
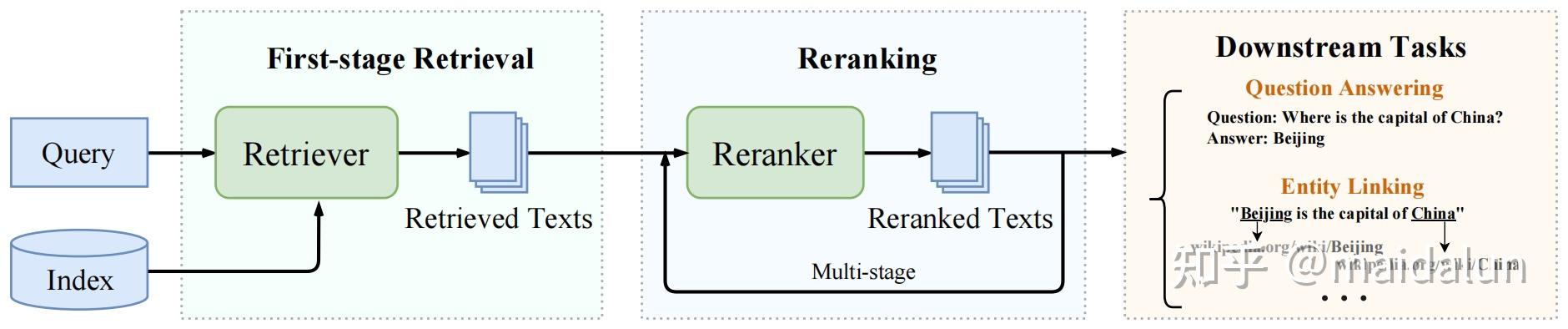
项目形态
- 文件解析环节与知识库绑定,支持在创建知识库时绑定同义词库,从而在知识切片解析时为每个chunk配置关键词过滤信息,减少检索成本,提高检索效率。
- 当前向量化速度300ms,召回速度1s左右,精排速度3s左右。
bce-embedding-base-v1
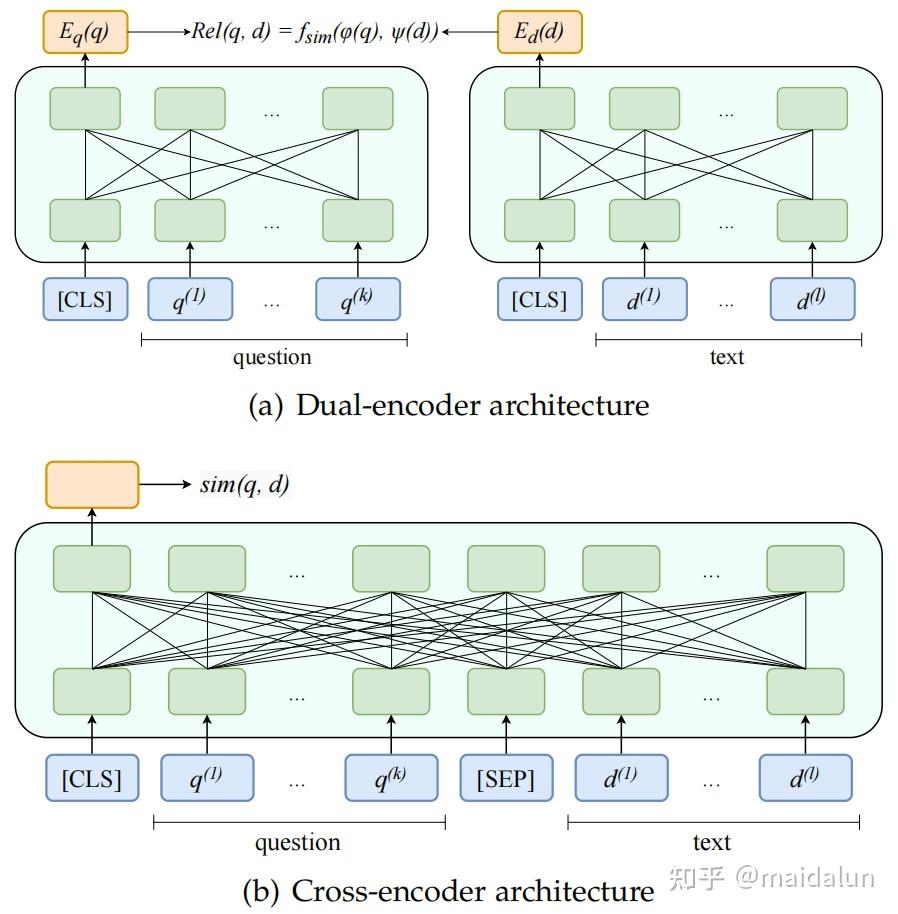
BCEmbedding-base-v1(Bilingual and Crosslingual Embedding, BCEmbedding)是网易有道退出的跨语种语义检索模型,于2024年1月3日发布,主要用于检索增强生成(RAG)任务,是QAnything开源项目的检索基石。该模型的嵌入长度为768,最大输入长度为512token。作为RAG技术线路中最为重要和基础的一环,二阶段检索器一般由召回和精排两个模块组成。
二阶段检索器包含召回和精排两个阶段,能够很好的平衡检索性能和效率。
召回阶段常采用基于向量的密集检索方法,对用户问题和知识库语料进行向量化提取,然后搜索和用户问题语义相近的背景信息。提取语义向量的Embedding模型一般采用dual-encoder的架构,可以离线(offline)对庞大的知识库语料提取语义向量。用户提问时,模型只需要实时的提取用户问题的语义向量,就可以利用向量数据库进行语义检索。在这个过程中,大规模知识库语料的语义向量提取是离线、静态的过程,模型在提取用户问题和知识库语料的语义向量时,没有信息交互。该方式的好处是检索效率非常高,但是这也限制了语义检索性能的上限。
精排阶段是为了解决信息交互的问题,采用cross-encoder架构。Reranker模型可以实现用户问题和知识库语料的信息交互,使模型能够“见机行事”的识别到更加准确的语义关系,算法性能上限可以很高。该方式的缺点是,需要对用户问题和知识库语料进行在线(online)的语义关系提取,效率较低,无法对全量的知识库语料进行实时处理。
结合召回和精排的优势,在召回阶段可以快速找到用户问题相关的文本片段,精排阶段可以将正确的相关片段尽可能排在靠前位置,并过滤掉低质量的片段。二阶段检索可以很好的权衡检索效果和效率,具有巨大的应用价值。
bge-large-zh-v1.5
Bge(BAAI General Embedding)-large-zh-v1.5是由BAAI(Beijing Academy of Artificial Intelligence)开发的中文嵌入模型。嵌入长度为1024,最大输入长度为512。该模型在中文语境下的任务中表现出色,如句子相似度、文本检索和问答系统,具有准确率高、推理速度快、资源消耗低等优势。支持512个token的输入,适用于多语言环境下的文本检索任务。
bge-m3
BGE-M3(Multi-language, Multi-function, Multi-granularity(多语言、多功能、多粒度))是智源推出的新一代通用语义向量模型,支持100多种语言,具备高效的多语言检索能力。它能处理不同粒度的文本,嵌入长度为1024维,最大输入长度为8192tokens,集成了多种检索功能,性能优异。
Reranker训练
Qwen3-Rerank
Qwen3-Rerank系类包括0.6B、4B和8B三种类型。对于qwen-reranker,他的输入是【查询-文档】二元组,固定输出为yes/no,因此训练样本的格式类似于:
{
"query":XXX,
"doc":XXX,
"label":yes/no
}其中,正样本为领域内真实相关问答/段落;负样本可以是随机抽取的不相关段落,或者是使用难负样本挖掘策略找到的负样本。正负样本设置1:1左右即可,几千条就能见效。
在实践中,利用markdown语料+原始问答,构建问题-正例-负例样本对。其中负例的获取方法是:
-
首先使用向量召回最难片段,通过faiss-ip搜索做反向搜索,得到最不相关的片段作为候选池
-
从后选片段中进行随机抽取30条,并使用qwen-rerank-8B进行打分,保留30条负例及其重排分数
-
最后得到2w+样本对,从而进行rerank微调或千问rerank微调
知识补充
-
嵌入长度:模型将每个词或Token转换成的向量的维度(即向量长度)。该值决定模型表示词汇语义特征的丰富程度。维度越高,则表达能力越强,但是计算成本也更高。
-
最大输入长度:模型单词能处理的最大Token序列长度(包括文本和特殊标记如[CLS]、[SEP])。受模型的位置编码(Positional Encoding)和内存限制影响。超出部分会被截断或者拒绝。
-
[CLS]:Classification Token,在模型输入的开头插入[CLS],其对应的输出向量被用作整个输入序列的“语义摘要”,尤其用于分类任务(如情感分析、文本匹配、句子分类等)
-
[SEP]:Separator Token,用于分隔两个不同的句子或片段,帮助模型区分他们的边界。常见于句子对任务(问答、自然语言推理、句子相似度)或单句任务,即在句子末尾添加[SEP]表示句子结束。
遗留项
- 召回速度,精排速度
Comments NOTHING