
冒泡排序(Bubble Sort)
算法原理
冒泡排序的算法原理是比较相邻的元素,如果前一个比后一个大,就把他们两个位置对调;对排序数组中的每一对相邻元素做同样工作,直到全部完成。此时最后的元素将会是本轮最大的元素;对剩下元素进行重复操作,直至没有任何一个元素需要比较。
算法代码
#冒泡排序
def bubble_sort(li):
n=len(li)
for i in range(0,n-1):
is_exchanged=Fasle
for j in range(0,n-i-1):
if li[j]>li[j+1]:
li[j],li[j+1]=li[j+1],li[j]
is_exchanged=True
if is_exchenged=Fasle:
break
return li
复杂度分析
- 时间复杂度:O(n^2)
- 空间复杂度: O(1)
- 算法稳定性:稳定
选择排序
算法思路
- 一趟排序记录最小的数,放到第一个位置;
- 再一趟排序记录记录列表无序区最小的数,放到第二个位置;
- 重复该思路;
- 算法关键点:有序区和无序区、无序区最小数的位置。
算法代码
def select_sort(li):
for i in range(len(li)-1):
min_loc=i
for j in range(i+1,len(li)):
if li[j]<li[min_loc]:
min_loc=j
li[i],li[min_loc]=li[min_loc],li[i]
return li复杂度分析
- 时间复杂度:O(n^2)
- 空间复杂度:O(1)
插入排序
算法思路
- 将待排序列表的第一个元素当做已排列元素,第二个元素到最后一个元素当成未排列序列;
- 取未排序序列中第一个数据,插入到已排序序列中顺序正确的位置。将未排序的第一个数据与相邻的前一个数据(已排序序列的最后一个数据)进行比较,如果顺序错误则交换位置,交换位置后继续与相邻的前一个数据进行比较,直到不需要交换则插入完成。每次插入数据后,已排序序列都是排好序的;
- 重复上一步,继续插入下一个数据。每进行一次插入,已排序序列长度加1,未排序序列的长度减1,直到列表中所有数据都插入到已排序序列,则列表排序完成。
算法代码
def insert_sort(li):
for i in range(1,len(li)):
tmp=li[i]
j=i-1
while j>=0 and tmp<li[j]:
li[j+1]=li[j]
j=j-1
li[j+1]=tmp复杂度分析
- 时间复杂度:O(n^2)
- 空间复杂度:O(1)
快速排序
算法思路
- 从要排序的数中选出一个数作为
pivot(轴),也就是前后两部分的分界点(可以选第一个数或者最后一个数或者正中间的数或者随机数,但有些选法在某些情况下可能会出现问题); - 把整个数列分成两部分:
(小于等于pivot的),(大于等于pivot的),即遍历一遍整个数列,把小于等于pivot的数全部放到pivot的左边,把大于等于pivot的数全部放到pivot的右边(数列中会存在一些和pivot相等的数,这些数分到左边或者右边都无所谓,可以只分到某一边也可以两边都分); - 对左右两边再使用快速排序进行排序,得到
(小于等于pivot且有序),(大于等于pivot且有序),这样整列书就有序了。
算法代码
def quick_sort(li,start,end):
if start>end:
return li
left=start
right=end
#定义基准pivot
pivot=li[start]
while left<right:
#从后向前扫描
while left<right and li[right]>pivot:
right-=1
li[left]=li[right]
#从前向后扫描
while left<right and li[left]<pivot:
left+=1
li[right]=li[left]
li[right]=pivot
#分段排序
quick_sort(li,start,left-1)
quick_sort(li,left+1,end)
return li复杂度分析
- 时间复杂度:O(nlogn)
- 空间复杂度:O(n)
堆排序
基本概念
- 堆:一种特殊的完全二叉树结构
- 大根堆:一棵完全二叉树,满足任一节点都比其孩子节点大
- 小根堆:一棵完全二叉树,满足任意节点都比其孩子节点小
算法思想
- 建立堆;
- 得到堆顶元素,为最大元素;
- 去掉堆顶,将堆最后一个元素放到堆顶,此时可以通过一次调整重新使堆有序;
- 堆顶元素为第二大元素;
- 重复步骤3,直到堆变空
算法代码
def sift(data,low,high):
i=low
#j为左孩子
j=2*i+1
tmp=data[i]
while j<=high:
#如果左孩子小于右孩子
if j<high and data[j]<data[j+1]:
j+=1
#如果父节点的值小于子节点
if tmp<data[j]:
#将父节点的值赋值给子节点
data[i]=data[j]
i=j
j=2*i+1
else:
break
data[i]=tmp
def heap_sort(data):
n=len(data)
for i in range(n//2-1,-1,-1):
sift(data,i,n-1)
for i in range(n-1,-1,-1):
data[0],data[i]=data[i],data[0]
sift(data,0,i-1)topk问题
解决思路:
- 取列表前k个元素建立一个小根堆,堆顶就是目前第k大的数;
- 依次向后遍历原列表,对于列表中的元素,如果小于堆顶,则忽略该元素;如果大于堆顶,则将堆顶更换为该元素,并且对堆进行一次调整;
- 遍历列表所有元素后,倒序弹出堆顶
复杂度分析
- 时间复杂度:O(nlogn)
- 空间复杂度:O(1)
归并排序
算法思路
归并排序是用分支思想,分治模式在每一层递归上有三个步骤:
- 分解(Divide):将n个元素分成含n/2个元素的子序列;
- 解决(Conquer):用合并排序法对两个子序列递归的排序;
- 合并(Combine):合并两个已排序的子序列得到排序结果
归并排序可以使用递归的方法进行:- 将序列每相邻的两个数字进行归并操作,形成floor(n/2)个序列,排序后每个序列包含两个元素;
- 将上述序列再次归并,形成floor(n/4)个序列,每个序列包含四个元素;
- 重复步骤2,直到所有元素排序完毕
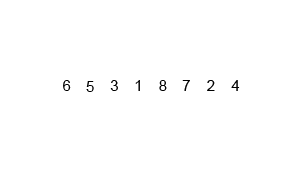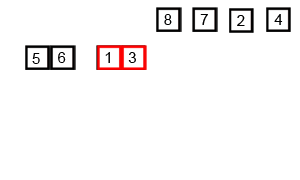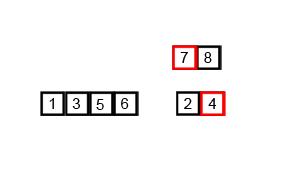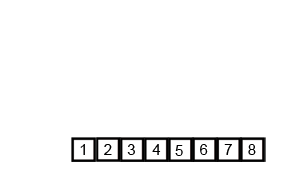
算法代码
def merge(li,low,mid,high):
i=low
j=mid+1
ltmp=[]
while i<=mid and j<=high:
if li[i]<li[j]:
ltmp.append(li[i])
i+=1
else:
ltmp.append(li[j])
j+=1
while i<=mid:
ltmp.append(li[i])
i+=1
while j<=high:
ltmp.append(li[j])
j+=1
li[low:high+1]=ltmp
def mergesort(li,low,high):
if low<high:
mid=(low+high)//2
mergesort(li,low,mid)
mergesort(li,mid+1,high)
merge(li,low,mid,high)
mergesort(li,0,len(li)-1)复杂度分析
- 时间复杂度:O(nlogn)
- 空间复杂度:O(n)
- 算法稳定性:稳定
Comments NOTHING