
摘要
基于大型语言模型的角色扮演聊天机器人引起了人们的兴趣,但需要更好的技术来模仿特定的虚构人物。我们提出了一种算法,通过从脚本中提取字符的改进提示和记忆来控制语言模型。我们构建了ChatHaruhi,这是一个包含32个中文/英文电视/动漫角色的数据集,其中包含超过54k个模拟对话。自动和人工评估都表明,我们的方法在基线上提高了角色扮演能力。代码和数据可在https://github.com/LC1332/ChatHaruhi-Suzumiya上获得。
Introduction
角色扮演是一个新颖且活跃的大模型应用领域。出现了共享prompt的社区,如AIPRM等。许多公司发布了基于语言模型的角色扮演产品,如Glow、Character.AI等。
在开源的角色扮演项目中,开发人员可以使用类似的提示使ChatGPT进行角色扮演:
I want you to act like {character} from {series}. I want you to respond and answer like {character} using the tone, manner and vocabulary {character} would use. Do not write any explanations. Only answer like {character}. You must know all of the knowledge of {character}. My first sentence is "Hi {character}."
然而,这种实现方式存在以下缺点:
- 严重依赖语言模型的现有记忆,如果语言模型自己对作品的记忆是模糊的,就不能很好地模仿特定任务。
- Prompt "know all of the knowledge of {character}"的定义是模糊的,并不能很好地处理模型幻觉(hallucinations)问题。
- 即使有使用提示词,聊天机器人的会话风格仍然受到底层语言模型的严重影响。调整提示可能会缓解这种情况,但需要为每个字符微调提示。这些缺点明显限制了这种角色扮演聊天机器人的效用。
另一个简单的方法是根据角色对话对模型进行微调。有了足够的数据,语言模型就可以捕捉到角色的语气。然而,这也造成了新的问题。在初步实验中,经过微调的聊天机器人产生了更多的幻觉。此外,对于许多配角,很难获得足够的数据进行微调。综上所述,使用大模型进行角色扮演仍然是一个未解决的问题。
这个项目的主要目标是研究自然语言模型是否可以在对话中扮演动漫、电视或其他作品中的真实角色。在这个过程中,我们认为虚拟角色由三个核心部分组成:
- 角色知识(Knowledge)和背景设定(background):每个虚拟角色都有自己的背景,如《哈利波特》中的人物存在于魔法世界,春日宫凉存在于日本的一所高中等。因此,在构建聊天机器人时,我们希望它能够理解相应故事的设置。这对语言模型的记忆构成了重大考验,通常需要外部知识库。
- 人物个性:个性:角色的个性也是动漫、电视甚至游戏作品中非常重要的一部分。个性必须在整个工作过程中保持一致。有些文学作品甚至在写其余部分之前先定义了人格。因此,我们希望聊天机器人能反映出原始的个性。
- 语言习惯:语言习惯是语言模型最容易模仿的。在近年来的大型模型中,在给定适当的上下文示例的情况下,语言模型可以产生模仿输出。
这个项目的关键思想是提取尽可能多的原始台本,为角色构建记忆数据库。当用户提出新的问题时,系统会搜索相关的经典情节。结合角色设置提示,通过控制语言模型来更好地模仿角色。同时,受到CAMEL和Baize的启发,我们设计了一个系统,可以自动生成符合角色个性的对话,即使角色的原始对话较少。这允许我们生成足够的数据来微调局部模型。
本文的主要贡献如下:
- 基于大型语言模型,我们提出了一个完整的角色扮演算法系统。该算法可以有效地组织角色的记忆,允许语言模型在对话中模仿特定动漫/电视角色的语气和知识。该系统可以使用ChatGPT和Claude等预训练模型,也可以使用较小的7b尺寸模型。
- 我们构建了一个包含32个不同的中/英电视/动漫角色的角色扮演数据集。通过从电影、小说、剧本中收集和结构化地提取对话,我们收集了超过22000个对话交流。这些数据可以用来训练和评估角色扮演语言模型。使用我们提出的算法,在GPT-3和GPT-4的辅助下,我们还为这些角色模拟了31,000多个对话。这就形成了ChatHaruhi-54k数据集。
- 为了评估和比较不同的角色扮演聊天机器人,我们使用自动和人工评估。对于自动评估,我们测试聊天机器人是否能够对经典情节点做出与原始脚本相似的回答。对于人类的评估,我们提出了两个指标供评分者评估:一致性:聊天机器人的答案是否与角色的原始设置一致。响应质量:聊天机器人的响应是否具有良好的语言质量。结果表明,在给定相同的基本语言模型的情况下,我们的算法可以提高角色扮演的性能。
全部的研究代码和数据被保存在:https://github.com/LC1332/ChatHaruhi-Suzumiya
相关工作
上下文学习(In-context Learning):在工作中,上下文学习主要用于为聊天机器人生成用户问题。给定角色的背景和先前的记忆,我们的方法产生后续对话,以回应上下文中的每个问题。与一般的会话代理相比,我们的系统专注于根据给定的设置和历史为特定的角色定制对话。生成的问答对为分析和学习基于角色的代理的行为提供了有价值的数据。
自动对话生成:我们的工作类似地利用像ChatGPT这样的大型会话模型来自动生成代理之间的对话。然而,与之前的工作不同的是,我们专注于为用户想要扮演的特定角色生成对话。我们的系统整合了大量关于角色背景、个性和之前对话的提示,以便产生角色内部对话。生成的交换为学习特定角色的行为提供了有价值的数据。
聊天机器人设计
给定一个特定的角色R和一个查询问题q,我们希望能够根据角色的知识背景、个性和语言习惯生成答案a:
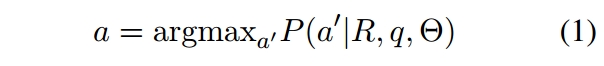
其中\Theta表示语言模型的参数。这些参数在推理期间是静态的。用户可以使用确定的提示词是s_R='I want you to
act like character from series..',因此:
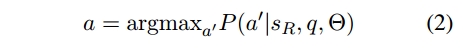
这表明语言模型具有一定的角色扮演能力。然而,角色的记忆完全依赖于参数\Theta。如果模型的知识有限,甚至不包含期望的字符R,则往往无法达到理想的效果。
受到上下文学习(In-context learning)的启发,除了\Theta和s_R,还可以引入角色之前的对话序列:
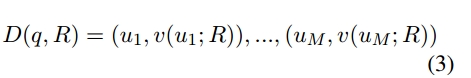
其中\mu_m是由角色R以外的角色提出的任何问题,v(\mu_m;R)是角色R对这些问题的答案。我们希望通过将角色的经典对话输入到上下文中,使模型能够更好地发挥角色R的作用,即:
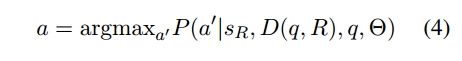
对于具有更大世界观的角色,为了使D(q,R)的内容和查询问题更相关,可以使用句子嵌入(sentence embeddings)从更大的记忆库U检索M个最相关的问答问题。U是小说/电影中其他角色与R互动的所有句子的集合。
当然,在训练中,需要额外记录对话历史H,以确保对话的连续性,因为还需要考虑之前的上下文对话。
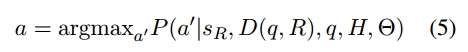
聊天机器人的整体结构如下图所示。之后的章节有对系统提示词s_R,故事中的经典对话D和检索机制\mu_m(q)的详细介绍。

系统提示词
使用ChatGPT作为基模型时,上述prompt已经可以实现基本功能,但仍有两个方面需要改进:
- 不会重复台词:由于ChatGPT和LLaMA2经常面临“给我m个不同的选项”、“生成m个标题”等任务,因此这些语言模型的输出往往不会重复上下文中的内容。因此,我们提出的方法是在提示s_R中强调模型是在cosplay一个特定的角色。并强调语言模型可以重用小说或电影中的经典台词。
- 人物强调不够突出:由于RLHF,每种语言模型都有自己特定的语言偏好。即使给定D(q,R)来模仿,模型的输出仍然受到语言模型本身的影响。我们发现在s_R结尾补充角色的个性会产生更好的效果。
基于以上两点,常用的提示词模板为:我要你扮演{系列}中的{角色}。
如果其他人的问题与小说有关,请尽量重复使用小说中的原台词。
我希望你能像{字符}那样用{字符}的语气、方式和词汇来回应和回答。
你必须知道所有关于{字符}的知识。
{人物性格的补充说明}
注意,我们加强了对语言模型重用故事中的句子的要求。我们发现语言模型的最终输出对补充解释的影响非常敏感。包括在补充解释中加入一些verbal tics也会在最终的输出中体现出来。
每个角色的对话
为了更好地再现小说/电视剧/电影中人物的行为,我们在d中加入了大量的经典剧本节选。这里需要指出的是,除了少数人物(如相声演员于谦),并非所有的对话都是很好的问答形式。在这里,我们实际使用的D是故事形式,如图所示,即:
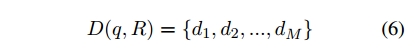
确保在d_m中至少有一个(/mu_m,v(/mu_m;R))。在u和v的信息间,可能有旁白、其角色的对话或一个角色的动作信息。
原始对话搜索
在训练时,一个角色R的所有token数量往往超出语言模型的承受范围,这里使用搜索的方法减少每次输入的原始对话数量。
对于每个问题q,使用一个sentence embedding模型f()来提取f(d)从d\inD。在类似的为查询q提取f(q),从D中提取与f(q)最接近的M个样本(使用余弦相似度),这样就形成了这个对话的参考上下文D(q,R)。
对于每个对话引用的原始对话摘录的数量M,实际上会根据搜索的token数动态调整。在具体实现中,如果使用OpenAI的turbo-3.5模型,我们会将D中的令牌总数限制在1500个以内。
在构建对话记忆时,建议每个故事的长度不要太长,以免在搜索时占用其他故事空间。
对于embedding model,使用text-embedding-ada-002 model。对于中文问题,使用Luotuo-Bert-Medium。后者是前者的蒸馏模型。
聊天内存
对于内存H,记录每个用户的查询q和机器人的响应a,形成一个内存序列H:
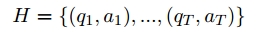
内存H的信息也会被输入到语言模型,保证会话的连贯性。在实际使用中,从T开始向前计算令牌总数,将语言模型的对话历史输入限制在1200个token内。
角色数据集构建
在该项目中,需要与角色R相关的经典故事D(q,R)作为生成涉及该角色的对话输入。因此,需要更多的数据集训练本地模型,而不仅仅是原始对话||D||。
人物
在项目的当前版本,选择32个人物组成数据集。
…………
对话合成
给定角色的系统提示词s_R和对应的经典动画D(q,R),角色能够以一定风格回答用户问题q。利用ChatGPT或者Claude APIs建模a|s_R,D(q,R),q。
如果想把ChatHaruhi的功能转移到一个本地模型上,需要建立一个合适的(R,q,a)数据集。在本节中,讨论如何使用有限的数据为角色增加对话数据。
从问题中生成对话
收集到的D不是严格(q,a)格式。因此不能简单地微调语言模型来学习全部的{D_R}数据。为了解决这个问题,对于任意一个d \in D_R,将主角R出现之前的全部对话都当作q,希望将这个问题q作为第一个问题q_1生成对话。
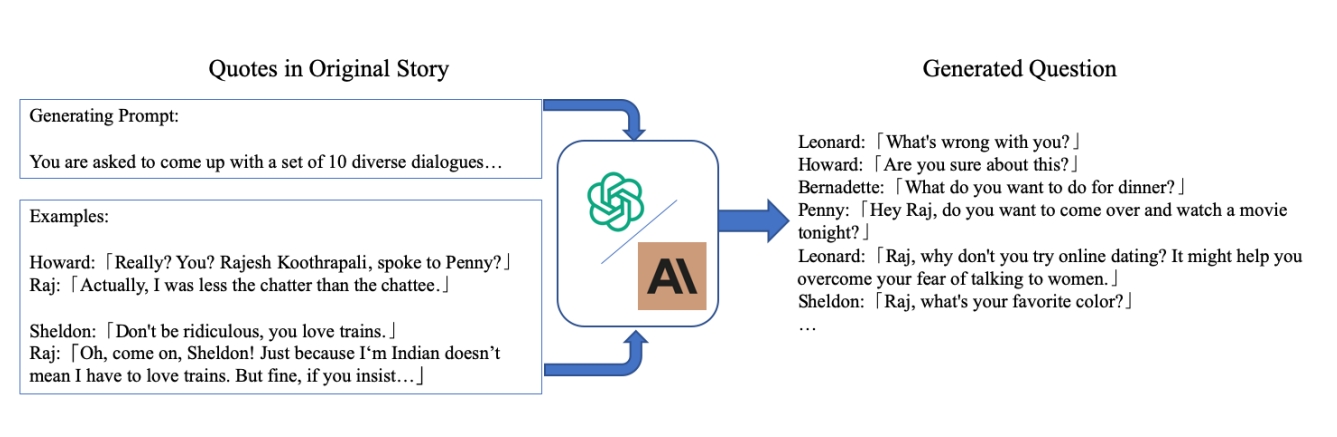
问题生成
由于部分角色可获得的数据很少,不足以实现对语言模型的微调。所以通过问题q扩充已有数据。论文使用了与https://github.com/tatsu-lab/stanford_alpaca 类似的prompt。
当使用类似Alpace的增强方法时,需要提供一个清晰的(q,a)对,在此基础上模型生成大约10个启发式的输出。只保留q_s,然后利用上述技术在角色的ChatBot中重新生成训练对话。混合使用ChatGPT、GPT4和Claude生成问题,后两者生成的问题与角色相关度更高,但是成本也更高。
一共收集了22752个原始对话(D_r),并为ChatHaruhi-v1数据集模拟了31974个带有相应对话的问题。注意,每个对话不一定只包含一个QA对。一共手机了54726个对话。
实验
以前的工作通常通过对不同语言模型的对话输出进行两两比较,并使用TrueSkill或者Elo率来分析ChatBot的回答质量。由于需要人工评估,这种方法的成本很高,且存在评估不一致的问题。此外,对于角色扮演而言,仅靠对话质量并不足以进行评估。人类评估英爱分别判断“角色一致性”和“对话质量”。
自动评估度量
由于五个来自原神的角色的对话非常有限且缺乏连续性,只考虑剩余27个角色的模型评估。选择30个故事,其中包含由角色R从他们的经典故事中说出的长对话a,测试一个模型可以不可以对之前的话语q产生合理的回答\hat{a}。使用句子嵌入来评估a和\hat{a}的余弦相似度判断回答合理性。具体的来说,使用OpenAI的多语言嵌入文本模型(Text-Embedding-Ada-002)计算每个角色a和\hat{a}。
用户研究指标
用户研究仍在进行,包含在未来版本中
语言模型调优
使用54k ChatHaruhi数据集对本地语言模型进行SFT。其中大约15k个对话是英语的,其余是中文的。对ChatGLM2-6B模型进行微调,遵循前面进行的s-R-D-H-q格式,以a作为GPT损失计算的目标,得到三个模型:
- 模型A:对22752个原始对话进行微调
- 模型B:在完整的原始和仿真的54K数据集进行微调
- 模型C:对原始角色的一段话进行微调,而不是聊天机器人生成的对话。
定性结果分析
文章定性的比较了五种模型:
- 只输入提示词s_R的GPT Turbo 3.5
- 输入完整提示词s-R-D-H-q的 Turbo 3.5
- 只输入提示词s_R的ChatGLM2
- 输入完整提示词的ChatGLM2
- 使用ChatHaruhi数据集和完整提示词微调的ChatGLM2
ChatGPT等基座模型通过经典的对话和提示词的优化,可以有效的采用特定任务的说话风格。微调7B模型也有助于内化完整的提示。
定量实验
定量实验仍在进行中
用户研究
用户研究仍在进行中
总结与展望
由于我们尝试的第一个角色是形象鲜明的住宫春日,因此我们将项目命名为ChatHaruhi,并将数据集命名为Haruhi- 54k。
在此报告中,我们发布了在23K原始转录本上训练的模型A和在完整54K数据集上训练的模型B,在HuggingFace上的演示,以及完整的ChatHaruhi-54K数据集。
在未来的迭代中,我们将改进ChatHaruhi接口,使其更易于重用(参见附录A的ChatHaruhi 2.0草案),并补充定量评估。
Comments NOTHING