
基本概念
AB测试的理论基础是假设检验。在两个随机均匀的样本组A、B中,对其中一个组A做出某种改动,实验结束后分析两组用户行为数据,通过显著性检验,判断这个改动对于我们所关注的核心指标是否有显著的影响,这个工过程就被称为AB测试。
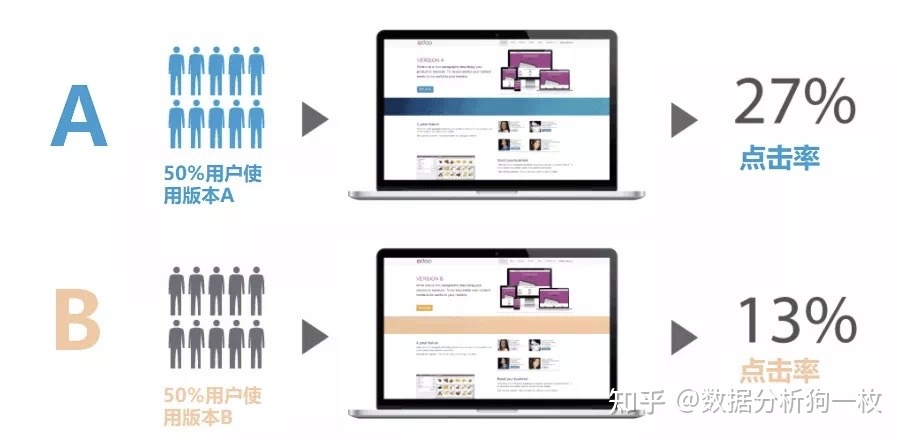
在上图示例的AB实验中,假设检验如下:
原假设H0:这项改动不会对核心指标有显著的影响
备选假设H1:这项改动会对核心指标有显著的影响
实验完成时,如果显著性检验的P值足够小,则推翻原假设,证明该改动会对核心指标产生显著影响;否则拒绝原假设,证明该改动未产生显著影响。用一句话概括:AB测试其实就是随机均匀样本组的对照实验。
AB测试的一般流程
- 在实验开始前,和产品或项目经理去认定实验需要验证的改动点;
- 设计实验中需要观测的核心指标,如点击率、转化率等;
- 计算实验所需的最小样本流量,实验样本越大,结果越可信,但对用户的不良影响越大,所以需要计算能够显著证明策略有效的最小样本量;
- 结合目前的DAU,计算实验持续时间;
- 设计流量分割策略,根据实验需要对样本流量进行分流分层,保证样本的随机和均匀分布,避免辛普森悖论。
- 确认开始实验,在正式实验前,进行小流量灰度实验,防止改动造成极端影响;
- 发布正式实验,等到实验周期结束后,对实验结果进行显著性检验。
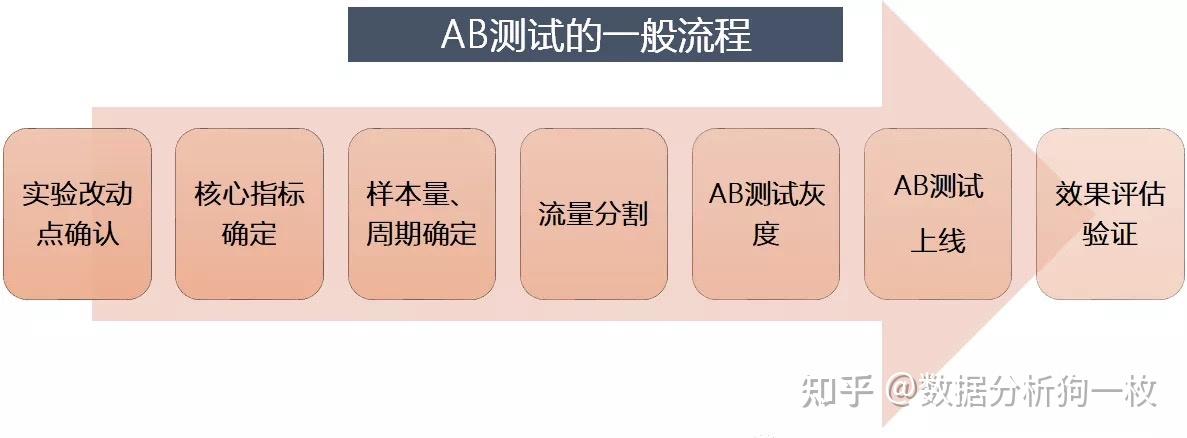
AB Test的流程同样可以总结如下:
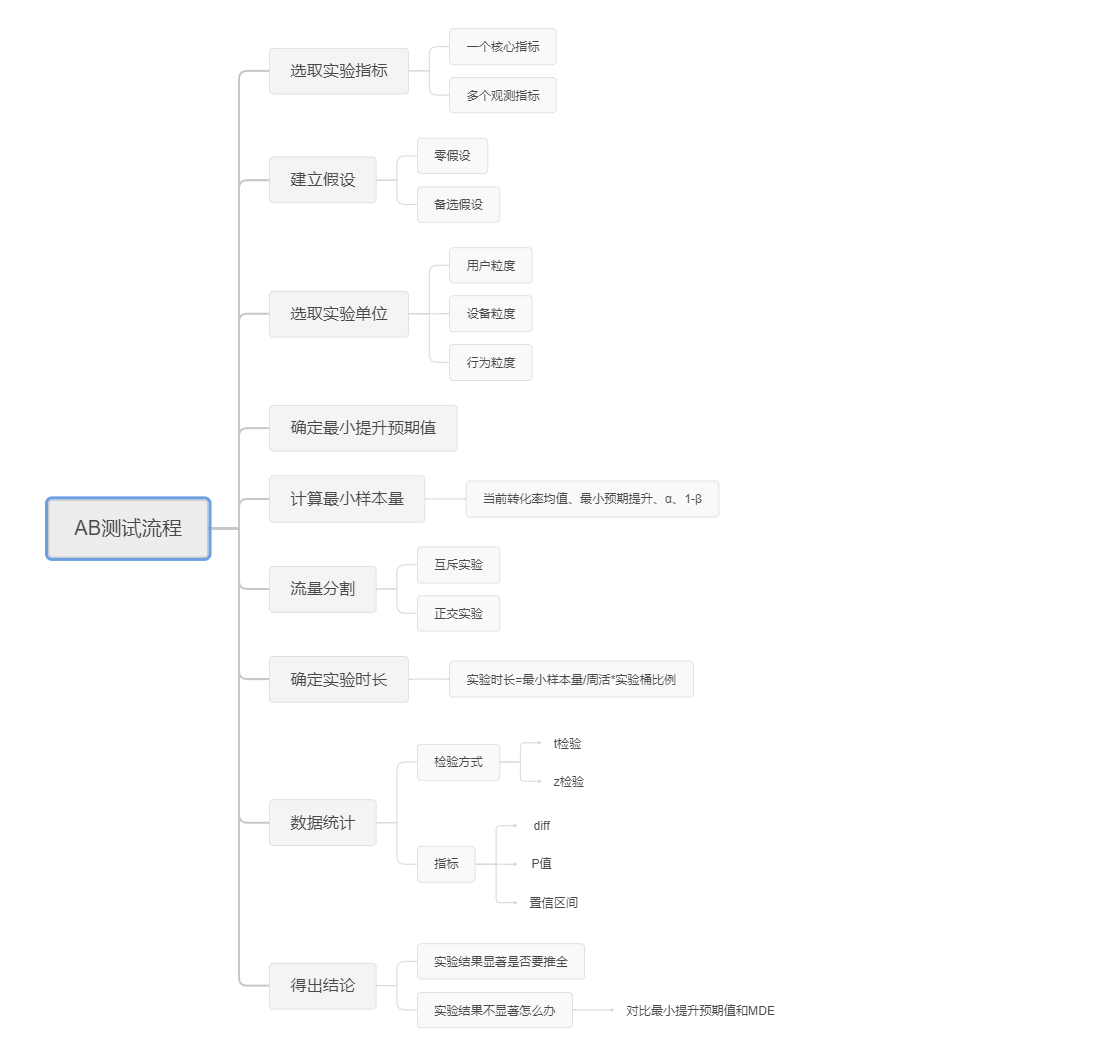
明确改动点和观测指标
明确改动点
在实验开始前,首先要确定AB实验的变量,AB测试应当遵守“单一因素原则”,一个实验只能有一个核心指标,但可以有多个观测指标。
核心指标是用于判断该实验是否显著,观测指标用于判断该实验对其余指标的影响。另外,可以设反向指标,以观测该实验是否会带来一些负面影响。
明确观测指标
观测指标可以分为两种类型:
- 绝对值类指标:直接计算能够得到的单个指标,一般统计该指标在一段时间内的均值或者汇总值,常见的绝对值类指标包括:
DAU,平均停留时长等,这类指标一般较少作为AB测试的观测指标。 - 比率类指标:通过多个绝对值指标计算获得,如:
点击率,转化率,复购率等等。
建立假设实验
针对实验要提升的核心指标,我们可以做出不同的假设,如何修改可能会提升指标。
然后就是建立零假设和备择假设:
一般零假设是没有效果
备择假设是有效果。
选取实验单位
一般来说,可以从三个粒度选取实验单位,即:用户粒度,设备粒度,行为粒度。
- 用户粒度:最推荐的粒度,以一个用户的唯一标识来作为实验样本。符合AB测试的分桶单位唯一性,不会造成一个实验单位处于两个分桶,造成的数据不置信。
- 设备粒度:以一个设备标识为实验单位。相比用户粒度,如果一个用户有两个手机,可能出现一个用户在两个分桶中的情况,所以会造成数据不置信的情况。
- 行为粒度:以一次行为为实验单位,也就是用户某一次使用该功能,是实验桶,下一次使用可能就被切换为基线桶。会造成大量的用户处于不同的分桶。强烈不推荐这种方式。
确定最小提升预期值
做实验需要考虑ROI。如果开发成本很高,但是最终的提升只有0.01%,可能这个实验的收益提升并不能抵挡付出的成本。所以在实验之初需要考虑成本问题,即这个实验提升了多少算作是符合我们的预期。
计算试验所需最小样本量
该步骤是要避免流量浪费,高效利用流量,把可用流量分到其他试验。另外还要避免在统计功效不足的情况下给出错误结论。即避免实验过程种,流量使用过多或者过少的情况。
A/B 测试样本量的选取基于大数定律和中心极限定理。在计算样本量之前,对大数定律和中心极限定理进行概述:
- 大数定律:当试验条件不变时,随机试验重复多次以后,随机时间的频率近似等于随机事件的概率;
- 中心极限定理:对独立同分布且有相同期望和方差的n个随机变量,当样本量很大时,样本的均值近似服从标准正态分布N(0,1)
计算最小样本量的公式如下:
$$N=\frac{2*(Z_{1-\alpha}+Z_{1-\beta})^2*\sigma^2}{\delta^2}$$
其中\alpha和\beta分别是一类错误(拒真)和二类错误(取伪)的概率,通常取值为0.05和0.2。
上述公式还可以简化为:
$$N\approx\frac{16*\sigma^2}{\delta^2}$$
其中\delta为两组数据均值之差,即希望检测到的最小变化
\sigma为各组样本标准差。
可以使用Evans awesome AB Tools进行在线计算:https://www.evanmiller.org/ab-testing/sample-size.html
eg:假设当前转化率为50,希望最小预期提升10%,即从50%提升到55%,预估需要1600左右的样本量

确定实验时长
试验时长的影响因素如下:
- 最小样本量
- 可接受的实验桶的比例大小
- 周活
实验时长=最小样本量/周活*实验桶比例
此外,还需要考虑一些业务情况,如用户可能在工作日和周末特征/行为不一样,所以最少跑够7天;用户一开始可能觉得新奇所以转化率高,后续转化率才会趋于真实。
数据统计
通常来说,绝对值指标推荐使用T检验,相对指标推荐使用Z检验
- 在已知总体标准差的情况下,使用Z检验;在未知总体标准差的情况下,使用t检验。
- t检验基于t分布,而Z检验基于正态分布,随着样本量的增加,t分布逐渐接近正态分布
- 在样本量较小(通常小于30)且总体分布近似正态时,t检验比Z检验更为适用。
- 在样本量较大时,t检验和Z检验的结果通常是非常接近的。
需要统计的结果包括:diff、p值、置信区间
P值
P值代表当零假设成立时,观测到样本数据出现的概率。统计学上,将5%作为一个小概率事件,所以一般用5%来对比计算出来的P值。当P值小于5%时,拒绝零假设,即两组指标不同;反过来,当P值大于5%时,接受零假设,两组指标相同。
置信区间
一般情况下,我们都会用95%来作为置信水平。也就是说,当前数据的估计,有95%的区间包含了总体参数的真值。这么说可能比较绕,我们可以简单理解成 总体数据有95%的可能性在这个范围内。
我们计算两组指标的差异值,如果我们算出的差异值置信区间不含0,我们就拒绝零假设,认为两组指标不同;但是如果包含0,我们则要接受零假设,认为两组指标相同。
置信区间的计算公式如下:
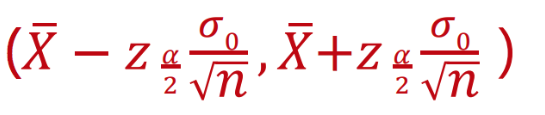
得出结论
实验结果显著是否要推全?
-
是否达到最⼩样本量,以及实验运⾏到计算的实验周期之后再去校验显著性。(例如跑了一天,结果为显著提升,但是其实实验的样本量没有达到最小样本量,那就还要接着跑一跑)
-
除了核⼼指标,还需要考虑平台的红线指标(例如核心指标显著提升,但是对其他指标有负面作用,那要考虑全局再决定)
实验结果不显著怎么办?
看MDE最⼩检测效应(实验能够统计的最⼩差异粒度)
需要看当前的mde是否⾜够⼩:
如果⼤于我们的最⼩提升预期值,则说明ab试验的灵敏度不够,可以延⻓试验时间,让更多的样本量进来
如果⼩于我们的最⼩提升预期值,那么说明实验组就是不显著,⽴刻停⽌试验 mde计算公式

Comments NOTHING