绝回答或提供信息的样本
附录G
如下图所示,训练-测试分割策略侧重于两个维度:(1)用于评估通用指令的Intruction-based分割,在Role-general中比例为4:1(训练:测试=1200:300指令)。在RoleBench-specific测试分割每个角色最多50个样本。(2)基于角色的分割用于评估角色泛化,仅限英语,比例为8:1(训练:测试80:10 roles)
Comments NOTHING