
背景
ChatGPT和InstructGPT是一对孪生兄弟,它们在模型结构和训练方式上都完全一致,核心思想在于使用指示学习(Instruction Learning)和人工反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)来指导模型的训练。InstructGPT与GPT-3的结构相同,区别在于引入了人工反馈的强化学习RLHF进行微调。在作者的提示分布的人工评估中,尽管参数少了100倍,但来自13b参数的InstructGPT模型的输出比来自175B参数的GPT-3的输出更受欢迎。
InstructGPT论文的阅读地址为:https://arxiv.org/abs/2203.02155
流程简介
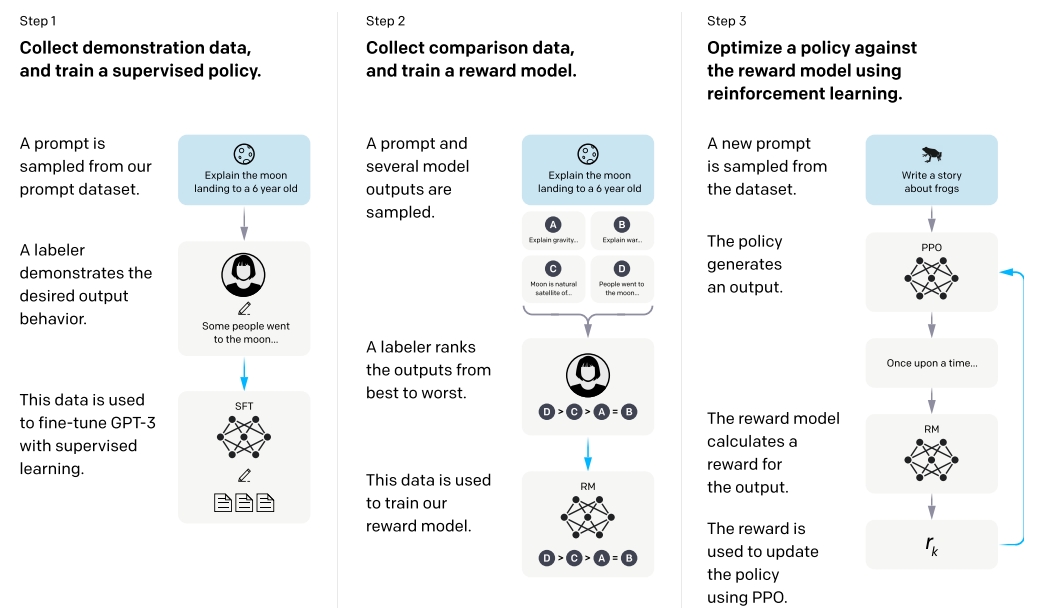
InctructGPT主要使用来自人类反馈的强化学习(利用人类的偏好作为奖励信号),对GPT-3进行微调。具体的实现步骤概括如下:
- 收集示范数据,训练有监督策略。雇佣40个外包标注数据,根据prompts,人工撰写一系列demonstration(演示)作为模型的期望输出。使用这部分数据集对预训练的GPT-3进行监督微调(监督学习基线)。
- 收集比较数据,训练奖励模型。上述模型产生一系列输出,标注者(labelers)对这些输出进行比较和排序(由好到坏)。基于这些数据集,训练一个奖励模型(Reward Model),用于预测标注者更喜欢哪一个输出。
- 使用PPO针对奖励模型优化策略。使用第二步的RM作为奖励函数,微调第一步的监督学习baseline,使用PPO算法最大化奖励。
步骤2和步骤3可以连续迭代。在当前最佳策略上,收集更多的比较数据,用来训练RM模型和新策略。在实践中,大多数比较数据源于监督策略,部分来自于PPO策略。
需要注意的是,这些不中将会把GPT3的行为与部分特定人群(标注者和研究者)的偏好进行对齐,仅能代表这些人的偏好,而不是“人类”偏好。
方法和实验细节
数据集
prompt数据集最初由提交给OpenAI API的文本提示组成。使用Playround的用户会被告知,只要使用InstructGPT模型,这些数据就会被收集起来,以进行进一步的模型训练。
对收集到的prompt做后处理,包括:
- 检查长公有前缀prompt,消除重复prompt;
- 限制每个用户ID的prompts数量为200;
- 基于用户ID创建训练集、验证集和测试集,以便验证集和测试集中不包含训练集的数据。
- 对数据进行脱敏处理,避免模型学习到潜在的敏感客户细节
在训练最早的IntructGPT时,labelers自己撰写prompts,具体包含三种:
- 简单(Plain):要求labeler自己提出任意的任务,同时确保任务具有多样性。
- 少样本(Few-shot),要求labelers给出一条指令,同时给出这条指令对应的多个查询/响应对。
- 基于用户(User-based):要求labelers给出OpenAI API应用案例对应的prompts
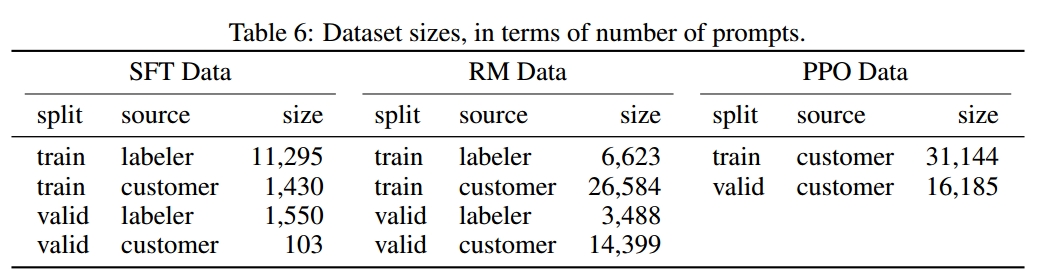
依据这些提示,IntructGPT生成了用于微调过程的是三个不同的数据集:
- SFT dataset:由labelers标注的例子,用于训练SFT model,包含13k个训练prompts(来源于API和人工撰写)
- RM dataset:由labelers对模型输出结果的排序对数据,用于训练Reward Model,包含33k个训练prompts(来源于API和人工撰写)
- PPO dataset:无人工标签,用于作为RLHF fine-tuning 的输入数据,包含31k个训练prompts(仅来源于API)。
模型训练
Intruct GPT从GPT-3预训练语言模型开始。这些模型是在广泛分布的互联网数据上进行训练的,可以适应广泛的下游任务,但行为特征不佳。从这些模型开始,我们用三种不同的技术训练模型:
Supervised fine-tuning (SFT)
使用有监督学习对GPT-3进行微调。文章共训练了16个epoch,使用余弦学习衰减率,residual dropout为0.2。文章根据验证集上的RM分数进行最终的SFT模型选择。
Reward modeling (RM)
RM是将SFT模型最后的嵌入层去掉后的模型,它的输入是prompt和response,输出是标量的奖励值。RM一般是在同一输入的两个模型输出之间的比较数据集上训练的,使用交叉熵loss和奖励的差异作为label。在文章中,仅使用6B的RM模型,一方面节省了大量计算消耗,另一方面175B的RM训练不稳定,不太适合作为强化学习的值函数。
具体来说,对于每个prompt,InstructGPT会随机生成K个输出(4 <= K <= 9)。labeler对这些输出进行排序,每个prompt的输出可以产生C_k^2个pair对,当K = 9时,会产生36个pair对。在训练过程中,InstructGPT将每个prompt的C_k^2个pair对作为一个单独的batch。这种按照prompt作为batch的训练方式,比传统的按照样本作为batch的计算方式高效得多(只需要计算一次RM的前向传递),且不容易过拟合,因为这种方式下,每个prompt仅会喂给模型一次。
奖励模型的损失函数使用的是排序中常见的pairwise ranking loss:
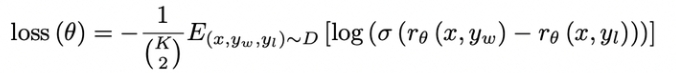
其中:r_{\theta}(x,y)表示在promptx和响应y在参数为\theta的奖励模型下的奖励值。在{y_w,y_l}的pair对下,y_w表示labeler更喜欢的响应结果。目标函数就是最大化这两个奖励的差值,这个差值经过一个Sigmoid函数和log函数再取负后,得到损失
Reinforcement learning(RL)
文章使用PPO算法对SFT模型进行微调。InstructGPT中的RL环境是bandit environment,提供随机用户的prompt并期望对提示做出响应。给定提示和反应,他会产生由RM决定的奖励,并且结束当前episode.
在RL训练过程中,最大化组合目标函数如下:
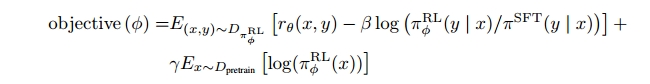
其中,\pi_\Theta^{RL}表示待学习的RL策略(最开始由 \pi^{SFT}初始化),\pi^{SFT}是在标注好的问题和答案基础上,用有监督微调训练出的模型(step1),D_{pretrain}表示预训练分布。
对目标函数进行进一步的拆解和分析:
- x表示PPO数据集,包含31000个prompt(训练过程中一直固定)。对于每一个prompt,未入当前的RL策略,产生y(每一次通过随机梯度下降更新模型后,y总会发生变化),然后把(x,y)丢进上一步训练好的RM模型中,计算出分数。最大化r_\theta(x,y)。目标:新训练模型生成的回复总是人类觉得最好的那个答案。强化学习并非简单的统计学习,它的数据分布会随着模型的更新而不断变化(环境发生变化)。r_\theta(x,y)其实就是学习人的排序,从而给模型实时的反馈。
- 随着模型的更新,RL产生的输出和SFT模型的数据分布差异会越来越大。通过在loss中添加KL散度(评估两个概率分布的相似度),以期RL(PPO)产生的输出与SFT模型输出不要偏离太远。该项相当于一个正则项
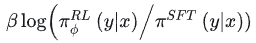
- 如果只使用上述两项进行训练,会导致该模型仅仅对人类的排序结果较好,而在通用NLP任务上,性能可能会大幅下降。文章中通过在loss中加入GPT-3的预训练语言模型目标来规避这一问题。加入该项后,InstructGPT指代的就是PPO-ptx模型。PPO-ptx就是PPO的目标函数 + 原始GPT-3的目标函数。
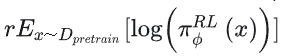
评估
文章中的评估(helpful,honest and harmless)分为两个部分:
- 评估API分布
- 评估公共NLP数据集。包含两种类型,一是能够捕捉语言模型安全性的数据集,比如真实性、毒性和偏见等;二是传统NLP数据集在zero-shot上的表现,比如问答、阅读理解和摘要等。
讨论
对齐
作者提出,本文使用的“对齐”技术——RLHF,是用于对齐人类系统的一个重要方法。
与预训练相比,增加模型对齐的成本是适中的。收集和训练上文提到的几万条prompt数据,与训练GPT-3的花费相比,只占一小部分。而且上述结果也表明,RLHF在使语言模型更加helpful方面非常有效,甚至比模型增加100倍更有效。所以,在自然语言领域,研究alignment可能比训练更大规模的模型更具性价比。
局限性
1、方法。InstructGPT的表现在一定程度上取决于从外包人员那里获得的反馈。有些标注任务可能会受到标注者价值观(身份、信仰、文化背景和个人经历等)的影响。由40个人组成的标注群体,显然无法代表模型的所有受众。
2、模型。InstructGPT无法做到完全align和完全安全。模型仍然会在没有明确prompting的情况下,输出一些有毒/有偏见的内容、编造事实,甚至产生性和暴力内容。模型可能也无法针对某些输入产生合理的输出。作者认为,InstructGPT模型的最大缺点是,在大多数情况下,尽管会对现实世界造成伤害,它仍然会遵循用户的指令。例如,当输入一个有偏见的prompt指令时,InstructGPT会产生比GPT-3模型毒性更多的输出结果。
Comments NOTHING