
MetaData
- 发表日期:2023年1月13日
- 作者:Namgyu Ho, Laura Schmid, Se-Young Yun
- 发表平台:arXiv
- 论文链接:https://arxiv.org/pdf/2212.10071.pdf
- 项目链接:https://github.com/itsnamgyu/reasoning-teacher
摘要
最近的研究表明,思维链(CoT)提示可以引导大模型,逐步解决复杂的推理任务。然而,基于提示词的CoT方法依赖于参数非常大的模型,如GPT-3 175B,这是很难大规模部署的。
在本文中,使用这些大模型作为推理老师(reasoning teachers),在较小模型中实现复杂推理,并将模型尺寸要求下降几个数量级。文章提出了fine-tune-CoT,这是一个从非常大的在教室模型生成推理样本以微调较小模型的方法。文章在广泛的公共模型和复杂任务上评价提出的方法。结果表明,Fine-tuneCoT在小型模型中实现了大量的推理能力,在许多任务重远远优于基于提示词的baseline,甚至优于教师模型。此外,利用教师模型的能力拓展我们的方法,为每个原始样本生成多个不同的基本推理。使用多样化的推理来丰富微调数据,可以在数据集上大幅度提升性能,即便对于非常小的模型也是如此。我们进行了消融(ablations)和样本研究,以了解学生模型推理能力的表现。
引言
虽然大语言模型已经展示出上下文泛化能力,但是最大的大语言模型也难以处理需要多个推理步骤的复杂任务。为了解决复杂的任务,最近的研究表明,使用思维链(chain-of-thought CoT)的提示词方法,生成一系列中间推理步骤,可以激发大语言模型的推理能力。
然而,基于提示词的CoT推理方法的主要缺点是依赖于超大语言模型,这些模型难以大规模部署。因此,文章努力使更适合大规模部署的小模型能够进行复杂推理。
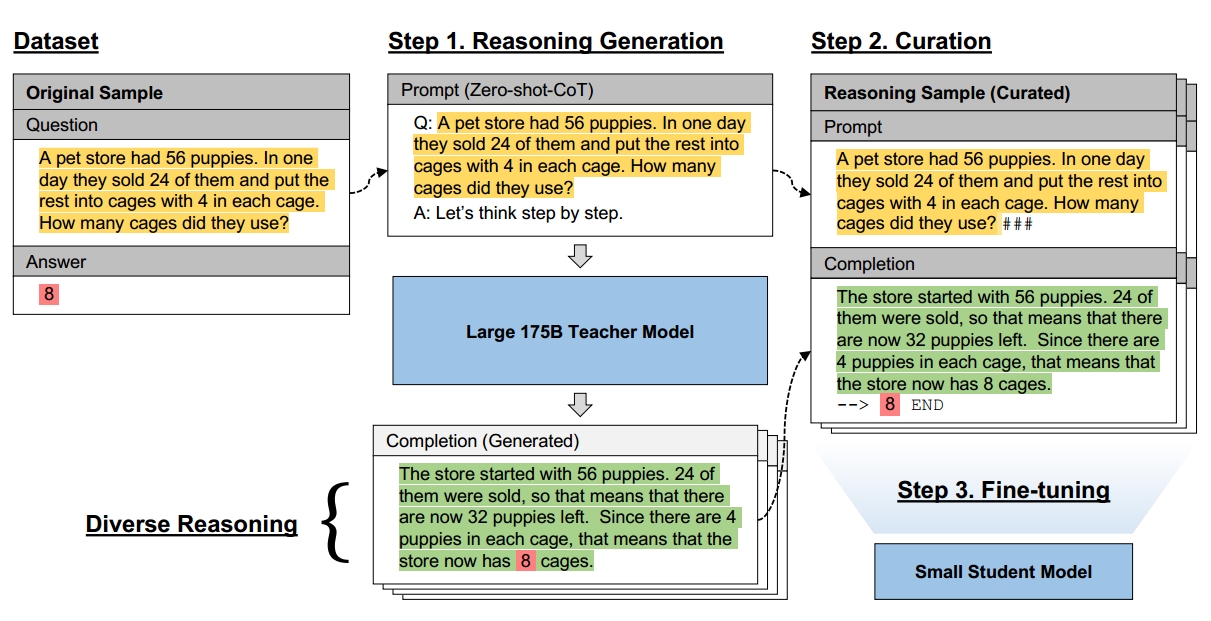
在这种情况下,文章提出了Fine-tune-CoT的方法,利用超大模型的推理能力来教小模型解决复杂任务。应用现有的zero-shot CoT提示词从超大教师模型中生成基本推理,并使用它们对较小的学生模型进行微调,流程如下图所示。作者注意到,没有推理的标准微调已被证明不足以解决小型模型的推理任务。虽然有人尝试用手工标注的推理步骤进行小模型SFT,他们需要特定任务的训练设置和高质量的推理,注释成本很高。相比之下,作者提出的方法可以很容易的应用于新的下游任务,而不需要手工制作推理或者任务工程。
作者还提出了一个新的拓展方法,城为多样化推理(diverse reasoning),以最大限度地提高SFT-CoT的教学效果。直觉上来说,复杂的任务可以具有多个不同推理路径的解决方案,可以使用随机抽样从教师模型中声测会给你多个推理解决方案,以增强学生模型的训练数据。这种方法简单而高效,可以最大限度地提高学生成绩,但在使用CoT推理进行微调的并行工作中,这一点尚未得到明确的认可。
我们使用广泛的公开可用模型在12个任务上评估我们的方法。我们发现Fine-tune-CoT可以在小模型中获得显著的推理性能,同时保留了基于提示的CoT推理的大部分通用性,而以前需要>100B个参数模型(Wei et al, 2022b)。通过利用我们独特的学习设置,多样化的推理可以在开发时以额外的教师推理为代价获得显着的性能收益。这使得小到0.3B的模型在某些任务中表现优于较大的学生,甚至超过175B的教师模型。我们的消融表明,性能在所有考虑的轴上都是一致的可扩展:不同的推理、数据集大小、教师表现和学生模型大小。这显示了我们的方法在小型模型中实现可靠性能的潜力,这些模型在实际应用中是可行的。最后,我们进行了彻底的样本研究和分析,揭示了以前在CoT微调中忽略的关键细节,并提供了小模型中推理能力出现的直觉。
相关工作
- 语言模型中的下游迁移:之前的许多工作建立预训练和微调范式,用于提高LLM在下游任务的性能。然而,微调并不总是容易被接受的。最近的文献显示出一种范式砖面,即提示模型预测期望输出。LLMs在这种情况下表现出强大性能。对于能够执行类似操作的小型模型,通常需要额外的工程。对于更复杂的任务,使用带有明确推理步骤的样本来微调模型的想法先于思维链(CoT)提示方法,在非常大的LLMs中能够表现良好。
- CoT推理:在few-shot的CoT提示词中,模型得到逐步推理的案例后,学会生成问题解决方案的中间推理步骤。这在各种任务上都有很好地表现。此外,llm可以在无监督的任务中使用Zero-shot-CoT获得良好的表现。这不需要进行微调或者设置特定的任务条件,在大量的任务重结果大大由于标准的zero-shot learning,有时候甚至优于few-shot learning。然而,先前的工作表明,CoT需要在非常大的模型上才能获得最佳性嗯呢。在此篇工作中,我们使用超大模型生成的推理结果对小模型进行微调。作者提供了一套丰富的结果以及定性/定量分析的数据集。
- 知识蒸馏(Knowledge distillation):通常情况下,知识蒸馏(Knowledge distillation KD)是指训练从大模型衍生的小模型,以减小模型尺寸和层数,同时仍然保持准确性和泛化能力。本质上,KD是一种模型压缩形式,使得有效部署到容量有限的设备上成为可能。作者提出的方法也可以认为是KD的变体,类似与改进依据提示的方法的工作,或致力于无数据蒸馏,其中迁移数据是由一个大型教师模型综合生成的。但在作者的方法中,教师模型的作用是教授中间推理的概念。具体的输出不是推理的主要监督信号,而是生成的结构。因此,我们不使用反映试图匹配教师输出的标准KD损失函数。
CoT SFT
我们提出了微调- cot,这是一种任务不可知(task-agnostic)的方法,可以在小型LMs中实现思维链推理。其核心思想是使用CoT提示从非常大的教师模型中生成推理样本,然后使用生成的样本对小的学生模型进行微调。这种方法保留了基于提示的CoT方法的通用性,同时克服了它们对过于庞大的模型的依赖。为了最大限度地提高通用性和最小化教师推理成本,我们在教师模型上使用了任务不可知的Zero-shot-CoT提示方法(Kojima等人,2022),因为它不需要任何推理示例或长推理上下文。我们将在7.3节中讨论我们对教师CoT提示方法的选择。在下面,我们用三个不同的步骤来描述Fine-tune-CoT。我们还在图2中提供了一个可视化的概述。
- 步骤1:推理生成:首先使用大型教师模型为给定任务生成CoT推理解释。考虑一个问题q_i和它的答案a_i组成的标准样本S_i。使用Zero-shot-CoT方法让教师模型生成一个推理解释\hat{r_i}来解决问题q_i并且给出最终的答案预测\hat{a_i}。最终生成的文本序列按照如下格式组织:Q:<q_i>. A:Let’s think step by step.<\hat{r_i}>. Threrefor, the answer is <\hat{a_i}>.
- 步骤2: 格式化: 接下来,过滤生成的示例并将它们重新格式化为提示完成对(prompt-completion)。对于过滤,简单的将教师模型的最终预测\hat{a_i}与真实答案a_i比较。注意,这个过滤环节可能会导致一些训练样本的损失。对于所有\hat{a_i}=a_i的实例,将(S_i,\hat{r_i},\hat{a_i})打包成一个推理样本S_i^'=(p_i,c_i),即一个提示补全对(prompt-completion pair)。为了最大化推理效率,使用基于特殊字符的分隔符来最小化token的使用。具体来说:p_i和c_i分别采用“<q_i>###”和“<\hat{r_i}>--><a_i>END”。注意到,基于答案的过滤并不能保障功能推理的正确性,特别对于选择题,该细节有待进一步的分析。
- 步骤3:微调:最后,使用组装的推理样本微调一个小的预训练学生模型。使用与预训练期间相同的训练目标,即自回归语言建模目标,或与测下一个令牌。
- 多样化推理;为了使Fine-tune-CoT的教学效果最大化,可以为每个训练样本生成多种推理解释。这种方法的动机是直觉,即可以使用多种推理方法来解决复杂的任务看,即第二类型任务(type-2 tasks)。我们假设,复杂任务的独特特征与教师模型的随机生成能力相结合,可以通过多样化的推理显著推理监督。具体的来说。对于给定样本S_i,我们采用随机采样策略,即高温度(large T)采样,而不是使用贪心解码的zero-shot-CoT来获得单个解释-答案对(\hat{e_i},\hat{a_i}),用来获得D个不同的生成结果{(\hat{r_{ij}},\hat{a_{i,j}})}_j^D。随后进行推理结果过滤,然后微调。D被称为推理多样性程度。
实验
- 任务和数据集:作者在涉及四类复杂推理的12个数据集上评估了所提的方法,包括算术(SingleEq, AddSub, MultiArith,GSM8K, SVAMP)、其他(Date Understanding, Tracking Shuffled Objects)、符号(Last Letter Concatenation, Coin Flip)和同样场景推理。
- 模型:对于教师模型,使用OpenAI提供的GPT-3 175B的四个变体。除非另有说明,使用基于InstructGPT 175B的text-davinci-002作为Finetune-CoT的教师。对于学生模型,使用了四种流行的模型家族。对于主要时间,使用GPT-3,以为他们很容易通过OpenAI API进行微调。由于API的黑箱性质,我们还考虑在受控设置下的各种开源模型。分别使用GPT-2{small,medium,large}和T5-{small,medium,large}作为仅解码器和编码器-解码器架构的代表性模型家族。
- 基线方法:将Fine-tune-CoT和四种基线方法进行比较:standard zero-shot prompting,vanilla fine-tuning,Zero-shot-CoT和Few-shotCoT。给定一个训练样本{(q_i,a_i)}_i,使用一个简单的格式“Q<q_i>”来进行zero-shot prompting。对于vanilla fine-tuning,将提示词和答案格式化为“<q_i>###”和“<a_i>END”.对于教师的多样化推理,采用T=0.7的温度抽样,附录A中提供了实验细节。
Comments NOTHING