
简介
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术,常用于挖掘文章中的关键词,而且算法简单高效,常被工业用于最开始的文本数据清洗。
TF-IDF由两部分组成,第一部分:TF(Term Frequency)——词频;第二部分:IDF(Inverse Document Frequency)——逆文档频率。当有TF(词频)和逆文档频率(IDF)后,将这两个词相乘,得到一个词的TF-IDF值。某个词在文章中的TF-IDF越大,那么一般而言这个词在文章中的重要性越高,所以通过计算文章中各个词的TF-IDF,由小到大排序,排在最前面的几个词就是该文章的关键词。
TF-IDF算法步骤
- 词频计算与标准化:

- 计算逆文档频率:此时需要一个语料库(corpus)用来模拟语言的使用环境。
content/uploads/2024/03/3.png)
如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。log表示对得到的值取对数。 - 第三步,计算TF-IDF:
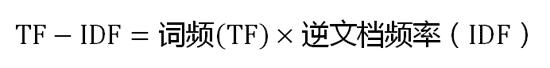
可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。所以,自动提取关键词的算法就是计算出文档中每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。
优缺点
TF-IDF的优点是简单快速,而且容易理解。缺点是有时候用词频来衡量文章中的一个词的重要性不够全面,有时候重要的词出现的可能不够多,而且这种计算无法体现位置信息,无法体现词在上下文的重要性。如果要体现词的上下文结构,那么你可能需要使用word2vec算法来支持。
示例代码
def TF-IDF(path,dic):
tf-idf={}
fold_list=os.listdir(path)
count=0
idf={}
for key in dic.keys():
idf[key] = 1
tf_idf[key] = 0
for fold in fold_list:
file_list=os.listdir(path+'/'+fold)
count+=len(file_list)
for file in file_list:
with open(path+os.sep+fold+os.sep+file) as f:
text=f.read()
for key in dic.keys():
if key in text:
idf[key]+=1
for key,value in idf.items():
idf[key]=log(count/value+1)
for key,value in tf_idf.items():
tf_idf[key]=dic[key]*idf[key]
return tf_idf
Comments NOTHING